损失函数有哪些,常见损失函数的介绍
损失函数是机器学习中用于评估模型预测结果与真实值之间差异的函数,常见的损失函数包括:,1. 均方误差(MSE):用于回归问题,计算预测值与真实值差的平方的平均值。,2. 交叉熵损失(Cross-Entropy Loss):用于分类问题,衡量预测概率分布与真实标签分布之间的差异。,3. 逻辑回归损失(Logistic Loss):是交叉熵损失在二分类问题中的特例。,4. Hinge损失:常用于支持向量机(SVM)分类问题,衡量预测值与真实标签之间的差异。,5. 梯度提升损失(Gradient Boosting Loss):如均方误差、绝对误差等,用于梯度提升树等模型。,6. 对数损失(Log Loss):是交叉熵损失的对数形式,常用于二分类问题。,7. 混合损失(Hinge + Log Loss):结合了Hinge损失和Log损失,适用于某些特定问题。,这些损失函数在机器学习模型训练中扮演着重要角色,有助于优化模型参数,提高模型性能。
损失函数有哪些?
用户解答: 嗨,我想了解一下损失函数都有哪些类型,因为我正在学习机器学习,想要对模型评估和优化有一个更深入的理解,请问你能帮我介绍一下吗?
一:常见损失函数类型
-
均方误差(Mean Squared Error, MSE) 均方误差是最常用的回归损失函数之一,它计算预测值与真实值之间差的平方的平均值,公式如下: [ MSE = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2 ] ( y_i ) 是真实值,( \hat{y}_i ) 是预测值,( N ) 是样本数量。
-
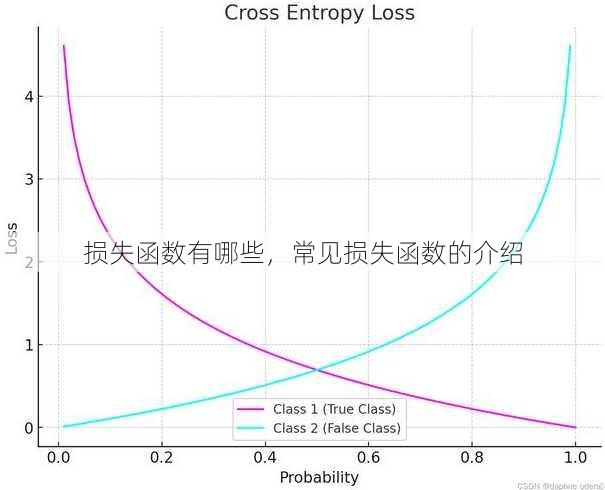
交叉熵损失(Cross-Entropy Loss) 交叉熵损失函数在分类问题中非常常见,它衡量的是预测概率分布与真实标签分布之间的差异,对于二分类问题,公式如下: [ CE = -[y \log(\hat{y}) + (1 - y) \log(1 - \hat{y})] ] ( y ) 是真实标签(0或1),( \hat{y} ) 是预测概率。
-
对数损失(Log Loss) 对数损失是交叉熵损失的一种特例,它只适用于二分类问题,它同样衡量预测概率与真实标签之间的差异,但通常用于二分类问题的分类器评估。
-
Hinge Loss Hinge Loss 通常用于支持向量机(SVM)分类问题中,它通过最大化预测值与真实标签之间的“间隔”来训练模型,公式如下: [ Hinge Loss = \max(0, 1 - y \hat{y}) ] ( y ) 是真实标签,( \hat{y} ) 是预测值。
二:损失函数的选择和应用
-
回归问题 在回归问题中,通常使用均方误差(MSE)或对数损失(Log Loss)来评估模型性能。
-
分类问题 对于二分类问题,可以使用交叉熵损失(Cross-Entropy Loss)或对数损失(Log Loss),多分类问题通常使用交叉熵损失。

-
多标签分类 在多标签分类中,每个样本可以属于多个类别,此时可以使用交叉熵损失,并确保模型输出概率分布。
-
异常检测 在异常检测中,损失函数的选择可能取决于具体问题和数据分布。
三:损失函数的优化和调参
-
梯度下降(Gradient Descent) 梯度下降是优化损失函数的一种常用方法,它通过不断调整模型参数来最小化损失。
-
学习率调整 学习率是梯度下降中的一个关键参数,它决定了参数更新的步长,合适的学习率可以加快收敛速度。
-
正则化 为了防止过拟合,可以在损失函数中加入正则化项,如L1或L2正则化。

