数据库范式判断技巧,数据库范式快速判断指南
数据库范式判断技巧主要包括以下步骤:识别出数据表中的主键和候选键;分析数据表中的函数依赖关系,确定范式级别;对数据表进行分解,消除部分函数依赖、传递函数依赖和冗余数据;验证分解后的数据表是否满足更高一级的范式要求,掌握这些技巧有助于优化数据库设计,提高数据存储的效率和准确性。
数据库范式判断技巧——轻松掌握数据库设计要点
作为一名数据库开发者,你是否曾在面对复杂的数据库设计时感到困惑?是否曾经为了判断数据库范式而绞尽脑汁?就让我来为大家揭秘数据库范式的判断技巧,帮助大家轻松掌握数据库设计要点。
真实用户解答:
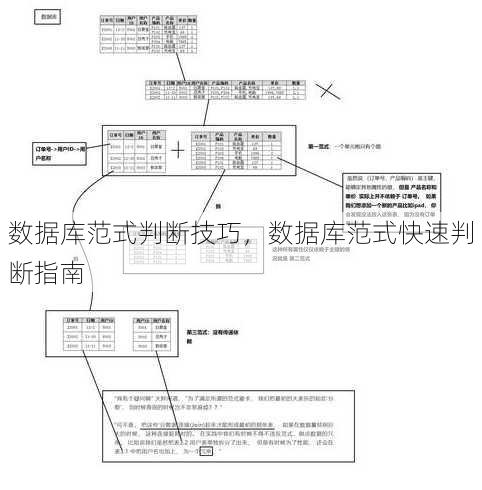
小张:我最近在学习数据库设计,但是在判断范式时总是觉得有些困难,能否分享一下你的经验?
什么是数据库范式?
我们需要明确什么是数据库范式,数据库范式是数据库设计的重要原则,用于指导如何组织数据库中的数据,以减少数据冗余和提高数据的一致性,数据库范式主要分为以下几个层次:
- 第一范式(1NF):保证数据表中所有列都是原子性的,即不可再分。
- 第二范式(2NF):在满足第一范式的基础上,非主键列必须完全依赖于主键。
- 第三范式(3NF):在满足第二范式的基础上,非主键列不依赖于其他非主键列。
- BCNF(Boyce-Codd范式):在满足第三范式的基础上,非主键列必须直接依赖于主键。
判断数据库范式的技巧
- 检查列的原子性:确保数据表中所有列都是原子性的,不可再分,一个学生的年龄字段应该是整数,而不是“12岁”这样的字符串。
- 确定主键:找出数据表中的主键,并确保所有非主键列都依赖于主键。
- 检查非主键列之间的依赖关系:确保非主键列不依赖于其他非主键列。
- 分析数据表之间的关系:观察数据表之间的关系,确保它们满足范式的要求。
一:第一范式(1NF)
- 检查数据完整性:确保所有列都是原子性的,没有重复的数据。
- 避免冗余:避免存储重复的数据,如将学生姓名和年龄分别存储在不同的列中。
- 数据独立性:提高数据独立性,方便后续的数据修改和扩展。
二:第二范式(2NF)
- 主键的选择:选择合适的列作为主键,确保所有非主键列都依赖于主键。
- 消除部分依赖:避免非主键列对主键的部分依赖,如将学生姓名和年龄放在同一张表中,但姓名不作为主键。
- 数据一致性:确保数据的一致性,避免数据冗余和不一致。
三:第三范式(3NF)
- 消除传递依赖:确保非主键列不依赖于其他非主键列,如将学生姓名和班级放在不同的表中。
- 提高数据冗余度:降低数据冗余度,提高数据存储效率。
- 优化查询性能:优化查询性能,提高数据库的运行效率。
四:BCNF
- 检查非主键列的依赖关系:确保非主键列直接依赖于主键,没有传递依赖。
- 优化数据表结构:优化数据表结构,提高数据库的运行效率。
- 降低数据冗余:降低数据冗余,提高数据存储效率。
通过以上技巧,相信大家已经对数据库范式的判断有了更深入的了解,在实际工作中,我们应根据具体需求选择合适的范式,以确保数据库设计的合理性和高效性。
其他相关扩展阅读资料参考文献:

理解范式的定义与核心目标
- 范式是数据库设计的规范化标准
范式(Normalization Form)是通过消除数据冗余和逻辑矛盾,确保数据库结构合理化的数学理论,其核心目标是提高数据一致性、简化数据维护,并减少存储空间浪费。第一范式(1NF)要求所有字段都是原子性的,即不可再分,若一个字段存储了多个电话号码,需拆分为独立的记录。 - 范式的层级划分与实际意义
数据库设计通常遵循1NF到BCNF(Boyce-Codd范式)的逐步规范过程。第二范式(2NF)强调消除部分依赖,确保非主属性完全依赖于主键,订单表中若存在“客户地址”字段,且客户地址仅与订单编号相关,而非订单明细,需拆分表结构。 - 高范式并非唯一目标
第三范式(3NF)要求非主属性之间无传递依赖,但实际设计中需权衡量范式与性能的平衡,频繁查询的字段可能因过度规范化导致连接操作复杂,需根据业务需求灵活调整。
范式判断的三大核心原则
- 原子性原则:确保字段不可再分
判断是否符合1NF时,需检查所有字段是否为基本数据类型,若存在复合字段(如“姓名+电话”),应拆分为独立字段。例如:将“用户信息”表中的“地址”字段拆分为“省”“市”“区”“邮编”四个独立字段,避免冗余存储。 - 依赖消除原则:避免冗余与矛盾
判断是否符合2NF或3NF时,需分析数据依赖关系。若非主属性部分依赖主键(如订单表中“客户姓名”仅依赖订单编号而非订单明细),需将表拆分为“订单”和“客户”两个表。若存在传递依赖(如“员工表”中“部门经理姓名”依赖“部门编号”),应将“部门经理姓名”单独存储到“部门”表中。 - 函数依赖合理化原则:优化数据关联
判断函数依赖是否合理需关注主键与非主属性的关系。例如:在“课程表”中,若“课程编号”是主键,“课程名称”和“授课教师”均依赖主键,则符合3NF,但若“授课教师”依赖“课程名称”而非主键,则需调整表结构,确保依赖关系直接指向主键。
范式设计的常见误区与避坑指南
- 过度规范化导致性能下降
过度追求高范式可能增加表关联复杂度,影响查询效率。例如:将“用户订单”表拆分为“用户”“订单”“订单明细”三层结构,虽符合3NF,但高频查询可能需要通过反范式化(如冗余字段)优化。 - 忽视业务场景的特殊需求
范式设计需结合业务逻辑。例如:在“库存管理”系统中,若同一商品可能有多个供应商,且供应商信息需频繁更新,多值依赖(如“商品-供应商”关系)需通过建立关联表而非冗余字段处理。 - 依赖传递的误判可能引发数据冗余
误判传递依赖可能导致错误拆分。例如:在“员工-部门-经理”关系中,若“经理姓名”依赖“部门编号”而非“员工编号”,需将“经理”单独设计为表,避免“经理姓名”重复存储。 - 未识别多值依赖导致数据不一致
多值依赖是违反BCNF的关键点。例如:在“学生-课程-成绩”表中,若“课程”和“成绩”同时依赖“学生编号”,但“课程”与“成绩”之间存在独立关系,需拆分表结构,避免同一学生因多课程导致成绩字段冗余。 - 忽略性能与范式的平衡
高范式设计可能牺牲性能。例如:在“日志系统”中,若频繁查询历史记录,反范式化(如将时间戳与日志内容合并)可减少连接操作,但需通过索引或缓存机制保障数据一致性。
范式判断的实战应用技巧
- 订单管理系统:从1NF到3NF的拆分实践
