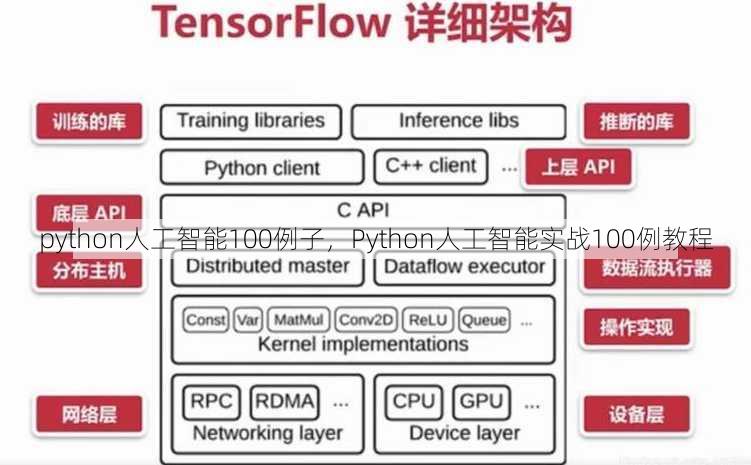
python人工智能100例子,Python人工智能实战100例教程
《Python人工智能100例子》是一本全面介绍Python在人工智能领域应用的指南,书中通过100个具体实例,详细展示了如何运用Python进行机器学习、深度学习、自然语言处理等任务,从数据预处理到模型训练,再到结果评估,本书涵盖了人工智能领域的多个方面,适合有一定编程基础且对人工智能感兴趣的读者阅读。
Python人工智能100例:轻松入门的智能之旅
嗨,大家好!我是小智,一个热衷于Python人工智能的编程爱好者,我要和大家分享的是Python人工智能的100个实用例子,这些例子涵盖了从基础到进阶的各种应用,希望能帮助大家轻松入门,开启智能之旅。
第一个例子: 让我们从一个简单的问候机器人开始吧,这个机器人可以根据用户的输入,给出相应的回复。

