c语言网络爬虫,C语言实现网络爬虫技术解析
C语言编写的网络爬虫,利用C语言的强大功能和灵活性,能够高效地从互联网上抓取数据,该爬虫通过解析HTML文档,提取所需信息,支持多线程处理以提高抓取速度,它能够自动处理网页跳转、重定向等问题,同时具备一定的反反爬虫策略应对,适用于快速开发轻量级网络数据采集工具。
C语言网络爬虫开发
作为一名C语言开发者,你是否对网络爬虫的概念感到好奇?你是否想过如何利用C语言实现一个简单的网络爬虫?就让我带你走进C语言网络爬虫的世界,一起探讨如何用C语言实现一个基础的网络爬虫。
网络爬虫是什么?
网络爬虫(Web Crawler)是一种模拟搜索引擎爬取互联网上网页的程序,它通过发送HTTP请求,获取网页内容,并对网页内容进行分析、提取、存储等操作,网络爬虫就像一只勤劳的“蜘蛛”,在互联网上收集信息。
C语言网络爬虫的实现
我们从以下几个方面深入探讨C语言网络爬虫的实现:
(1)HTTP请求
实现网络爬虫的第一步是发送HTTP请求,在C语言中,可以使用libcurl库来发送HTTP请求。

#include <curl/curl.h>
int main() {
CURL *curl;
CURLcode res;
curl = curl_easy_init();
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "http://www.example.com");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, NULL);
res = curl_easy_perform(curl);
if(res != CURLE_OK)
fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res));
curl_easy_cleanup(curl);
}
return 0;
}
(2)网页内容提取 后,需要提取网页中的关键信息,这里,我们可以使用libxml2库进行XML解析。
#include <libxml/xmlparse.h>
#include <libxml/xmlstring.h>
void callback(void *ctx, const char *line, int len) {
xmlParseMemory(line, len);
}
int main() {
CURL *curl;
CURLcode res;
FILE *fp;
char *content;
curl = curl_easy_init();
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "http://www.example.com");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, callback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, NULL);
res = curl_easy_perform(curl);
if(res != CURLE_OK)
fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res));
curl_easy_cleanup(curl);
}
fp = fopen("content.xml", "w");
if(fp) {
xmlSaveFile(fp, content);
fclose(fp);
}
return 0;
}
(3)网页内容存储 后,需要将其存储到本地,这里,我们可以使用文件系统存储。
#include <stdio.h>
int main() {
FILE *fp;
char *content = "<html><body>这是一个示例网页</body></html>";
fp = fopen("example.html", "w");
if(fp) {
fputs(content, fp);
fclose(fp);
}
return 0;
}
(4)多线程
为了提高爬虫的效率,可以使用多线程技术,在C语言中,可以使用pthread库实现多线程。
#include <pthread.h>
void *thread_function(void *arg) {
// 线程任务
return NULL;
}
int main() {
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, thread_function, NULL);
pthread_create(&thread2, NULL, thread_function, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}
(5)避免重复

