column函数举例,探索column函数,实用举例解析
column函数在数据处理中常用于提取或创建列,以下是一个简单的例子:,假设有一个数据集,包含姓名、年龄和城市三列,使用column函数,可以创建一个新的列,例如计算每个人的年龄是否超过30岁,以下是Python中Pandas库使用column函数的一个示例代码:,``python,import pandas as pd,# 创建示例数据,data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 35, 40], 'City': ['New York', 'Los Angeles', 'Chicago']},df = pd.DataFrame(data),# 使用column函数创建新列,判断年龄是否超过30,df['Older_than_30'] = df['Age'].apply(lambda x: x > 30),print(df),`,输出结果将显示每个人的年龄,并新增一列Older_than_30`,显示是否超过30岁。
用户提问:嗨,我想了解一下SQL中的column函数有什么具体的应用例子,能给我举几个例子吗?
解答:当然可以,SQL中的column函数是一种非常有用的工具,它可以帮助我们在查询中对单个列进行操作,下面我会从几个不同的来举例说明column函数的应用。
一:聚合函数应用
-
求和:使用
SUM(column_name)可以计算一个列中所有值的总和,如果你有一个销售表,想计算所有销售记录的总销售额,可以这样写: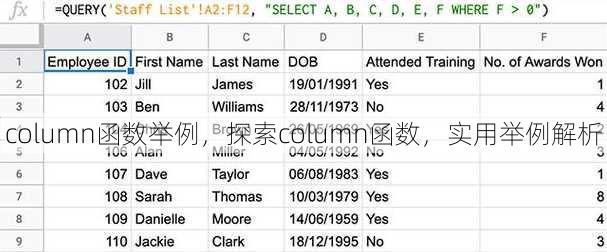
SELECT SUM(sales_amount) AS total_sales FROM sales;
-
平均值:
AVG(column_name)函数用于计算一个列的平均值,计算所有员工工资的平均值:SELECT AVG(salary) AS average_salary FROM employees;
-
最大值和最小值:
MAX(column_name)和MIN(column_name)分别用于找到某个列的最大值和最小值,找出所有订单中金额的最大值:SELECT MAX(order_amount) AS max_order_amount FROM orders;
二:条件函数应用
-
条件求和:
CASE语句可以结合SUM函数进行条件求和,根据订单状态求不同状态订单的总金额:SELECT CASE order_status WHEN 'shipped' THEN SUM(order_amount) WHEN 'delivered' THEN SUM(order_amount) ELSE 0 END AS total_amount FROM orders; -
条件计数:
COUNT(column_name)结合CASE可以用于条件计数,计算所有已发货订单的数量:SELECT COUNT(CASE WHEN order_status = 'shipped' THEN 1 END) AS shipped_orders FROM orders; -
条件分组:
GROUP BY结合CASE可以用于条件分组,根据订单状态分组,并计算每种状态的数量:
SELECT order_status, COUNT(*) AS order_count FROM orders GROUP BY CASE order_status WHEN 'shipped' THEN 'shipped' WHEN 'delivered' THEN 'delivered' ELSE 'other' END;
三:日期和时间函数应用
-
提取日期部分:使用
DATE_PART()函数可以从日期列中提取特定的日期部分,如年、月、日,提取订单日期的年份:SELECT DATE_PART('year', order_date) AS order_year FROM orders; -
计算日期差:
DATEDIFF()函数可以计算两个日期之间的差异,计算订单从创建到发货的日期差:SELECT DATEDIFF(day, order_date, shipped_date) AS days_to_ship FROM orders; -
当前日期和时间:
CURRENT_DATE()和CURRENT_TIME()可以分别获取当前的日期和当前的时间:SELECT CURRENT_DATE AS current_date, CURRENT_TIME AS current_time;
四:字符串函数应用
-
字符串长度:
LENGTH(column_name)或LEN(column_name)可以用来计算字符串的长度,计算用户名的长度:SELECT LENGTH(username) AS username_length FROM users; -
字符串截取:
SUBSTRING(column_name, start, length)可以用来截取字符串的一部分,获取用户名的首字母: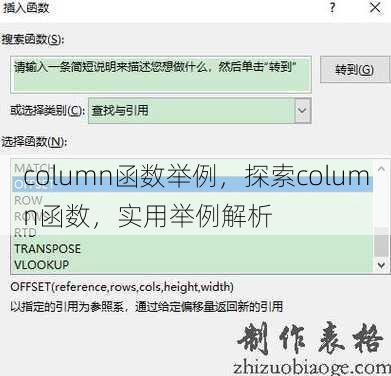
SELECT SUBSTRING(username, 1, 1) AS first_letter FROM users; -
字符串转换:
UPPER(column_name)和LOWER(column_name)可以将字符串转换为大写或小写,统一用户输入的邮箱地址格式:SELECT LOWER(email) AS normalized_email FROM users;
通过这些例子,我们可以看到column函数在SQL查询中的多样性和实用性,无论是进行数据聚合、条件筛选,还是处理日期和时间、字符串数据,column函数都能提供强大的支持。
其他相关扩展阅读资料参考文献:
Excel中column函数的应用
-
返回当前列号
在Excel中,COLUMN函数可直接返回当前单元格所在列的编号,在A1单元格输入=COLUMN(),结果为1;在B1单元格输入相同公式,结果为2,这一功能常用于动态定位列位置,避免手动输入列号导致的错误。 -
配合其他函数生成序列
COLUMN函数可与CHOOSE函数结合,实现跨列的序列生成。=CHOOSE(COLUMN(), "周一", "周二", "周三")会在不同列中返回对应的星期名称,适用于需要横向扩展数据格式的场景。 -
