json数组去重,高效实现JSON数组去重的方法解析
在处理JSON数组时,去重是一个常见的需求,以下是一个纯文本摘要:,去重JSON数组通常涉及以下步骤:遍历数组中的每个元素;检查该元素是否已存在于一个临时存储结构(如集合或字典)中;如果不存在,则添加到存储结构中;将存储结构中的元素重新构建成一个新的数组,即为去重后的结果,这种方法能有效去除数组中的重复元素,确保每个元素只出现一次。
JSON数组去重:轻松解决数据重复烦恼
用户解答: 嗨,大家好!最近我在处理一个JSON数据文件时,发现里面有很多重复的数组元素,这让我在后续的数据处理和分析中遇到了不少麻烦,我想知道有没有什么好的方法可以快速去除这些重复的元素呢?谢谢大家!
一:理解JSON数组去重的必要性
- 数据准确性:重复的数据会导致分析结果不准确,影响决策。
- 存储效率:重复的数据占用更多的存储空间,降低数据存储效率。
- 处理速度:重复数据在处理时需要额外的时间进行去重,降低处理速度。
二:JSON数组去重的方法
-
使用JavaScript:
- 方法一:使用
Set对象。Set对象是一个集合,它只存储唯一的值。let arr = [1, 2, 2, 3, 4, 4, 5]; let uniqueArr = [...new Set(arr)]; console.log(uniqueArr); // 输出:[1, 2, 3, 4, 5]
- 方法二:使用
filter方法。let arr = [1, 2, 2, 3, 4, 4, 5]; let uniqueArr = arr.filter((item, index) => arr.indexOf(item) === index); console.log(uniqueArr); // 输出:[1, 2, 3, 4, 5]
- 方法一:使用
-
使用Python:
- 方法一:使用
set数据结构。arr = [1, 2, 2, 3, 4, 4, 5] unique_arr = list(set(arr)) print(unique_arr) # 输出:[1, 2, 3, 4, 5]
- 方法二:使用
dict.fromkeys。arr = [1, 2, 2, 3, 4, 4, 5] unique_arr = list(dict.fromkeys(arr)) print(unique_arr) # 输出:[1, 2, 3, 4, 5]
- 方法一:使用
-
使用Java:
- 方法一:使用
HashSet。List<Integer> arr = Arrays.asList(1, 2, 2, 3, 4, 4, 5); Set<Integer> uniqueSet = new HashSet<>(arr); List<Integer> uniqueArr = new ArrayList<>(uniqueSet); System.out.println(uniqueArr); // 输出:[1, 2, 3, 4, 5]
- 方法二:使用
LinkedHashSet。List<Integer> arr = Arrays.asList(1, 2, 2, 3, 4, 4, 5); Set<Integer> uniqueSet = new LinkedHashSet<>(arr); List<Integer> uniqueArr = new ArrayList<>(uniqueSet); System.out.println(uniqueArr); // 输出:[1, 2, 3, 4, 5]
- 方法一:使用
三:JSON数组去重注意事项
- 数据类型:确保数组中的元素类型一致,否则去重效果可能不理想。
- 顺序保留:如果需要保留原始数组的顺序,建议使用
LinkedHashSet或filter方法。 - 性能优化:对于大数据量的数组,可以考虑使用并行处理或分批处理来提高去重效率。
四:JSON数组去重应用场景
- 数据清洗:在数据分析、数据挖掘等场景中,去除重复数据可以提高数据质量。
- 数据存储:在存储JSON数据时,去除重复数据可以节省存储空间。
- 数据传输:在数据传输过程中,去除重复数据可以减少传输时间。
通过以上方法,我们可以轻松地解决JSON数组去重的问题,希望这篇文章能帮助到大家,谢谢!
其他相关扩展阅读资料参考文献:
常见JSON去重场景与需求
- 数据导入时的重复记录:在从外部系统导入JSON数据时,重复的条目可能导致分析结果失真,例如用户行为统计或库存管理中的冗余数据。
- 接口响应数据的冗余:某些API会返回重复的JSON数组元素,例如分页查询时未处理好去重逻辑,导致数据重复加载。
- 日志处理中的重复条目:日志文件中可能包含重复的JSON日志条目,需通过去重确保日志分析的准确性。