-
早停(Early Stopping) 在训练过程中,如果模型性能不再提升,可以提前停止训练以避免过拟合。
四:损失函数的扩展和应用
-
加权损失函数 在某些情况下,不同的样本可能具有不同的重要性,可以使用加权损失函数来调整不同样本的权重。
-
自适应损失函数 自适应损失函数可以根据模型性能自动调整损失函数的形式或参数。
-
集成学习中的损失函数 在集成学习中,可以使用不同的损失函数来组合多个模型的预测结果。
-
损失函数的交叉验证 在模型评估过程中,可以使用交叉验证来评估不同损失函数的性能。
通过以上几个的介绍,相信你对损失函数有了更深入的了解,选择合适的损失函数对于模型性能至关重要,希望这些信息能帮助你更好地进行机器学习实践。
其他相关扩展阅读资料参考文献:
损失函数有哪些
损失函数的介绍
在机器学习和深度学习中,损失函数(Loss Function)扮演着至关重要的角色,它是衡量模型预测结果与真实值之间差距的关键指标,通过优化损失函数,我们可以提高模型的性能,本文将介绍几种常见的损失函数及其应用场景。
分类损失函数
-
交叉熵损失函数(Cross-Entropy Loss)
- 定义:交叉熵损失函数用于衡量模型预测概率分布与真实概率分布之间的差异。
- 应用场景:多分类问题中广泛使用。
- 优点:易于计算,能够很好地反映模型预测的准确性。
-
Hinge Loss(SVM中的损失函数)
- 定义:用于支持向量机(SVM)分类问题中,衡量模型预测值与真实类别之间的间隔。
- 应用场景:适用于最大间隔分类任务。
- 特点:对错误分类的样本给予较大惩罚,对正确分类但间隔较小的样本也给予一定惩罚。
-
逻辑回归中的对数损失函数(Log Loss)
- 定义:用于二分类问题中,衡量模型预测概率与真实标签之间的误差。
- 应用场景:适用于二分类问题的机器学习模型。
- 优点:对概率预测进行惩罚,能够处理类别不平衡问题。
回归损失函数
-
均方误差损失函数(Mean Squared Error Loss,MSE)
- 定义:计算模型预测值与真实值之间差的平方的均值。
- 应用场景:适用于需要连续精确预测的场景,如房价预测等。
- 优点:对误差较大的样本惩罚较重,能够很好地处理离群点。
-
绝对误差损失函数(Mean Absolute Error Loss,MAE)
- 定义:计算模型预测值与真实值之间差的绝对值的均值。
- 应用场景:适用于对异常值不敏感的回归问题。
- 特点:对误差的绝对值进行惩罚,不依赖于预测值的大小,对离群点敏感度较低。
结构损失函数 在深度学习中,除了基本的分类和回归损失函数外,还有一些针对特定任务的结构损失函数,在目标检测任务中使用的交叉熵与Smooth L1损失结合的复合损失函数等,这些结构损失函数结合了多种损失函数的优点,针对特定任务进行优化,提高模型的性能,这些复合损失函数的设计通常需要根据具体任务的需求进行选择和调整,结构损失函数的应用场景广泛且复杂,需要根据具体任务选择合适的组合方式,结构损失函数的优化策略包括正则化项的使用、梯度裁剪等技巧,以提高模型的泛化能力和稳定性。其他特殊领域的损失函数除了上述常见的损失函数外,还有一些特殊领域使用的特殊损失函数,如图像超分辨率重建中的感知损失函数等。总结与展望随着机器学习领域的不断发展,新的损失函数不断涌现和优化,了解并掌握各种损失函数的特性和应用场景对于提高模型的性能至关重要,在实际应用中,需要根据具体任务的需求选择合适的损失函数或组合多种损失函数进行优化,未来随着深度学习技术的不断进步,复合损失函数和自适应调整损失函数将是研究的重要方向之一。
“损失函数有哪些,常见损失函数的介绍” 的相关文章

html改字体颜色代码,HTML设置字体颜色教程
要更改HTML中的字体颜色,你可以使用`标签的color属性,或者在CSS样式中通过color属性来指定,以下是一个简单的示例:,使用标签:,`html,这是红色字体,`,使用CSS样式:,`html,, .red-text {, color: red;, },,这是红色字...