处理多列数据时的组合使用
在数据表中,COLUMN函数可与SUM、PRODUCT等函数联动,实现多列计算。=SUM(COLUMN(A1:A3), COLUMN(B1:B3))会计算A列和B列的列号之和,但实际应用中更常见的是通过数组公式实现多列数据的动态汇总。
Python中pandas库的column操作
-
数据列的提取与访问
在pandas中,通过df[column]可直接访问数据框的某一列。df['销售额']会提取名为“销售额”的列,这一操作是数据分析的基础步骤,能快速定位目标数据。 -
条件筛选与列操作
利用COLUMN函数(或等效操作)可实现对特定列的条件筛选。df[df['销售额'] > 1000]会筛选出销售额大于1000的行,但实际中更常用的是通过布尔索引或apply函数进行复杂条件处理。 -
数据透视与列重组
在数据透视表中,COLUMN函数对应的是列标签的动态生成,使用pivot_table函数时,通过指定columns参数可将多列数据转换为分类汇总表,如pivot_table(data, values='销量', columns='地区')能生成不同地区的销量对比。
数据库查询中的column函数
-
GROUP BY按列分组
在SQL中,GROUP BY子句通过指定列名对数据进行分组。SELECT 地区, SUM(销售额) FROM 销售表 GROUP BY 地区会按地区列汇总数据,这一操作是数据聚合的核心方法。 -
子查询中的列引用
子查询中需通过列名引用外层查询结果。SELECT * FROM 表1 WHERE 表1.列名 = (SELECT MAX(列名) FROM 表2),通过明确列名可避免歧义,确保查询逻辑清晰。 -
聚合函数与列结合使用
聚合函数如AVG、MAX需与列名绑定。SELECT AVG(销售额) FROM 销售表会计算销售额列的平均值,但若未指定列名,数据库可能无法正确识别数据来源。
数据清洗中的column函数应用
-
处理缺失值时的列判断
在数据清洗中,通过检查列中的空值或异常值,可定位需要处理的字段,使用isnull()函数检测某列是否为空,如df['年龄'].isnull().sum()会统计年龄列的缺失值数量。 -
列标准化与格式统一
对列中的数据进行标准化处理,如统一单位或日期格式。df['价格'].apply(lambda x: x / 100)可将价格列的数值转换为元单位,避免数据不一致影响分析。 -
去重与列唯一性校验
通过检查列中的重复值,可确保数据准确性。df['订单号'].duplicated().sum()会统计订单号列的重复记录数量,帮助识别数据冗余问题。
数据可视化中的column函数关联
-
行列转换与图表适配
在数据可视化中,将数据从宽格式转换为长格式时,需通过列名重新组织数据,使用melt()函数将多列数据合并为“变量”和“值”两列,便于生成柱状图或折线图。 -
动态列标签的生成
在生成图表时,通过列名动态调整标签内容,使用plot()函数时,指定x=df.columns[0]可自动绑定第一列作为横轴,提升代码灵活性。 -
多列数据的对比展示
利用多列数据生成对比图表时,需明确各列对应的数据维度,使用df[['销售额', '成本']].plot(kind='bar')可同时展示销售额和成本的柱状图,直观反映数据差异。
实际案例分析
-
Excel中的列动态编号
假设有一张销售数据表,A列是产品名称,B列是销售额,C列是成本,使用=COLUMN(A1)可动态获取A列的编号,再结合INDEX函数生成产品名称列表,避免因列位置变动导致的公式错误。 -
Python中列的条件筛选
在销售数据集中,若需筛选出销售额高于成本的记录,可使用df['销售额'] > df['成本']生成布尔序列,再通过df.loc[条件]提取符合条件的行,如df.loc[df['销售额'] > df['成本']]。 -
数据库中的列分组汇总
在分析某地区销售数据时,使用GROUP BY 地区对销售额列进行汇总,再结合ORDER BY按总销售额排序,如SELECT 地区, SUM(销售额) FROM 销售表 GROUP BY 地区 ORDER BY SUM(销售额) DESC。 -
数据清洗中的列标准化
若某列包含“1000元”“5000”等混合格式数据,需通过正则表达式提取数值部分,使用df['价格'].str.replace('元', '').astype(int)将价格列统一为整数类型,便于后续计算。 -
数据可视化中的列对比
在展示不同产品的销售表现时,使用df[['产品A', '产品B']].plot(kind='bar')生成柱状图,通过调整x和y参数,可直观比较各列数据的分布差异。
总结与注意事项
column函数的核心价值在于动态处理数据列,提升操作效率与灵活性,无论是Excel、Python还是数据库场景,正确使用列名和列索引都能避免手动调整带来的错误,需要注意以下几点:
- 列名需保持唯一性:避免同名列导致的数据混淆,例如在数据库中,若存在多个同名列需通过表名限定。
- 列索引的稳定性:在Excel中,COLUMN函数返回的列号可能因插入/删除列而变化,建议结合绝对引用(如
$A$1)固定位置。 - 数据类型的匹配:在Python中,列操作需确保数据类型一致,例如字符串列无法直接与数值列进行数学运算。
- 性能优化:在大规模数据处理中,避免频繁使用列名索引可能导致的计算延迟,可优先使用列编号或预处理数据。
column函数的应用场景远不止上述案例,关键在于理解列与数据之间的逻辑关系,通过合理选择列名、列索引或列操作,可显著提升数据分析、处理和展示的效率,同时减少人为错误,无论是初学者还是资深开发者,掌握column函数的灵活使用都是提升数据处理能力的重要一步。
“column函数举例,探索column函数,实用举例解析” 的相关文章
c语言程序设计在线编程,在线实践,C语言程序设计编程挑战
介绍了C语言程序设计在线编程的相关知识,通过在线平台,学习者可以实践编写和运行C语言程序,掌握编程基础,包括变量、数据类型、控制结构、函数和指针等概念,文章可能涵盖了编程环境搭建、代码编写技巧、调试方法以及常见编程问题的解决策略,通过在线编程,用户能够灵活学习,提高编程技能。C语言程序设计在线编程:...