- 用户数据的唯一性校验:用户注册或登录时,若未对JSON数组中的用户信息进行去重,可能引发重复账号问题。
- 缓存数据的更新与去重:缓存系统中需避免重复存储相同数据,例如通过时间戳或版本号过滤过期条目。
基本去重方法与实现原理
- 利用唯一标识字段:通过JSON对象的唯一属性(如
id)作为判断依据,例如使用Array.prototype.filter()结合Set存储已存在ID,确保数组中无重复项。 - 遍历对比法:逐个检查数组元素,若当前元素与已遍历元素的某些属性(如
name)重复,则跳过。const uniqueArray = jsonArray.filter((item, index, self) => self.findIndex(i => i.name === item.name) === index );
- 使用Set数据结构:将JSON数组转换为Set,利用其键值对特性自动去重,但需注意Set仅适用于可哈希的数据类型(如字符串、数字)。
- 对象属性组合哈希:将多个属性拼接为唯一标识符(如
name + id),通过生成哈希值实现去重,适用于复杂对象的唯一性判断。 - 第三方库辅助:借助
lodash的uniqBy或uniq方法,直接传入自定义比较函数,简化去重逻辑。
高级去重技巧与边界处理
- 自定义比较函数:针对嵌套对象或动态属性,编写逻辑判断函数(如比较
email和phone字段组合),确保去重条件全面。 - 深度克隆与引用去重:若数组元素包含引用类型(如对象),需先进行深度克隆,避免因引用地址相同导致误判。
- 分页数据去重:在处理大数据量时,结合分页参数(如
page和pageSize)分段去重,减少内存占用。 - 时间戳过滤:对包含时间字段的JSON数组,保留最新时间戳的条目,例如通过
Array.prototype.sort()排序后取最后一条。 - 多条件组合去重:同时校验多个字段(如
name和age),避免单一条件导致的误判,const uniqueArray = jsonArray.filter((item, index, self) => self.findIndex(i => i.name === item.name && i.age === item.age) === index );
性能优化与效率提升
- 减少遍历次数:优先使用
Set或Map结构,将时间复杂度从O(n²)降至O(n),显著提升大数据量处理效率。 - 内存优化:避免深拷贝对象,仅提取关键字段生成哈希值,降低内存消耗。
- 并行处理:对超大规模JSON数组,采用分片处理或并行计算,将数据拆分为多个子集并行去重,缩短执行时间。
- 索引优化:为高频查询字段(如
id)建立索引,通过Map快速定位重复项,减少冗余计算。 - 算法选择:根据数据特征选择最优算法,例如对有序数组使用双指针法,对无序数组使用哈希表法。
工具与库的高效应用
- Lodash的
uniqBy:支持自定义比较函数,_.uniqBy(jsonArray, item => item.id);
适用于复杂对象的去重需求。
- Underscore的
compact:过滤掉数组中的null或空值,适合简化数据清洗流程。 - Fast-JSON-Patch的
diff:通过对比JSON对象差异,精准定位重复条目。 - JSON Schema校验:定义唯一性约束(如
uniqueItems: true),确保数据源头无重复。 - 自定义工具函数:编写通用去重函数,支持传入字段名或比较逻辑,提升代码复用性。
实践建议与注意事项
- 优先校验数据源:在数据生成阶段避免重复,比事后去重更高效。
- 避免过度依赖单一字段:需综合考虑业务逻辑,例如用户去重可能需结合
email和phone字段。 - 测试边界条件:处理空数组、单元素数组或字段值为
null的情况,确保代码鲁棒性。 - 关注性能瓶颈:对百万级数据量,优先选择
Set或Map而非纯遍历。 - 文档化去重规则:明确记录去重逻辑,便于后续维护与团队协作。
JSON数组去重是数据处理中的核心环节,其方法需根据具体场景灵活选择。通过合理利用唯一标识、高效算法和工具库,既能保证数据准确性,又能提升处理效率,在实际开发中,建议结合业务需求与性能指标,制定最优去重策略。
“json数组去重,高效实现JSON数组去重的方法解析” 的相关文章
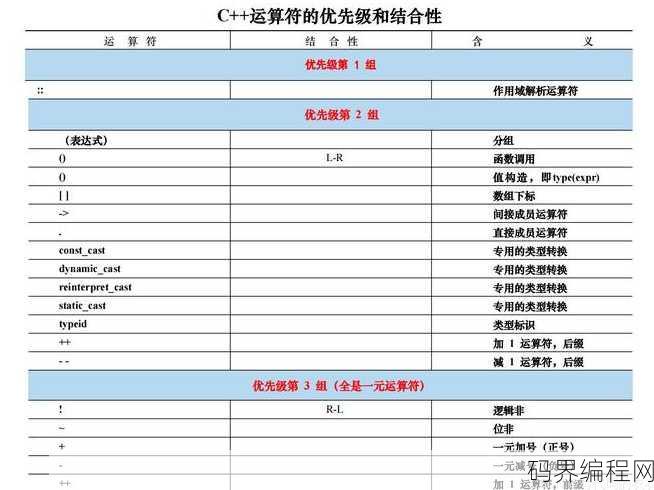
c+一共有几级,C++编程语言的级别划分的介绍
C++编程语言级别划分如下:C++是一种面向对象的编程语言,它继承了C语言的所有特性,并在此基础上增加了面向对象编程的特性,C++的级别划分通常包括以下几个层次:基础语法、面向对象编程、模板编程、STL(标准模板库)、异常处理、多线程编程等,这些级别逐步深入,使开发者能够掌握C++语言的核心概念和应...