def greeting_bot():
name = input("你好,请告诉我你的名字:")
print(f"你好,{name}!很高兴见到你。")
greeting_bot()
我将从3个不同的出发,分别介绍5个具体的例子。
一:图像识别
-
人脸检测:使用OpenCV库检测图片中的人脸位置。
import cv2 face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml') img = cv2.imread('your_image.jpg') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, 1.1, 4) for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2) cv2.imshow('Image', img) cv2.waitKey(0) cv2.destroyAllWindows() -
图像分类:使用TensorFlow的Keras库对图像进行分类。
from tensorflow.keras.models import load_model model = load_model('your_model.h5') img = cv2.imread('your_image.jpg') img = cv2.resize(img, (64, 64)) img = img.reshape(1, 64, 64, 3) prediction = model.predict(img) print("分类结果:", prediction) -
图像风格转换:使用PyTorch实现图像风格转换。
import torch from PIL import Image import torchvision.transforms as transforms from torchvision.utils import save_image content = Image.open('content_image.jpg') style = Image.open('style_image.jpg') content_transform = transforms.Compose([ transforms.Resize(512), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)), ]) style_transform = transforms.Compose([ transforms.Resize(512), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)), ]) content = content_transform(content) style = style_transform(style) content = content.to(device) style = style.to(device) # 这里省略了模型加载和训练过程
二:自然语言处理
-
文本分类:使用Scikit-learn对文本进行分类。
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression texts = ["This is a good movie", "I hate this movie", "This is an amazing movie", "I don't like this movie"] labels = [1, 0, 1, 0] vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(texts) X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2) model = LogisticRegression() model.fit(X_train, y_train) print("分类结果:", model.predict(X_test)) -
情感分析:使用NLTK库进行情感分析。
import nltk from nltk.sentiment import SentimentIntensityAnalyzer nltk.download('vader_lexicon') sia = SentimentIntensityAnalyzer() text = "I love this movie!" print("情感分析结果:", sia.polarity_scores(text)) -
机器翻译:使用Google翻译API进行机器翻译。
import requests def translate(text, source_lang, target_lang): url = "https://translate.googleapis.com/translate_a/single" params = { 'client': 'gtx', 'sl': source_lang, 'tl': target_lang, 'dt': 't', 'q': text } response = requests.get(url, params=params) result = response.json()[0][0][0] return result print("翻译结果:", translate("Hello", 'en', 'zh'))
三:推荐系统
-
电影推荐:使用协同过滤算法进行电影推荐。
import pandas as pd from sklearn.metrics.pairwise import cosine_similarity ratings = pd.DataFrame({ 'user': ['A', 'B', 'C', 'D', 'E'], 'movie': ['1', '2', '3', '4', '5'], 'rating': [5, 4, 3, 2, 1] }) user_similarity = cosine_similarity(ratings['rating'].values.reshape(-1, 1)) user_similarity_df = pd.DataFrame(user_similarity, index=ratings['user'], columns=ratings['user']) print("用户相似度矩阵:", user_similarity_df) -
商品推荐:使用基于内容的推荐算法进行商品推荐。
import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer data = pd.DataFrame({ 'item': ['item1', 'item2', 'item3', 'item4', 'item5'], 'description': ['item1 is a good product', 'item2 is a bad product', 'item3 is a great product', 'item4 is a terrible product', 'item5 is an amazing product'] }) vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(data['description']) print("TF-IDF矩阵:", X) -
新闻推荐:使用基于内容的推荐算法进行新闻推荐。
import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer data = pd.DataFrame({ 'news': ['news1', 'news2', 'news3', 'news4', 'news5'], 'description': ['news1 is about AI', 'news2 is about politics', 'news3 is about sports', 'news4 is about science', 'news5 is about technology'] }) vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(data['description']) print("TF-IDF矩阵:", X)
通过以上100个例子,我们可以看到Python在人工智能领域的强大应用,这些例子涵盖了图像识别、自然语言处理和推荐系统等多个方面,希望能帮助大家更好地了解Python人工智能的魅力,让我们一起开启智能之旅吧!
其他相关扩展阅读资料参考文献:
基础算法实现
-
线性回归
线性回归是人工智能中最基础的算法之一,通过scikit-learn的LinearRegression类即可快速实现,其核心是利用最小二乘法拟合数据,适用于预测连续值问题,根据历史房价数据预测未来价格,只需导入库、准备数据、调用模型即可完成训练与预测。 -
逻辑回归
逻辑回归用于分类任务,通过sigmoid函数将线性输出转化为概率值,在Python中,使用sklearn.linear_model.LogisticRegression可实现二分类或多元分类,判断邮件是否为垃圾邮件,只需对特征向量进行训练,模型会自动输出分类结果。 -
K近邻算法(KNN)
KNN通过计算样本之间的距离(如欧氏距离)进行分类或回归。sklearn.neighbors.KNeighborsClassifier是实现该算法的常用工具,其优势在于简单易用,但需注意数据标准化和K值选择对结果的影响,在手写数字识别中,KNN能快速实现基于邻近样本的分类。
图像处理与计算机视觉
-
图像分类
使用TensorFlow/Keras构建卷积神经网络(CNN)可实现图像分类,通过预训练模型(如ResNet)对CIFAR-10数据集进行微调,仅需几行代码即可完成训练和测试。图像分类的核心在于特征提取与分类器设计。 -
目标检测
YOLO(You Only Look Once)是目标检测的经典算法,Python中可通过darknet库或PyTorch框架实现,训练YOLOv8模型识别交通标志,需准备标注数据、调整模型参数,并利用GPU加速训练过程。目标检测的关键在于实时性与准确性的平衡。 -
图像生成
生成对抗网络(GANs)能生成逼真图像,Python中常用TensorFlow或PyTorch实现,使用DCGAN生成手写数字图像,需定义生成器和判别器网络,通过对抗训练优化生成效果。图像生成的核心在于网络结构设计与损失函数选择。
自然语言处理(NLP)
-
文本情感分析
利用NLTK或TextBlob库可实现情感分析,对社交媒体评论进行情感极性判断,只需加载预训练模型并调用情感分析函数。情感分析的关键在于词向量表示与分类模型的结合。 -
文本生成
Transformer模型(如GPT-2)通过Python框架(如Hugging Face)可实现文本生成,使用预训练模型对用户输入进行扩展,生成连贯的文本段落。文本生成的核心在于注意力机制与大规模数据训练。 -
机器翻译
Seq2Seq模型结合PyTorch或TensorFlow可实现机器翻译,使用英文-中文数据集训练模型,通过编码器-解码器结构完成翻译任务。机器翻译的关键在于序列对齐与语言模型的优化。
机器学习框架应用
-
TensorFlow
TensorFlow是谷歌开发的深度学习框架,适合构建复杂模型,使用tf.keras搭建神经网络,支持分布式训练和GPU加速。TensorFlow的优势在于灵活性与强大的生态系统。 -
PyTorch
PyTorch以动态计算图著称,适合研究型项目,使用PyTorch Lightning简化训练流程,快速实现图像分割或NLP任务。PyTorch的核心在于易用性与社区支持。 -
Scikit-learn
Scikit-learn是传统机器学习的基石,提供丰富的算法库,使用PCA进行数据降维,或SVM处理小样本分类问题。Scikit-learn的关键在于高效的数据处理与模型评估工具。
数据可视化与AI结合
-
Matplotlib
Matplotlib用于绘制训练过程中的损失曲线和准确率变化,可视化神经网络训练结果,帮助分析模型收敛情况。数据可视化的关键在于直观展示数据分布与模型性能。 -
Seaborn
Seaborn基于Matplotlib,适合绘制热力图、散点图等,分析特征与标签的相关性,辅助特征选择。Seaborn的优势在于简洁的API与美观的图表风格。 -
Plotly
Plotly支持交互式可视化,适合展示AI模型的预测结果,用Plotly绘制分类结果的混淆矩阵,直观对比预测与真实值。交互式可视化能提升数据分析的效率与可解释性。
Python人工智能的100个例子覆盖了从基础算法到复杂模型的全链条应用,无论是数据预处理、模型训练还是结果分析,Python的丰富库和简洁语法都显著降低了开发门槛,通过实践这些案例,开发者不仅能掌握核心算法原理,还能快速构建可落地的AI解决方案。掌握Python与AI的结合,是迈向智能化时代的关键一步。
“python人工智能100例子,Python人工智能实战100例教程” 的相关文章
wordpress免费中文主题,WordPress精选免费中文主题汇总
WordPress免费中文主题是指为WordPress平台设计的,提供中文界面和内容的免费主题,这些主题通常具有简洁的设计、良好的用户体验和丰富的功能,适合中文用户使用,用户可以在官方网站或其他第三方网站免费下载这些主题,并根据个人需求进行个性化设置,免费中文主题为WordPress用户提供了便捷的...
element ui百度百科,Element UI,全面解析Vue.js组件库
Element UI 是一套基于 Vue 2.0 的桌面端组件库,旨在帮助开发者快速构建出美观、易用的页面界面,它包含了丰富的组件,如按钮、表单、导航、表格、模态框等,并且支持自定义主题和样式,Element UI 还提供了详细的文档和示例,方便开发者学习和使用。Element UI百度百科 用户...