原始订单表可能包含“订单编号”“商品名称”“单价”“数量”“总价”字段。判断步骤:- 检查“商品名称”“单价”是否原子性(符合1NF);
- 分析“总价”是否依赖于“订单编号”(符合2NF);
- 拆分“商品名称”与“单价”为独立表,避免同一商品在不同订单中重复存储(符合3NF)。
- 用户信息表:消除冗余字段的优化方法
若用户表中存在“用户地址”“用户电话”等字段,需判断是否符合1NF。解决方法:- 将“地址”拆分为“省”“市”“区”“邮编”;
- 将“电话”拆分为“固定电话”“手机号”;
- 若用户地址与订单地址无关,需进一步拆分到独立表。
- 库存管理中的多值依赖处理
若库存表中“商品-供应商”关系存在多值依赖,需建立关联表。例如:- 原始表:商品编号、商品名称、供应商1、供应商2、供应商3;
- 优化后:商品表(商品编号、商品名称)、供应商表(供应商编号、供应商名称)、库存关联表(商品编号、供应商编号、库存数量)。
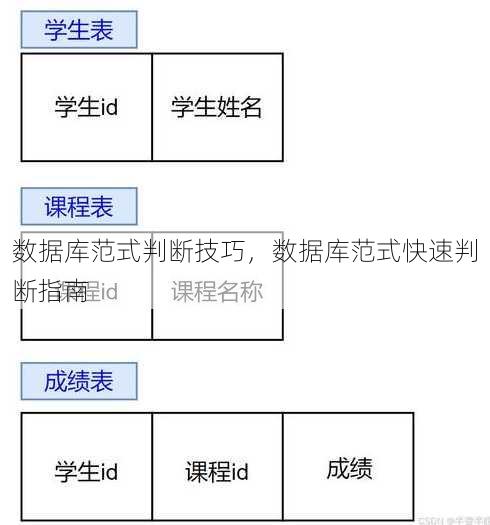
- 学生成绩表的范式分析
学生成绩表可能包含“学号”“课程编号”“成绩”“课程名称”“授课教师”字段。判断步骤:- 检查“课程名称”“授课教师”是否依赖于“课程编号”(符合2NF);
- 拆分“课程名称”“授课教师”到独立表,避免成绩表中冗余存储(符合3NF);
- 若“课程名称”与“授课教师”存在直接依赖,需进一步分析是否符合BCNF。
- 性能与范式的动态平衡策略
在高并发场景下,反范式化可提升查询效率。例如:- 将“用户订单”表中的“用户姓名”作为冗余字段存储,减少关联查询;
- 通过索引优化主键查询,避免全表扫描;
- 使用视图或物化视图在保持范式化的同时满足业务需求。
范式判断的工具与验证方法
- ER图工具辅助分析数据关系
使用ER图(实体-关系图)可直观展示实体间的依赖关系。例如:通过工具识别“订单”与“商品”之间的多对多关系,避免设计为多值依赖。 - 数据库约束条件验证范式合规性
通过设置主键、外键和唯一约束,可强制数据符合范式要求。例如:在“用户-订单”表中,若“用户编号”为外键,且“订单编号”为主键,需确保非主属性完全依赖主键。 - SQL查询分析冗余与矛盾
通过执行SQL查询,可发现冗余数据或逻辑矛盾。例如:若查询“订单”表时需要多次关联“商品”表,说明存在2NF违规;若“商品名称”在不同订单中重复存储,需拆分到独立表。 - 数据字典与业务规则校验
数据字典记录字段的定义与依赖关系,需与业务规则对比。如:若业务规则要求“用户地址”与“订单地址”独立,需拆分到不同表。 - 自动化工具检测范式问题
使用数据库设计工具(如MySQL Workbench、ER/Studio)可自动检测范式违规。例如:工具提示“存在传递依赖”,需调整表结构以满足3NF要求。
范式判断是数据库设计的核心环节,需结合原子性、依赖消除、合理化三大原则,避免过度规范化、误判依赖、忽视业务需求等误区,通过ER图、约束条件、SQL查询、数据字典等工具,可高效验证范式合规性,实际应用中,需动态平衡范式化与性能需求,确保数据库既符合理论规范,又能满足业务场景的高效运行。记住:范式并非绝对标准,而是指导设计的工具,灵活运用才能实现最佳效果。
“数据库范式判断技巧,数据库范式快速判断指南” 的相关文章