css选择器的定义方法,CSS选择器全面解析,定义与用法指南
CSS选择器用于指定样式规则应用于网页中的特定元素,定义CSS选择器的方法有多种,包括:,1. **标签选择器**:直接使用HTML标签名称,如p选择所有`元素。,2. **类选择器**:在标签名后添加.和类名,如.my-class选择所有类名为my-class的元素。,3. **ID选择器**:在...

beanpole包包,Beanpole时尚长款手提包推荐
beanpole包包,一款时尚潮流的单肩包,采用优质面料制作,设计简约大方,其独特的造型和实用性,深受年轻消费者的喜爱,beanpole包包不仅适合日常出行,也适合各种场合佩戴,为你的生活增添一份时尚魅力。 自从入手了这款beanpole包包,我的生活真的发生了翻天覆地的变化,这款包包的设计简约而...

beanpole滨波专卖店,beanpole滨波品牌专卖店,潮流服饰尽在掌握
beanpole滨波专卖店是一家专注于时尚服饰的零售店,提供多种风格的单品,包括服装、鞋履和配饰,店内设计现代且充满活力,致力于为顾客提供高品质的购物体验,beanpole以其简洁的线条和独特的设计理念,吸引了一大批追求时尚潮流的消费者,店内商品涵盖男女装,适合各种场合穿着,旨在满足不同年龄层和风格...

basic,探索基本原理,深入解析BASIC内容
由于您没有提供具体内容,我无法为您生成摘要,请提供您希望摘要的内容,我将根据内容为您生成摘要。解析“Basic” 用户解答: 嗨,我是小李,最近在学习编程基础,但是感觉有些概念有点模糊,想请教一下,什么是基本数据类型?还有,基础的算法应该怎么理解?希望能得到一些简单的解释。 下面,我就从几个基...

python开发app,Python赋能,轻松开发移动应用
Python开发App,主要涉及使用Python语言进行应用程序的开发,开发者可以利用Python强大的库和框架,如Django、Flask等,构建Web应用或桌面应用,Python简洁易读的语法和丰富的第三方库,使得开发过程高效、便捷,Python在数据科学、人工智能等领域也有广泛应用,为App开...
- 最新发布
-
5分钟前

8分钟前
16分钟前
22分钟前
30分钟前
- 热门阅读
-

918 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言