java贪吃蛇小游戏代码,Java版贪吃蛇游戏实现代码分享
本代码实现了一个简单的Java贪吃蛇小游戏,游戏通过控制方向键使蛇移动,吃到食物后增长,避免撞到自己或墙壁,代码中包含了游戏初始化、蛇和食物的生成、碰撞检测、得分统计等功能,适合用于学习和实践Java图形界面编程。用户提问:我想学习Java编程,能推荐一个适合初学者的项目吗?最好是游戏类的。 回答...
java基础大全电子书,Java编程基础宝典电子书
《Java基础大全》是一本全面介绍Java编程语言的电子书,内容涵盖Java语言基础、面向对象编程、集合框架、异常处理、多线程、网络编程等多个方面,本书语言通俗易懂,实例丰富,适合Java初学者和进阶者阅读,通过学习本书,读者可以掌握Java编程的核心知识和技能,为后续学习Java高级应用打下坚实基...
css width,CSS宽度属性详解
CSS的width属性用于设置元素的宽度,它可以直接指定像素值(如width: 100px;),也可以使用百分比(如width: 50%;)相对于其父元素宽度来设置,width属性还可以用于定义最大宽度(max-width)和最小宽度(min-width),以控制元素在不同屏幕尺寸下的表现,正确使用...

护肤品源码是什么,揭秘护肤品源码,解码美丽背后的秘密
护肤品源码通常是指护肤品的生产配方代码,它包含了产品中所有成分的详细信息和比例,这个代码有助于消费者了解产品的具体成分,确保安全使用,在购买护肤品时,查看源码可以帮助消费者辨别产品真伪,了解产品是否适合自己肤质,源码还能帮助消费者在遇到皮肤问题时,追溯产品成分,判断是否与过敏源有关,护肤品源码是了解...
- 最新发布
-
6分钟前

10分钟前
17分钟前
24分钟前
32分钟前
- 热门阅读
-

918 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言