sql distinct用法,SQL中Distinct关键字的应用与优势
SQL中的DISTINCT关键字用于从结果集中选择唯一的记录,当查询结果可能包含重复行时,使用DISTINCT可以避免这些重复,在查询员工信息时,如果想要显示不重复的部门,就可以在SELECT语句中使用DISTINCT来确保每个部门只显示一次,基本语法是:SELECT DISTINCT column_name FROM table_name;这将返回指定列中不重复的唯一值,需要注意的是,当与聚合函数(如COUNT、SUM等)一起使用时,DISTINCT只对聚合函数内的列起作用。
解析SQL中的DISTINCT用法
用户解答: 嗨,我最近在使用SQL查询数据时遇到了一个问题,我想知道DISTINCT关键字是做什么用的?为什么有时候不用它查询结果会重复?
下面,我们就来地解析一下SQL中的DISTINCT用法。

一:DISTINCT的基本概念
- 定义:DISTINCT是SQL中用于选择查询结果中不重复记录的关键字。
- 作用:在SELECT语句中使用DISTINCT可以去除查询结果中的重复行,只保留唯一的记录。
- 语法:
SELECT DISTINCT column1, column2 FROM table_name;
二:DISTINCT的适用场景
- 数据去重:当查询结果中存在重复数据时,使用DISTINCT可以快速去除重复项。
- 分析唯一值:在进行数据分析时,需要统计某一列的唯一值时,DISTINCT非常有用。
- 提高效率:在某些情况下,使用DISTINCT可以减少查询结果的数据量,提高查询效率。
三:DISTINCT与ORDER BY的区别
- 目的不同:DISTINCT用于去除重复记录,而ORDER BY用于对结果进行排序。
- 使用方式:DISTINCT可以与ORDER BY一起使用,但它们的顺序很重要,先使用DISTINCT去除重复,再使用ORDER BY进行排序。
- 性能影响:在包含大量重复数据的表中,使用DISTINCT可能会影响查询性能。
四:DISTINCT的注意事项
- 性能问题:在大型数据表中使用DISTINCT可能会降低查询性能,因为数据库需要检查每一行是否重复。
- 列的选择:在使用DISTINCT时,应仔细选择需要去重的列,避免不必要的性能损耗。
- 与GROUP BY结合:在某些情况下,可以使用GROUP BY与DISTINCT结合,以实现更复杂的查询需求。
五:DISTINCT的实际应用
- 查询不同用户:
SELECT DISTINCT username FROM users;可以查询出所有不同的用户名。 - 统计不同产品:
SELECT DISTINCT product_name FROM products;可以统计出所有不同的产品名称。 - 分析不同城市:
SELECT DISTINCT city FROM orders;可以分析出所有不同的订单城市。
通过以上解析,相信大家对SQL中的DISTINCT用法有了更深入的了解,在实际应用中,合理使用DISTINCT可以帮助我们更高效地处理数据,避免重复信息的困扰。
其他相关扩展阅读资料参考文献:
-
DISTINCT的核心作用
DISTINCT用于去除查询结果中的重复行,是SQL中处理数据去重的常用指令,当查询结果中存在多条相同的数据时,使用DISTINCT可以确保每条数据唯一。SELECT DISTINCT name FROM users会返回所有不重复的用户姓名。
DISTINCT作用范围是整个字段或字段组合,而非单个字段,若需按多个字段去重,需在DISTINCT后指定多个字段,如SELECT DISTINCT name, email FROM users,此时系统会将这两列的组合视为唯一标识。
DISTINCT不会改变原始数据,仅影响输出结果,它不会从数据库中删除重复数据,而是仅在查询时过滤,使用DISTINCT时需注意,若需永久去重,应结合DELETE或UPDATE操作。 -
DISTINCT的典型应用场景
去重统计分析:在统计业务数据时,DISTINCT常用于避免重复计数,统计某个月的订单数量,若存在重复订单号,SELECT COUNT(DISTINCT order_id) FROM orders可确保准确计数。
消除冗余数据展示:当需要展示唯一值时,DISTINCT能简化结果集,列出所有不同的产品类别,SELECT DISTINCT category FROM products可直接实现。
