regex正则表达式,掌握正则表达式,高效文本处理的艺术
正则表达式(regex)是一种用于匹配字符串中字符组合的模式,它广泛应用于文本搜索、验证、替换等场景,通过定义一系列字符和规则,正则表达式能够高效地处理复杂的字符串操作,如查找特定格式、提取关键信息等,掌握正则表达式,能显著提高数据处理效率。
嗨,我最近在学习编程,遇到了一个难题,就是如何使用正则表达式来处理字符串,我听说正则表达式很强大,但是看了一些资料后,还是不太明白它的用法,你能帮我解释一下正则表达式的概念,还有它的一些基本用法吗?
一:正则表达式的概念
什么是正则表达式? 正则表达式(Regular Expression,简称Regex)是一种用于处理字符串的强大工具,它可以用来匹配、查找、提取和替换字符串中的特定模式。
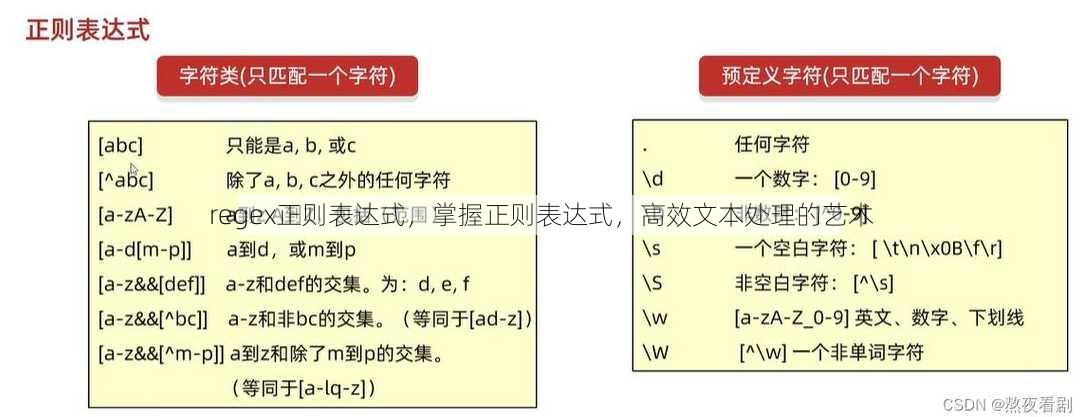
正则表达式的用途
- 数据验证:验证用户输入是否符合特定格式,如邮箱、电话号码等。
- 文本处理:从大量文本中提取或替换特定信息。
- 文件搜索:在文件系统中搜索包含特定模式的文件。
正则表达式的组成部分
- 字符:包括字母、数字、符号等。
- 元字符:具有特殊含义的字符,如、、、等。
- 量词:用于指定匹配次数,如表示匹配0次或多次,表示匹配1次或多次。
- 分组和引用:将多个字符组合成一组,并可以在后续的匹配中使用该组。
二:正则表达式的入门语法
基本字符匹配
- :匹配除换行符以外的任意单个字符。
[]:匹配方括号内的任意一个字符,例如[abc]匹配a、b或c。
量词的使用
- :匹配前面的子表达式0次或多次。
- :匹配前面的子表达式1次或多次。
- :匹配前面的子表达式0次或1次。
元字符的转义

- 如果需要匹配元字符本身,需要在元字符前加上反斜杠
\进行转义,例如\.匹配点号。
分组和引用
- :用于分组子表达式,以便可以在后续的匹配中使用。
\1、\2等:引用分组中的内容,用于匹配分组内的模式。
三:正则表达式的进阶技巧
贪婪匹配与懒惰匹配
- 贪婪匹配:默认情况下,正则表达式会尽可能多地匹配字符。
- 懒惰匹配:通过在量词后面加上,可以实现懒惰匹配,即尽可能少地匹配字符。
分支结构
- :用于指定多个可选的匹配模式,例如
a|b匹配a或b。
重复结构
{n}:匹配前面的子表达式恰好n次。{n,}:匹配前面的子表达式至少n次。{n,m}:匹配前面的子表达式至少n次,但不超过m次。
四:正则表达式的性能优化
避免使用贪婪匹配

