python爬虫下载,Python爬虫实战,高效下载网页内容技巧
Python爬虫下载通常涉及使用Python内置库如requests获取网页内容,以及BeautifulSoup或lxml解析HTML结构,用户需先确定目标网站的数据结构和规则,然后编写代码发送HTTP请求,提取所需数据,最后保存到本地文件,下载过程可能包括处理反爬虫机制,如设置请求头、使用代理等,还需注意遵守网站的使用条款和版权法规。
Python爬虫下载:轻松掌握网络数据采集技能
用户解答:
最近我在网上看到很多关于Python爬虫下载的内容,想学习一下,但是对这方面的知识了解不多,不知道从何入手,请问一下,Python爬虫下载到底是怎么回事?有哪些方法可以实现呢?

下面,我将从Python爬虫下载的原理、常用库、实战案例等方面进行的讲解,帮助大家轻松掌握网络数据采集技能。
Python爬虫下载原理
- 网络请求:爬虫首先需要向目标网站发送HTTP请求,获取网页内容。
- 网页解析:爬虫对获取到的网页内容进行解析,提取所需数据。
- 数据存储:将解析得到的数据存储到本地文件或数据库中。
Python爬虫下载常用库
- requests:用于发送HTTP请求,获取网页内容。
- BeautifulSoup:用于解析HTML和XML文档,提取所需数据。
- Scrapy:一个强大的爬虫框架,可以轻松实现复杂爬虫任务。
Python爬虫下载实战案例
-
下载网页图片:
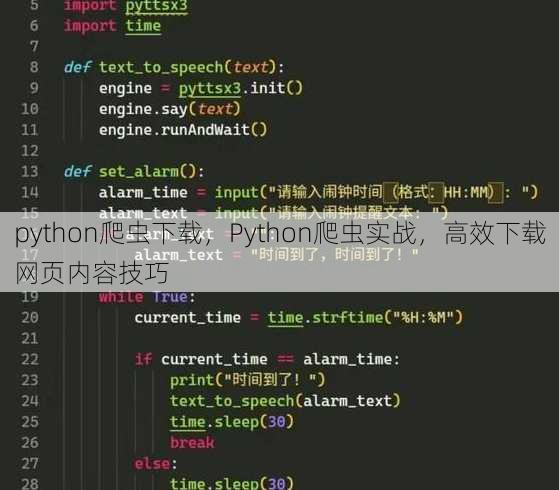
-
代码:
import requests from bs4 import BeautifulSoup url = 'https://example.com/images' response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') for img in soup.find_all('img'): img_url = img.get('src') img_name = img_url.split('/')[-1] img_data = requests.get(img_url).content with open(img_name, 'wb') as f: f.write(img_data) -
解析:首先发送请求获取网页内容,然后使用BeautifulSoup解析网页,找到所有图片标签,获取图片URL,并下载图片。
-
-
下载网页视频:
-
代码:
import requests from bs4 import BeautifulSoup url = 'https://example.com/videos' response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') for video in soup.find_all('video'): video_url = video.get('src') video_name = video_url.split('/')[-1] video_data = requests.get(video_url).content with open(video_name, 'wb') as f: f.write(video_data) -
解析:与下载图片类似,首先发送请求获取网页内容,然后使用BeautifulSoup解析网页,找到所有视频标签,获取视频URL,并下载视频。

-
-
下载网页文档:
-
代码:
import requests url = 'https://example.com/documents' response = requests.get(url) with open('document.pdf', 'wb') as f: f.write(response.content) -
解析:发送请求获取网页内容,然后直接将内容写入本地文件。
-
Python爬虫下载注意事项
- 遵守网站规则:在下载网站数据时,务必遵守目标网站的robots.txt规则,避免对网站造成不必要的压力。
- 避免频繁请求:合理设置爬虫的请求频率,避免对目标网站造成过大压力。
- 处理异常情况:在爬虫运行过程中,可能会遇到各种异常情况,如网络错误、解析错误等,需要提前做好异常处理。
通过以上讲解,相信大家对Python爬虫下载有了更深入的了解,掌握Python爬虫下载技能,可以帮助我们轻松获取网络数据,为后续的数据分析和处理提供有力支持,祝大家学习愉快!
其他相关扩展阅读资料参考文献:
Python爬虫下载:入门与实践
爬虫技术简介
Python爬虫是一种通过编写程序来自动获取互联网资源的技术,随着互联网的快速发展,信息量的爆炸式增长,爬虫技术成为了数据收集、分析和处理的重要手段,本文将介绍Python爬虫下载的基础知识、常用库和实战技巧。
Python爬虫下载一:基础概念与工具
Python爬虫定义 Python爬虫是一种基于Python语言的网络数据抓取工具,通过模拟浏览器行为,自动获取网页内容。 常用库介绍 如Requests库用于发送网络请求,BeautifulSoup库用于解析HTML文档,Scrapy框架用于构建强大的爬虫应用。 爬虫工作原理 爬虫通过发送HTTP请求获取网页内容,然后解析HTML文档,提取所需数据。
Python爬虫下载二:核心技术与实现
发送网络请求 使用Requests库可以方便地发送网络请求,获取网页内容。 HTML解析 通过BeautifulSoup库可以方便地解析HTML文档,提取数据。 爬取策略设计 根据目标网站的结构和特点,设计合适的爬取策略,如深度优先搜索、广度优先搜索等。 数据存储 爬取的数据可以存储在本地文件、数据库或云端存储中。
Python爬虫下载三:实战案例与技巧
爬取图片资源 通过爬虫技术可以方便地爬取网页上的图片资源,并进行下载保存。 应对反爬虫策略 部分网站会采取反爬虫策略,如设置验证码、限制访问频率等,需要采取相应措施进行应对。 多线程与分布式爬虫 为了提高爬取效率,可以采用多线程和分布式爬虫技术。 持久性与稳定性优化 对于长期运行的爬虫应用,需要考虑持久性与稳定性问题,如数据备份、错误处理等。
Python爬虫下载四:法律法规与道德伦理
遵守法律法规 在进行爬虫下载时,必须遵守相关法律法规,尊重网站版权和隐私保护。 注意道德伦理问题 避免对网站造成不必要的负担,合理、合法地使用爬虫技术。 合理使用反爬虫策略 在应对反爬虫策略时,应尊重网站规则,避免过度干扰网站正常运营。
Python爬虫下载是一项强大的技术,可以帮助我们快速获取互联网资源,通过本文的介绍,希望读者对Python爬虫下载有了更深入的了解,并能在实际应用中发挥其价值,在使用过程中,请务必遵守法律法规和道德伦理规范。
“python爬虫下载,Python爬虫实战,高效下载网页内容技巧” 的相关文章