关联表去重处理:在多表关联查询中,DISTINCT可避免因关联关系导致的重复行,查询员工及其所属部门,若员工可能属于多个部门,SELECT DISTINCT employee_id, department_name FROM employee_department能确保结果不重复。 -
DISTINCT与GROUP BY的区别
功能差异:DISTINCT用于筛选唯一行,而GROUP BY用于分组聚合。SELECT DISTINCT name FROM users仅返回不同姓名,而SELECT name, COUNT(*) FROM users GROUP BY name会返回每个姓名的出现次数。
性能差异:GROUP BY通常比DISTINCT更高效,因为它在处理数据时会结合聚合函数(如COUNT、SUM)优化执行计划,而DISTINCT仅用于去重,可能需要额外的排序或哈希操作。
使用建议:若仅需去重,优先使用DISTINCT;若需结合聚合函数进行统计,应使用GROUP BY,统计不同地区的销售总额时,SELECT region, SUM(sales) FROM sales_data GROUP BY region比SELECT DISTINCT region, SUM(sales)更合理。
-
DISTINCT的性能优化技巧
避免过度使用DISTINCT:频繁使用DISTINCT可能导致性能下降,尤其是在处理大数据量时。SELECT DISTINCT * FROM large_table会强制对整行进行去重,增加系统开销。
结合索引提升效率:若DISTINCT作用的字段有索引,查询性能会显著提升,在SELECT DISTINCT email FROM users中,若email字段有唯一索引,数据库可直接利用索引快速定位。
优先使用WHERE过滤重复数据:在查询前通过WHERE条件减少重复数据量,可降低DISTINCT的计算压力。SELECT DISTINCT name FROM users WHERE status = 'active'比SELECT DISTINCT name FROM users更高效。
谨慎使用DISTINCT与ORDER BY结合:当DISTINCT与ORDER BY同时使用时,数据库可能需要额外的排序操作,导致性能波动。SELECT DISTINCT name FROM users ORDER BY name会先去重再排序,可能不如先排序后去重高效。 -
DISTINCT的常见误区与注意事项
误以为DISTINCT能部分去重:DISTINCT仅能按字段或字段组合去重,不能单独对某一列进行去重。SELECT DISTINCT name, age FROM users会同时去重name和age的组合,而非单独去重name或age。
忽略NULL值的特殊性:DISTINCT会将NULL视为相同值,导致重复行被过滤。SELECT DISTINCT status FROM orders中,若存在多条NULL状态的订单,系统会将其视为一条记录。
混淆DISTINCT与ROW_NUMBER函数:DISTINCT仅用于去重,而ROW_NUMBER用于生成唯一序号。SELECT name, ROW_NUMBER() OVER (ORDER BY name) FROM users会为每条记录分配序号,而非去重。
避免DISTINCT与聚合函数混用:在需要统计唯一值时,应优先使用COUNT(DISTINCT column)而非DISTINCT结合COUNT。SELECT COUNT(DISTINCT order_id) FROM orders比SELECT COUNT(*) FROM (SELECT DISTINCT order_id FROM orders)更高效。
注意DISTINCT的字段顺序:DISTINCT的字段顺序会影响去重结果。SELECT DISTINCT name, age FROM users与SELECT DISTINCT age, name FROM users的去重逻辑相同,但实际执行可能因数据库优化策略不同而有差异。
DISTINCT是SQL中处理数据去重的基础工具,但其使用需结合具体场景和性能需求,在实际开发中,应优先理解其作用范围和语法特性,避免因误用导致性能问题或逻辑错误,注意与GROUP BY、ROW_NUMBER等其他功能的区别,合理选择工具以提升查询效率,掌握这些技巧后,DISTINCT将成为优化数据处理流程的得力助手。
“sql distinct用法,SQL中Distinct关键字的应用与优势” 的相关文章