在爬取网页时,需要避免重复访问同一网页,我们可以使用哈希表或数据库存储已访问的网页URL。
本文地介绍了C语言网络爬虫的开发过程,通过本文,你应掌握了如何使用C语言实现一个简单的网络爬虫,网络爬虫还有很多高级技术,如正则表达式、爬虫框架等,需要你在实践中不断学习和探索。
其他相关扩展阅读资料参考文献:
C语言网络爬虫:从入门到精通
随着互联网的发展,网络爬虫技术变得越来越重要,网络爬虫主要用于数据的收集与整理,为大数据分析提供了丰富的资源,本文将介绍如何使用C语言进行网络爬虫开发,带你从入门到精通,我们将从以下几个展开讨论:
一:基础概念与工具介绍
- 网络爬虫定义及作用
网络爬虫是一种自动化程序,能够按照一定的规则在互联网上抓取数据,它在搜索引擎、数据挖掘等领域有广泛应用。 - C语言在网络爬虫中的应用
C语言在网络爬虫中主要用于底层开发,如Socket编程、多线程处理等,其高效、灵活的特性使其成为网络爬虫开发的重要语言之一。 - 常用工具介绍
对于C语言网络爬虫开发,常用的工具包括libcurl库进行HTTP请求处理、正则表达式进行数据处理等,这些工具将大大提高开发效率。
二:核心技术解析
- HTTP协议基础
了解HTTP协议是构建网络爬虫的基础,包括如何发送请求、接收响应、处理Cookie等。 - 网页数据抓取
数据抓取是网络爬虫的核心,这涉及到HTML解析、DOM树遍历以及数据提取技术。 - 反反爬虫策略
随着网站反爬虫技术的增强,如何应对反反爬虫策略成为关键,这包括处理动态加载内容、JavaScript渲染等问题。
三:实践案例分享
- 简单爬虫实现
通过一个简单的网站数据抓取实例,展示C语言网络爬虫的基本实现过程。 - 复杂场景应对
针对如登录验证、动态加载内容等复杂场景,介绍解决方案和代码示例。 - 数据持久化存储
介绍如何将爬取的数据保存到本地,如使用数据库进行数据存储和管理。
四:优化与进阶技巧
- 性能优化
讨论如何优化网络爬虫的性能,如并发处理、减少请求延迟等。 - 分布式爬虫构建
介绍如何将单个爬虫扩展到分布式环境,提高数据爬取效率。 - 安全合规性探讨
讨论在爬虫开发中如何遵守法律法规,避免侵犯网站权益和个人隐私。
就是关于C语言网络爬虫的基本介绍和主要,通过学习这些,你将逐步掌握网络爬虫的核心技术,并能够独立开发出高效的网络爬虫程序,在实际开发中,还需要不断学习和探索新的技术与方法,以适应互联网环境的变化和发展。
“c语言网络爬虫,C语言实现网络爬虫技术解析” 的相关文章
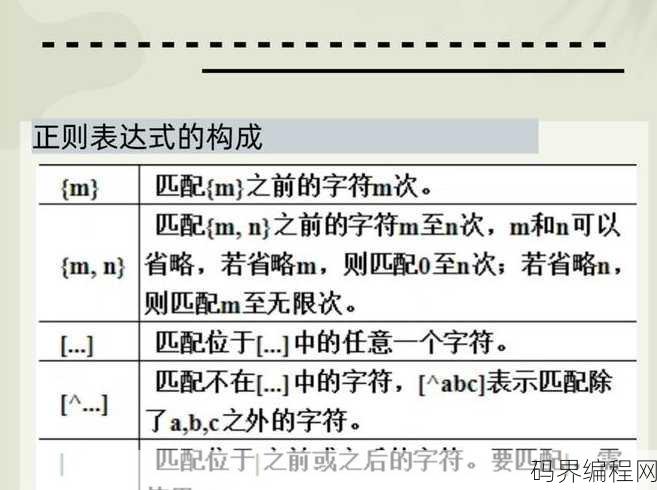
js正则表达式匹配括号,JavaScript正则表达式,掌握括号匹配技巧
JavaScript正则表达式用于匹配括号,可以通过使用特殊字符和模式来定义括号内的内容,\(pattern\) 可以匹配括号内的 pattern,而 [pattern] 用于匹配括号内的任意字符集合,要匹配整个括号结构,可以使用 \( 和 \) 来转义括号字符,从而将其视为字面量,正则表达式 \(...
w3cschool安卓版,W3cschool安卓官方版,随时随地学习编程新体验
W3cschool安卓版是一款提供全面编程学习资源的移动应用,用户可在此应用中学习Web开发、移动开发、前端技术、后端技术等课程,涵盖HTML、CSS、JavaScript、Java等多种编程语言,应用内提供丰富的教程、视频和示例代码,支持离线学习,助力用户随时随地提升编程技能。体验W3cschoo...
帝国cms门户模板,帝国CMS门户模板定制与优化指南
帝国CMS门户模板是一种专为帝国内容管理系统(CMS)设计的模板,旨在帮助用户快速搭建和美化网站门户界面,该模板支持多种布局和功能模块,包括新闻、图片、视频等内容的展示,以及自定义导航和搜索功能,旨在提升用户体验和网站的可访问性,通过使用帝国CMS门户模板,用户可以节省开发时间,实现快速上线和高效管...
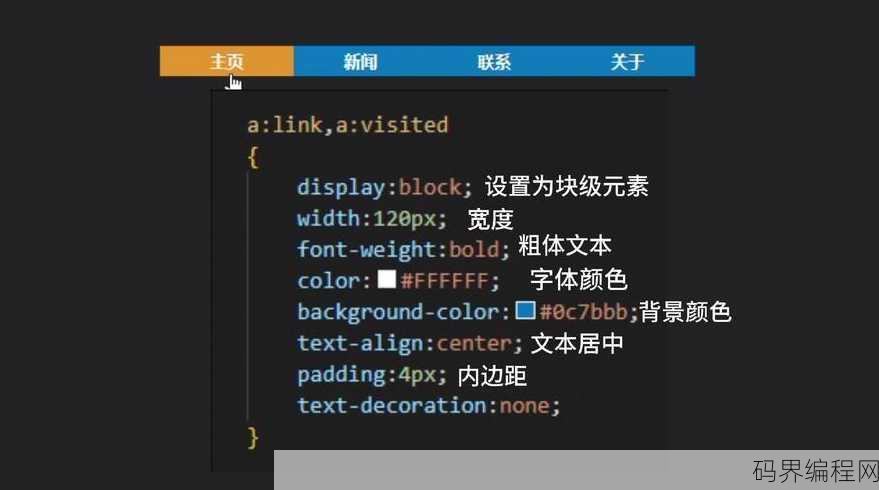
透明导航栏代码,创建透明导航栏的HTML/CSS代码示例
透明导航栏代码通常指的是用于创建一个半透明或完全透明的导航栏的HTML和CSS代码,这段代码允许开发者实现一个视觉上与页面背景融合的导航栏,提升用户体验,代码通常包括设置导航栏的背景透明度、边框样式、以及可能的动画效果,以下是一个简单的透明导航栏代码示例:,``html,,,,,,, .navba...