java2021面试及答案,2021年Java面试题及答案解析
Java 2021面试及答案摘要:,本文提供了2021年Java面试中常见的问题及答案,涵盖了Java基础知识、集合框架、多线程、JVM、Spring框架等多个方面,内容包括面向对象编程原则、Java内存模型、集合类实现原理、线程同步机制、垃圾回收算法等核心知识点,还涉及了Spring框架中的AOP...
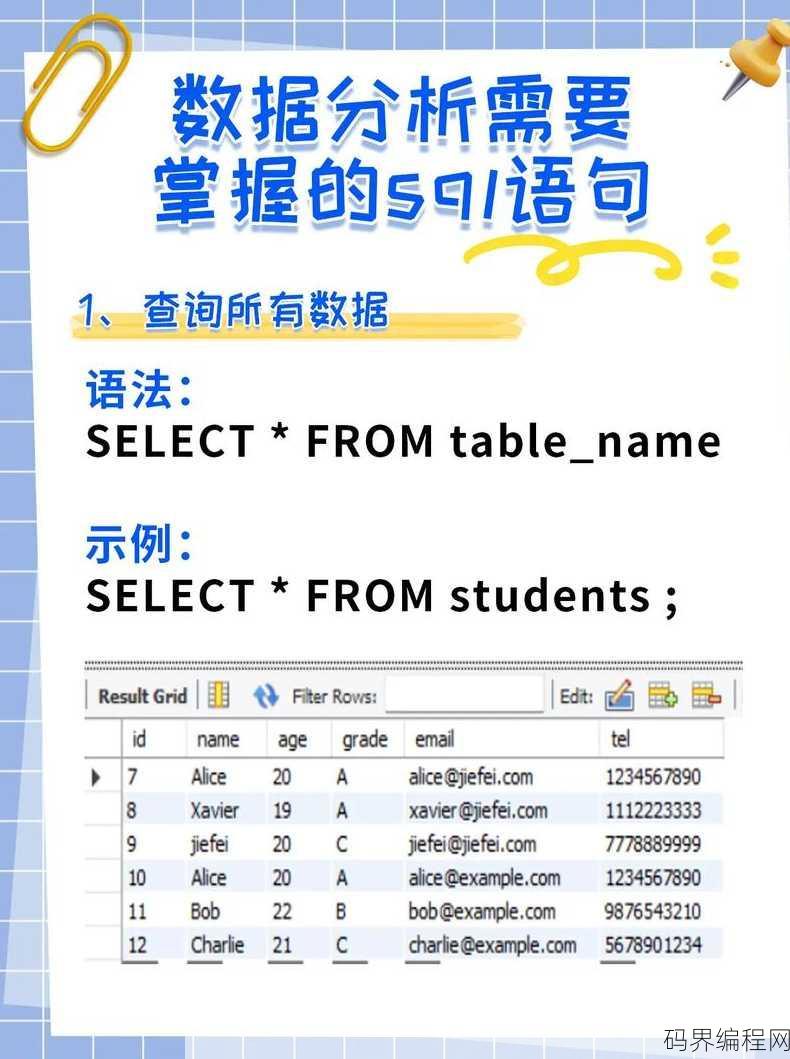
sql添加语句,高效SQL添加语句技巧汇总
SQL添加语句通常用于数据库中向表中插入新的记录,以下是一个基本的SQL添加语句的示例:,``sql,INSERT INTO table_name (column1, column2, column3) VALUES (value1, value2, value3);,`,在这个例子中,table_...

初等函数一定连续吗,初等函数连续性探讨
初等函数,即由基本初等函数(如幂函数、指数函数、对数函数、三角函数等)通过有限次四则运算和复合运算所构成的函数,通常在一定区间内是连续的,并非所有初等函数在整个实数域内都连续,函数 \(f(x) = \frac{1}{x}\) 是初等函数,但在 \(x = 0\) 处不连续,初等函数的连续性需视其定...

源代码完整版下载,源代码完整版一键下载指南
较为简略,无法直接生成摘要,请提供更详细的信息或具体内容,以便我为您生成摘要,您可以提供文章、报告、代码片段或其他文本的详细内容。 嗨,大家好!最近我在寻找一款软件的源代码,想自己研究一下它的实现原理,在网上搜索了好久,发现很多地方都只能找到部分源代码,或者需要付费才能下载完整版,我想知道,有没有...
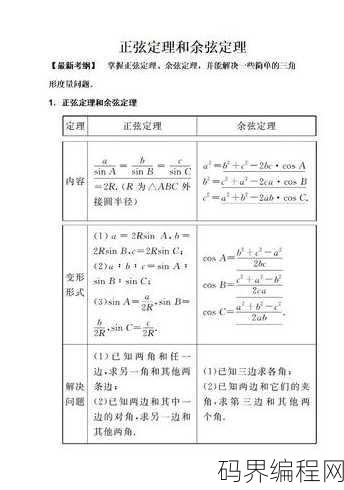
正弦定理和余弦定理,正弦定理与余弦定理解析
正弦定理和余弦定理是解析几何中用于计算三角形边长和角度的公式,正弦定理指出,在任何三角形中,各边与其对应角的正弦值之比相等,余弦定理则提供了边长与角度之间的关系,表明在任何三角形中,一个角的余弦值等于其他两边长度的平方和减去该边长度平方的两倍,再除以这两边长度乘积的两倍,这两个定理在解决几何问题、工...
- 最新发布
-
3分钟前
10分钟前

16分钟前
23分钟前

30分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言