源程序文件是什么意思,源程序文件的定义与解读
源程序文件,通常指的是包含计算机程序原始代码的文件,这些代码是由程序员使用编程语言编写的,用于指导计算机执行特定任务,源程序文件不直接执行,需要通过编译器或解释器将其转换为机器码或字节码,才能被计算机理解并执行,C语言源程序文件以.c为扩展名,而Python的源程序文件则以.py 嗨,我最近在学习...

insert into 语句写法,SQL插入语句(INSERT INTO)使用指南
INSERT INTO 语句用于向数据库表添加新记录,其基本写法如下:,``sql,INSERT INTO table_name (column1, column2, column3, ...),VALUES (value1, value2, value3, ...);,`,这里,table_nam...
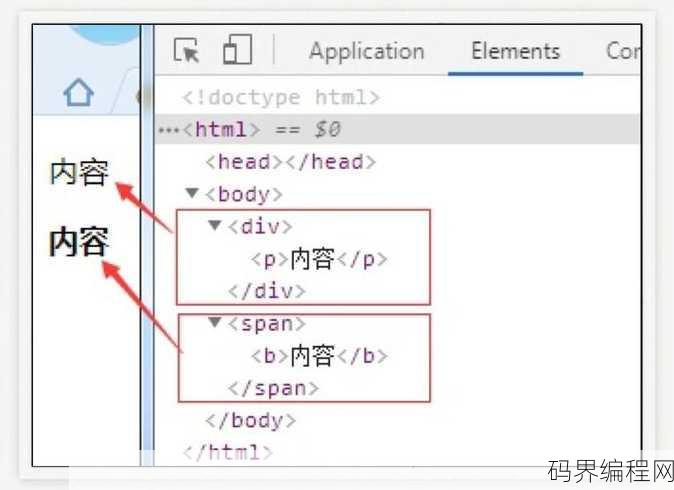
html中div的用法,HTML中div元素的应用指南
HTML中,div元素被广泛用于网页布局中,它是一个容器,可以包含文本、图片、列表等多种内容,div标签没有固定的意义,它主要是作为一个容器来组织其他HTML元素,通过CSS样式,可以对div进行定位、设置宽高、边框等样式,从而实现网页布局,使用div可以将页面分为头部、中部、尾部等区域,或实现左右...
jquery插件开发方法,jQuery插件开发实战指南
jQuery插件开发方法主要包括以下步骤:了解jQuery核心功能和插件模式;创建一个插件的基本结构,包括定义插件名称、构造函数和默认选项;通过$.fn对象扩展插件,利用选择器和方法来操作DOM;根据需要添加自定义方法和事件处理;进行测试和优化,确保插件稳定性和兼容性,开发过程中需注意代码的可读性和...

jelly bean是什么意思,Jelly Bean的含义揭秘
Jelly Bean通常指的是一种软糖豆,其外层是果冻质地,内含果汁或果酱,口感Q弹,在网络语境中,Jelly Bean也常被用作软件版本代号,如Android操作系统中的“Jelly Bean”指的是Android 4.1至4.3版本,以这种糖果的名称命名。 嗨,我最近在网上看到一个词“jell...

cssci和sci区别,CSSCI与SCI期刊差异对比
CSSCI(中国社会科学引文索引)和SCI(科学引文索引)都是重要的学术文献数据库,CSSCI主要收录我国人文社会科学领域的核心期刊,强调学术质量和影响力;而SCI则收录自然科学领域的核心期刊,侧重于国际学术交流和影响力,两者在收录范围、评价标准和应用领域上存在显著差异,CSSCI更侧重于国内学术研...
- 最新发布
-
2分钟前

5分钟前
13分钟前
19分钟前
27分钟前
- 热门阅读
-

918 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言