animate下载免费版,Animate免费版下载指南
Animate下载免费版是Adobe公司推出的一款功能强大的动画制作软件,用户可以通过该软件轻松地制作出高质量的动画作品,免费版虽然功能有限,但已能满足大多数动画制作需求,下载并安装Animate免费版,只需遵循官方网站的简单步骤,即可开始您的动画创作之旅。animate下载免费版 用户解答:...

c语言2级考试题库,C语言二级考试题库精选
为C语言二级考试题库相关资料,涵盖了C语言二级考试的各类题型和知识点,题库内容丰富,包括选择题、填空题、编程题等,旨在帮助考生全面复习和巩固C语言基础知识,提高解题能力,为顺利通过C语言二级考试做好准备。 我正在准备C语言二级考试的复习,感觉题目难度适中,但有些概念还是需要巩固,指针和数组的关系,...

app开发公司定制外包,一站式APP开发公司定制外包服务
App开发公司提供定制外包服务,专注于根据客户需求定制开发各类应用程序,服务涵盖从需求分析、设计到开发、测试和部署的全过程,旨在为客户提供高效、专业的解决方案,满足不同行业和用户群体的个性化需求,通过定制外包,企业可以快速获得高质量的应用,降低开发成本,提高市场竞争力。APP开发公司定制外包:让专业...

学编程先学什么,编程入门必学基础技能盘点
学习编程首先应掌握基础语法和编程思维,推荐从Python或Java等易于上手的语言开始,了解变量、数据类型、控制结构等基本概念,随后,学习算法和数据结构,为编写高效程序打下基础,了解版本控制工具如Git,以及基本的调试技巧,对编程学习也至关重要。用户解答:学编程先学什么?这问题问得好,我刚开始学编程...
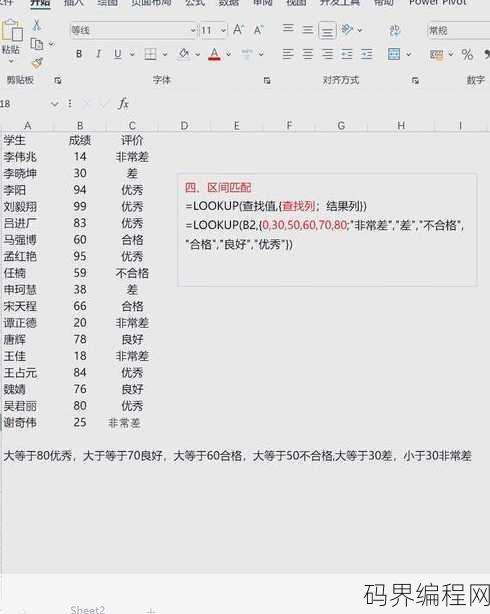
lookup函数和vlookup函数的区别,VLOOKUP与LOOKUP函数的差异解析
lookup函数和vlookup函数都是Excel中用于查找数据的函数,但存在以下区别:,1. lookup函数只能从左到右查找,而vlookup函数可以向上或向下查找。,2. lookup函数只能返回第一个匹配值,而vlookup函数可以返回任意匹配值。,3. lookup函数要求查找区域和返回区...
- 最新发布
-

2分钟前
9分钟前

16分钟前
23分钟前
29分钟前
- 热门阅读
-

918 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言