爬虫的分类(爬虫分类的选择题)
本文目录一览:
- 1、python爬虫是什么意思
- 2、爬虫(一)
- 3、什么是爬虫软件呢
- 4、爬虫与反爬虫技术简介
- 5、python爬虫是什么
python爬虫是什么意思
网络爬虫的定义:网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或脚本。这些程序通常用于数据收集、搜索引擎索引等目的。Python与爬虫的关系:由于Python语言具有简洁易读、语法优雅、库丰富等特点,非常适合用来编写网络爬虫程序。因此,很多开发者选择使用Python来开发爬虫,导致“Python爬虫”这一术语非常流行。
Python爬虫是一种使用Python程序开发的网络爬虫,主要用于按照一定的规则自动地抓取万维网信息。以下是关于Python爬虫的具体解释及其用途:Python爬虫的定义 网络爬虫:也被称为网页蜘蛛、网络机器人等,是一种自动地抓取万维网信息的程序或脚本。
Python爬虫是一种自动化爬取网站数据的编程技术。以下是关于Python爬虫的详细解释:定义:Python爬虫通过模拟浏览器的行为,自动访问网站并抓取所需要的数据。这种技术能够实现大规模数据的采集和处理。
python为什么叫爬虫要知道python为什么叫爬虫,首先需要知道什么是爬虫。爬虫,即网络爬虫,大家可以理解为在网络上爬行的一只蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛,如果它遇到自己的猎物(所需要的资源),那么它就会将其抓取下来。
Python爬虫是指使用Python编程语言编写的网络爬虫程序。以下是关于Python爬虫的详细解释:定义:Python爬虫是一种按照一定的规则,自动地抓取万维网信息的程序。它通过模拟客户端发送网络请求,并接收网络响应,从中提取所需的数据。功能:数据抓取:自动从网页上抓取数据,这些数据可以是文本、图片、视频等。
爬虫(一)
在Python爬虫开发中,应对某些网站的反爬机制至关重要。当遇到403错误或类似提示时,关键在于修改requests中的headers,模拟浏览器访问。requests库中的get和post方法默认的User-Agent标识了请求来源,这可能会暴露为Python爬虫,从而触发网站的反爬策略。
遵守法律与网站条款:在爬取数据前,确保遵守相关法律法规和亚马逊的网站条款。反爬虫机制:亚马逊有反爬虫机制,需要合理设置请求频率和请求头,以避免被封禁。动态内容处理:如果商品信息是动态加载的,可能需要使用Selenium等工具来处理JavaScript渲染的内容。
爬虫过程:首先在Chrome中打开目标页面,F12模式调整为手机视图。完成准备后,访问目标网址,由于是PC端操作,网站无法获取个人位置,跳转至选择位置页面。点击选择城市后,网站显示如下界面。通过Chrome的抓包功能,找到全国城市列表的无加密GET请求,完成第一步。

最终,完成针对基于JavaScript加密的商品信息抓取问题的Python爬虫实现。请注意,以下接口仅用于合法学习交流,切勿用于非法用途。
什么是爬虫软件呢
爬虫软件是一种自动化程序,主要用于搜索引擎,它遍历并读取网站的内容与链接,并将这些信息建立到数据库中。以下是关于爬虫软件的详细解释:工作原理:爬虫软件模拟人类浏览网页的行为,自动访问网站,读取网页上的内容。它将这些内容存储到数据库中,以便后续进行索引和搜索。
爬虫软件的正宗名称是python计算机编程语言,广泛应用于系统管理任务的处理和Web编程。python软件为什么叫爬虫软件?爬虫通常指的是网络爬虫,就是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。所以Python被很多人称为爬虫。
爬虫软件是一种自动化程序,用于在互联网上获取信息并收集数据,用途广泛,主要包括以下方面:搜索引擎构建:搜索引擎借助网络爬虫收集互联网信息,建立网页索引,使用户搜索时能快速找到相关内容。
爬虫软件是一种专门用于搜索引擎的程序,它具备强大的功能,能够读取一个网站的所有内容和链接,并创建相应的全文索引,存储在数据库中。随后,它会转移到另一个网站,继续执行这一流程,仿佛一只在网络中穿梭的大蜘蛛。
爬虫与反爬虫技术简介
1、反爬虫技术简介:目的:维护网络安全,保护服务器资源,减轻压力,防止数据泄露。常用策略:文本混淆:如CSS偏移隐藏文本、图片中的隐藏文字、自定义字体的识别等。动态渲染技术:区分客户端和服务端渲染,增加爬虫抓取难度。验证码验证:包括图形验证码、行为验证、短信验证和二维码等,确保操作来自真人。
2、爬虫是指通过程序自动获取网页上的数据的技术,而反爬虫是指网站为了防止被爬虫程序获取数据而采取的一系列措施。在爬取知乎数据时,需要注意以下几点: 使用合法的方式进行数据爬取,遵守知乎的相关规定和协议。 设置合理的爬取频率,避免对知乎服务器造成过大的负担。
3、反爬技术,即反爬虫技术,是指网站或服务为防止爬虫程序对其内容进行大量抓取而采取的一系列措施。以下是关于反爬技术的详细解释: IP封禁 定义:网站会记录并分析访问者的IP地址,对于访问频率异常(如短时间内发起大量请求)的IP地址,可能会进行封禁处理。目的:防止爬虫程序通过频繁请求获取大量数据。
4、. 数据加密:通过自定义字体、CSS、图片、特殊编码等进行数据保护。解析图片、多格式解码以获取内容。总结 反爬虫技术不断发展,针对不同策略需灵活应用相应的解决方法。遵循合法爬虫规范,合理使用技术手段,不断学习和适应新的反爬策略,是高效抓取网页内容的关键。
python爬虫是什么
1、Python爬虫是一种使用Python程序开发的网络爬虫,主要用于按照一定的规则自动地抓取万维网信息。以下是关于Python爬虫的具体解释及其用途:Python爬虫的定义 网络爬虫:也被称为网页蜘蛛、网络机器人等,是一种自动地抓取万维网信息的程序或脚本。
2、Python爬虫是一种自动化爬取网站数据的编程技术。以下是关于Python爬虫的详细解释:定义:Python爬虫通过模拟浏览器的行为,自动访问网站并抓取所需要的数据。这种技术能够实现大规模数据的采集和处理。
3、python为什么叫爬虫要知道python为什么叫爬虫,首先需要知道什么是爬虫。爬虫,即网络爬虫,大家可以理解为在网络上爬行的一只蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛,如果它遇到自己的猎物(所需要的资源),那么它就会将其抓取下来。
4、Python:Python是一种广泛使用的高级编程语言,以其简洁易读的语法、强大的库支持和广泛的应用领域而著称。爬虫:爬虫,通常指的是网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
“爬虫的分类(爬虫分类的选择题)” 的相关文章