w3cshool,探索W3Cschool,编程学习新平台
W3Schools是一个提供丰富的Web开发资源和教程的网站,它涵盖HTML、CSS、JavaScript、jQuery、SQL、PHP、Python等多种编程语言和框架,用户可以在这里找到详细的学习资料,包括基础教程、参考手册、在线练习等,适合不同水平的开发者学习和提高技能。W3Schools——...
php难吗自学要多久,自学PHP需要多久?挑战难度揭秘
PHP是一门相对容易上手的编程语言,适合初学者,自学PHP的难度取决于个人基础和投入时间,具备一定编程基础的人,通过系统的学习,大约需要3-6个月的时间可以掌握PHP的基本语法和开发技能,如果是从零开始,时间可能会更长,自学过程中,建议结合实际项目练习,这样可以更快地提高。 嗨,大家好!我最近在自...

三角函数懒人计算器,智能三角函数快速计算助手
三角函数懒人计算器是一款便捷的工具,旨在简化三角函数的计算过程,用户只需输入角度或边长,即可快速得到正弦、余弦、正切等三角函数的值,无需手动计算,节省时间和精力,特别适合学习、工程和科研等领域使用。嗨,大家好!我是一名高中生,最近在学习三角函数时,发现这个数学分支既神奇又有点头疼,尤其是在计算一些复...
海洋cms模板,海洋风CMS模板,打造个性化海洋主题网站
海洋CMS模板是一款专为海洋主题网站设计的网站建设模板,它以蓝色海洋为主题,融合现代设计元素,提供丰富的布局和功能模块,支持多种设备自适应,模板内置响应式设计,确保在不同屏幕尺寸下都能保持良好的视觉效果,海洋CMS模板还具备强大的后台管理功能,便于用户轻松管理和更新内容,适用于海洋旅游、海洋生物研究...
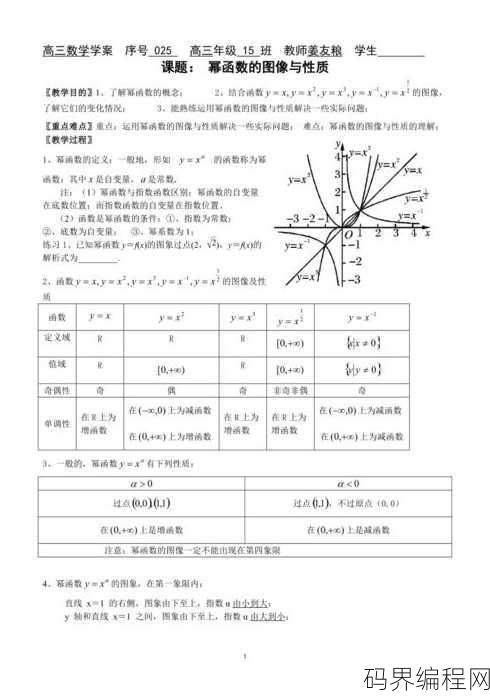
常见幂函数的图像及性质,解析常见幂函数,图像与性质全解析
常见幂函数主要包括形如 \( f(x) = x^n \) 的函数,\( n \) 为实数,这些函数的图像和性质如下:,1. 当 \( n \) 为正整数时,函数在 \( x ˃ 0 \) 时单调递增,在 \( x 0 \) 时单调递减,在 \( x 0 \) 时单调递增,在 \( x 0 \)...

c语言满屏飘红色爱心代码,C语言实现满屏飘动红色爱心效果
这是一段用C语言编写的代码,它可以在屏幕上实现满屏飘动红色爱心的效果,代码通过循环和字符打印技术,在控制台或终端中动态地显示红色的爱心图案,模拟爱心在屏幕上飘动的动画效果,程序运行后,用户将看到一系列红色的爱心在屏幕上连续出现,形成一种视觉上的动态美感。 大家好,我最近在学C语言,想实现一个满屏飘...
- 最新发布
-
8秒前
7分钟前

15分钟前

21分钟前

29分钟前
- 热门阅读
-

903 浏览学习方法

242 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言