- 在可能的情况下,使用懒惰匹配来提高正则表达式的性能。
使用字符集
- 使用字符集可以减少匹配的次数,提高效率。
预编译正则表达式
- 在多次使用同一正则表达式时,预编译可以提高性能。
五:正则表达式的实际应用案例
验证邮箱地址
- 正则表达式:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ - 用途:用于验证用户输入的邮箱地址是否符合标准格式。
提取网页中的电话号码
- 正则表达式:
\b\d{3}[-.]?\d{3}[-.]?\d{4}\b - 用途:用于从网页中提取电话号码。
替换文本中的特定单词
- 正则表达式:
\bword\b - 用途:用于将文本中的特定单词替换为另一个单词。
通过以上对正则表达式的讲解,相信你已经对它有了更全面的了解,正则表达式确实是一种强大的文本处理工具,掌握了它,你的编程能力将得到很大提升。
其他相关扩展阅读资料参考文献:
正则表达式基础语法
-
*普通字符直接匹配,特殊字符如.、、+有特殊含义*
正则表达式的核心是字符匹配,普通字符(如a、b、数字)直接代表自身,而特殊字符则具有特定功能,匹配任意单个字符,`表示前一个字符重复零次或多次,+`表示至少一次重复,掌握这些基础符号是使用正则的第一步。 -
量词与边界条件需精准控制
量词(如{n}、{n,}、{n,m})用于指定重复次数,边界条件(如^、)确保匹配范围。^abc匹配以"abc"开头的字符串,$xyz匹配以"xyz"结尾的字符串,错误使用可能导致匹配结果不准确,甚至遗漏关键信息。 -
分组与捕获实现复杂逻辑
通过将多个字符组合为一个单元,分组可实现逻辑分层,捕获组(如(\d{3})-(\d{3}))能提取子串,而非捕获组()仅用于分组而不提取,分组是处理嵌套结构或提取特定字段的关键工具。
正则表达式的实际应用场景
-
表单验证:快速校验输入格式
正则常用于前端或后端表单验证,例如验证邮箱格式:^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$,通过正则可避免手动检查,提升用户体验和数据准确性。 -
日志解析:从文本中提取关键信息
日志文件通常包含时间戳、IP地址、请求路径等信息,提取IP地址:\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3},正则能高效定位并解析日志中的特定字段,便于分析和监控。 -
文本替换:自动化修改内容
正则支持模式匹配替换,例如将所有电话号码格式化:(\d{3})-(\d{3})-(\d{4})→$1.$2.$3,通过正则替换,可批量处理文本中的重复性修改任务,节省时间成本。 -
数据提取:从复杂文本中抓取目标内容
正则的捕获组功能能精准提取所需数据,从HTML标签中提取内容:<div>(.*?)</div>,通过正则,可快速从海量文本中提取结构化数据,如价格、日期等关键信息。 -
模式匹配:识别文本中的特定规律
正则擅长识别重复性规律,例如匹配连续三个数字:\d{3},通过模式匹配,可快速定位文本中的异常或符合规则的部分,广泛应用于数据清洗和格式校验。
正则表达式的进阶技巧
-
正向预查与反向预查避免冗余匹配
正向预查()确保匹配前有特定内容,反向预查((?<=...))确保匹配后有特定内容,匹配以"abc"开头且不包含"xyz"的字符串:^abc(?!.*)xyz.*,这种技巧能避免误匹配,提升正则的精确度。 -
原子组与条件表达式优化匹配逻辑
原子组((?>(...)))防止部分匹配,例如匹配完整的URL:https?://(?:www\.)?[^/\s]+,条件表达式((?i)...)可设置匹配模式,如忽略大小写或仅匹配数字,这些技巧能简化复杂逻辑,减少错误。 -
零宽断言实现位置匹配
零宽断言(如)用于匹配位置而非字符,匹配单词边界:\bword\b,这种技巧能精准定位文本中的特定位置,常用于分词或关键词搜索。 -
使用备选方案提升灵活性
通过符号实现多个模式的或关系,例如匹配电话号码或邮箱:^(13[0-9]|15[0-9]|18[0-9])\d{8}$,备选方案能覆盖更多场景,但需注意优先级问题。 -
结合字符集与范围匹配提高效率
字符集(如[a-zA-Z])和范围匹配(如\d{3})能缩小匹配范围,匹配中文字符:[\u4e00-\u9fa5],合理使用这些技巧可减少不必要的匹配步骤,提升性能。
正则表达式的性能优化
-
避免贪婪匹配减少资源消耗
贪婪量词(如、)会尽可能匹配更多内容,可能导致性能问题,用替代可实现非贪婪匹配,提高匹配效率。 -
预编译正则提升执行速度
在编程中,预编译正则表达式(如使用re.compile())可避免重复解析,提升执行效率,Python中:pattern = re.compile(r'\d{3}')。 -
限制匹配范围防止无限循环
通过{n,m}限定重复次数,例如匹配3到5位数字:\d{3,5},不设置范围可能导致正则陷入无限循环,影响程序运行。 -
优先使用简单模式降低复杂度
复杂正则可能降低性能,例如用[0-9]{3}替代\d{3},简化模式能减少计算量,提升匹配速度。 -
避免重复使用捕获组
过多的捕获组会增加内存消耗,例如用非捕获组替代不必要的捕获,优化捕获组使用可减少资源占用。
正则表达式的常见误区
-
过度依赖正则导致代码可读性下降
复杂正则可能让代码难以维护,建议将复杂逻辑拆分为多个步骤,用函数封装重复使用的正则片段。 -
忽略边界条件引发匹配错误
未使用^和可能导致匹配部分子串而非整个字符串。abc可能匹配"abc123"中的"abc",而非整个字符串。 -
错误使用转义符引发语法冲突
特殊字符(如、)需转义(\.、\*)才能匹配字面量,忽略转义可能导致正则解析错误。 -
混淆捕获组与非捕获组功能
捕获组()会提取内容,而非捕获组()不提取,混淆两者会导致数据丢失或误用。 -
不处理异常情况引发程序崩溃
正则可能匹配到空值或无效内容,需添加异常处理(如try...except),Python中处理无效正则时需捕获re.error异常。
正则表达式是处理文本数据的利器,但其强大功能也伴随着复杂性,掌握基础语法、理解应用场景、灵活运用进阶技巧、注重性能优化、避免常见误区,才能真正释放正则的潜力,无论是开发、数据分析还是自动化处理,正则都能成为高效工具,但需理性使用,避免过度依赖。合理规划正则逻辑,才能让数据解析更精准、更高效。
“regex正则表达式,掌握正则表达式,高效文本处理的艺术” 的相关文章