asp怎么使用,ASP基础教程,入门与实战指南
ASP(Active Server Pages)是一种服务器端脚本环境,用于创建动态交互式网页和Web应用程序,以下是如何使用ASP的基本步骤:,1. 安装IIS(Internet Information Services):在Windows服务器上安装IIS以支持ASP。,2. 创建ASP文件:使...
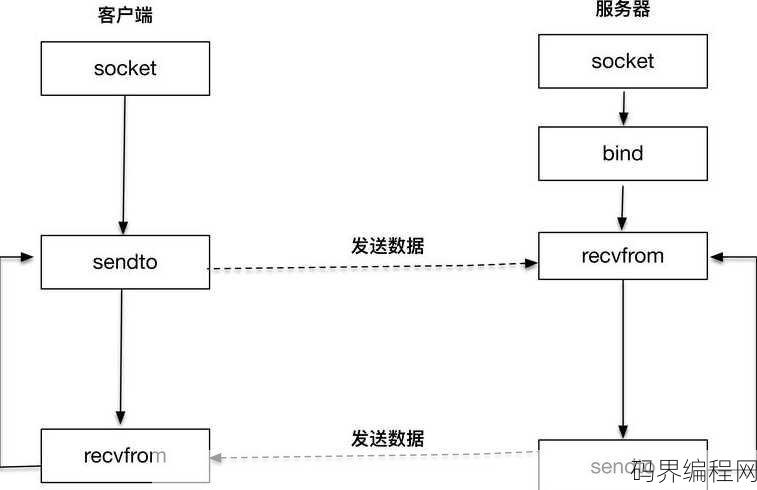
socket编程流程图,Socket编程流程解析图
Socket编程流程图摘要:,1. 初始化:创建Socket对象,选择合适的协议(TCP或UDP)。,2. 绑定:将Socket绑定到指定的IP地址和端口号。,3. 监听:在绑定端口后,调用listen()函数,准备接收客户端连接请求。,4. 接受连接:使用accept()函数接受客户端的连接请求,...

html文本代码,HTML文本代码解析与应用实例
您似乎没有提供具体的HTML文本代码内容,请提供您希望我摘要的HTML代码,我才能为您生成摘要。 嗨,大家好!今天我来和大家聊聊HTML文本代码这个话题,HTML,全称是HyperText Markup Language,也就是超文本标记语言,是构建网页的基础,HTML就像是一种特殊的“文字排版工...

js 获取焦点,JavaScript实现元素获取焦点技巧解析
JavaScript中获取焦点通常指的是使某个元素获得键盘输入的权限,这可以通过以下几种方式实现:,1. 使用focus()方法:直接调用元素的focus()方法可以使该元素获得焦点。,2. 通过事件监听:监听如click、mouseover等事件,并在事件处理函数中调用focus()方法。,3....

绝世剑神叶云免费阅读,叶云,绝世剑神传奇免费畅读
《绝世剑神叶云》是一部免费阅读的武侠小说,讲述了主角叶云凭借绝世剑法,历经磨难,最终成为一代剑神的传奇故事,在江湖中,叶云以一柄神剑,挑战各方势力,守护正义,谱写了一段荡气回肠的武侠传奇。:绝世剑神叶云免费阅读——带你领略剑道巅峰的奇幻之旅 : 作为一个热爱玄幻小说的读者,我最近迷上了一本名为《...

excel的index函数的使用方法,Excel Index函数操作指南
Excel的INDEX函数用于返回表格或数组中的某个单元格或单元格区域的值,使用方法如下:首先在公式栏输入“=INDEX(”,接着指定要查找的数组或引用,用逗号分隔;然后输入行号或行引用,再用逗号分隔;最后输入列号或列引用。“=INDEX(A1:C3, 2, 3)”将返回C3单元格的值,如果需要指定...
- 最新发布
-
2分钟前
8分钟前
16分钟前

20分钟前
26分钟前
- 热门阅读
-

918 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言