网页炫酷特效,探索网页设计的炫酷特效奥秘
网页炫酷特效是指在网页设计中运用各种视觉和动态效果,以提升用户体验和网站的吸引力,这些特效可能包括动画、过渡效果、3D模型、粒子效果等,它们可以增强网页的互动性和趣味性,通过合理运用炫酷特效,网站不仅能在视觉上给人留下深刻印象,还能提高用户留存率和转化率,过度使用或不当设计可能会影响网站的性能和可访...

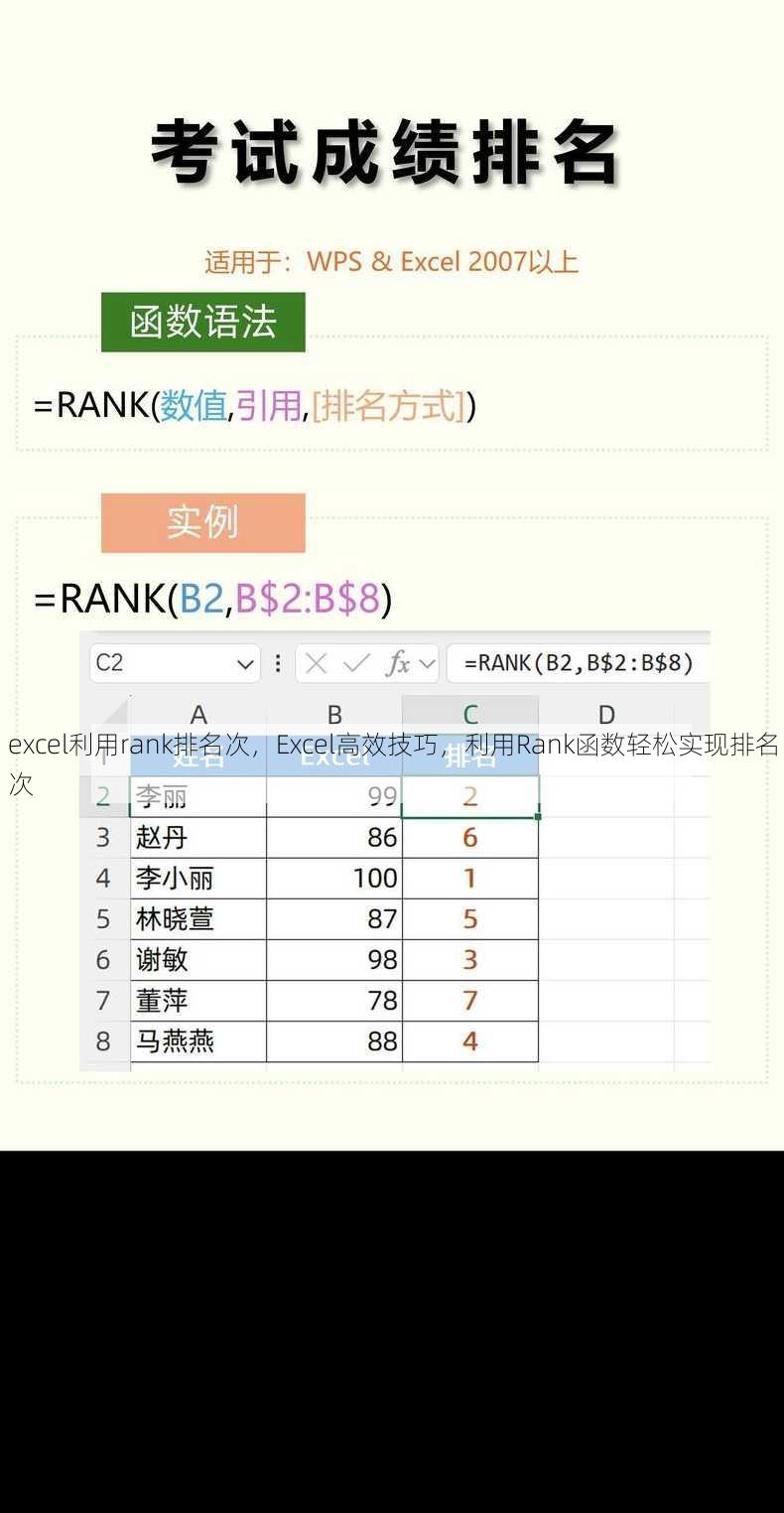
excel随机生成范围内数字,Excel技巧,如何随机生成指定范围内的数字
在Excel中,可以通过以下方法随机生成指定范围内的数字:1. 选择单元格;2. 输入公式“=RANDBETWEEN(最小值, 最大值)”;3. 按下Enter键,该公式会生成一个介于最小值和最大值之间的随机整数,每次打开Excel文件或刷新工作表时,生成的数字会发生变化。 大家好,我最近在使用E...
- 最新发布
-

2分钟前
9分钟前

16分钟前

23分钟前
30分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言