hoverfly,探索Hoverfly,下一代网络数据监控工具
Hoverfly是一种昆虫,属于膜翅目,与蜜蜂和黄蜂有亲缘关系,它们通常体型较小,翅膀透明,飞行时呈摇晃状,Hoverflies以花蜜为食,对植物授粉有重要作用,它们还是捕食其他小昆虫的天敌,有助于生态平衡,在我国,hoverfly种类繁多,分布广泛。用户提问:大家好,我想了解一下hoverfly是...

鸿蒙中文编程,探索鸿蒙操作系统下的中文编程奥秘
鸿蒙中文编程是一种创新的语言学习方式,旨在帮助用户快速掌握中文编程技能,通过独特的教学方法,结合现代编程理念,用户可以轻松理解并运用中文编程语法,实现编程思维与中文表达的有机结合,此方法适用于各年龄段的学习者,旨在提高编程效率和跨文化交流能力。开启智能设备的编程新纪元 作为一名科技爱好者,我最...

开发一个聊天软件需要多少钱,开发聊天软件的成本分析概览
开发一个聊天软件的成本取决于多种因素,包括功能需求、技术选型、开发团队规模和地区等,基础版本的开发成本可能在几万元到几十万元人民币不等,而包含高级功能和复杂架构的聊天软件,成本可能高达数百万元,具体预算需要根据项目细节和预期质量进行详细评估。开发一个聊天软件需要多少钱?这个问题对于想要创业或者正在考...
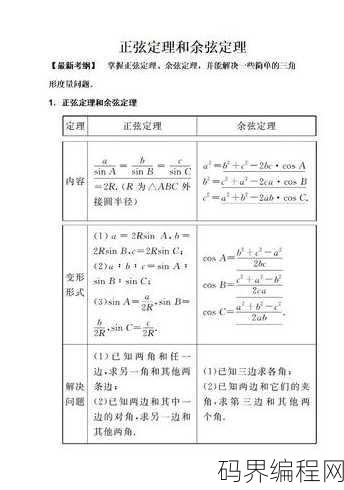
正弦定理和余弦定理,正弦定理与余弦定理解析
正弦定理和余弦定理是解析几何中用于计算三角形边长和角度的公式,正弦定理指出,在任何三角形中,各边与其对应角的正弦值之比相等,余弦定理则提供了边长与角度之间的关系,表明在任何三角形中,一个角的余弦值等于其他两边长度的平方和减去该边长度平方的两倍,再除以这两边长度乘积的两倍,这两个定理在解决几何问题、工...
平板c+编程软件,平板C+编程软件,轻松实现移动编程体验
平板C++编程软件是一款专为平板设备设计的C++编程环境,支持代码编写、编译和调试,它具备丰富的编程工具和库,便于开发者进行移动端应用开发,软件界面友好,操作便捷,支持多种编译器和平台,适合编程初学者和专业人士使用。平板C++编程软件:移动办公的得力助手 用户解答: “嗨,我是一名软件工程师,最...

编程游戏有哪些,编程游戏大盘点
编程游戏是一种结合了编程教育和娱乐的互动形式,旨在通过游戏化的方式帮助用户学习编程技能,以下是一些流行的编程游戏:,1. **Scratch**:一个图形化编程平台,适合儿童和初学者,通过拖放积木式的编程块来创造动画和游戏。,2. **Code Combat**:通过完成各种编程任务和战斗挑战来学习...
- 最新发布
-
4分钟前
11分钟前

17分钟前
24分钟前

32分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言