苹果javascript要不要开,苹果设备上是否需要开启JavaScript功能?
苹果的JavaScript是否需要开启取决于具体的应用场景和需求,如果你开发的是基于Web的应用,并且需要在iOS设备上运行,通常需要开启JavaScript支持,因为许多Web功能和交互都依赖于JavaScript,如果你使用的是苹果的原生开发框架(如Swift或Objective-C),并且不需...
rebase,掌握Git rebase,代码合并的艺术与实践
Rebase 是一种在版本控制系统中,特别是Git中,用于更新分支的技巧,它通过将当前分支的更改合并到另一个分支上,来同步两个分支的最新提交,这有助于保持分支的整洁和一致性,防止历史记录的混乱,在rebase过程中,开发者需要解决合并时可能出现的冲突,以确保代码的正确性,简而言之,rebase是管理...

dw软件官方免费版,DW软件免费官方版下载指南
DW软件官方免费版是一款由Adobe公司开发的网页设计与开发工具,它支持HTML、CSS、JavaScript等多种编程语言,提供丰富的可视化界面设计功能,用户可以通过免费版轻松实现网页布局、样式调整、代码编写等操作,适合初学者和有一定基础的网页开发者使用,免费版还提供在线教程和社区支持,助力用户提...
精品网站模板免费下载,免费获取,精选网站模板下载大全
本平台提供丰富多样的精品网站模板,涵盖多种风格和行业需求,用户可免费下载这些高质量模板,轻松应用于个人或商业项目,节省设计成本,提升网站建设效率,立即访问,开启您的个性化网站之旅。 嗨,大家好!最近我在找一些免费的网站模板,想自己动手做一个个人博客或者小型企业网站,我发现网上很多免费模板质量参差不...

beanpole什么意思中文,beanpole的中文意思,豆芽杆,细长的人。
"Beanpole"在中文中的意思是“细长的人”或“瘦高个”,这个词汇通常用来形容那些身材高挑且相对较瘦的人,它也可以用来比喻某个物体或结构细长而高,在非正式语境中,有时也会带有轻微的贬义,暗示某人可能因为过于瘦弱而显得不健康或不强壮。 嘿,我最近在跟一个外国朋友聊天,他提到“beanpole”这...

web前端面试官常问的问题,Web前端面试常见问题汇总
Web前端面试官常问的问题包括:,1. 请简述HTML、CSS和JavaScript的基本概念和作用。,2. 如何优化网页性能?,3. 描述一下响应式设计的原理和实现方式。,4. 请解释一下什么是BFC(块级格式化上下文)?,5. 如何实现跨浏览器兼容性?,6. 描述一下事件冒泡和事件捕获。,7....
- 最新发布
-
6分钟前

14分钟前

20分钟前

28分钟前
35分钟前
- 热门阅读
-

903 浏览学习方法

242 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言