网站源码爬取,网站源码高效爬取指南
网站源码爬取是指利用特定的工具或技术,从目标网站中抓取HTML、CSS、JavaScript等代码的过程,这种方法常用于网站内容分析和数据挖掘,爬取过程中,开发者需要遵循目标网站的robots.txt文件规定,尊重网站版权和隐私政策,常见的爬取工具包括BeautifulSoup、Scrapy等,在进行网站源码爬取时,还需注意遵守相关法律法规,避免侵犯他人权益。
揭秘信息获取的幕后黑手
真实用户解答: 嗨,我最近想了解一些关于网站源码爬取的信息,因为我在做一个项目,需要获取一些特定网站的数据,但是我对这个领域不是很熟悉,所以想请教一下,网站源码爬取到底是怎么回事呢?
下面,我将从几个来地解答你的问题。
一:什么是网站源码爬取?
- 定义:网站源码爬取,也称为网页爬虫,是指通过编写程序或使用工具,自动从网站上获取网页内容的过程。
- 目的:爬取网站源码的目的是为了获取数据、分析网站结构、索引网页等。
- 合法性:在进行网站源码爬取时,必须遵守相关法律法规,尊重网站的robots.txt文件规定。
二:网站源码爬取的原理
- HTTP请求:爬虫通过发送HTTP请求到目标网站,获取网页内容。
- HTML解析:爬虫对获取到的HTML内容进行解析,提取所需数据。
- 数据存储:将解析后的数据存储到数据库或文件中,以便后续处理。
三:常用的网站源码爬取工具
- Beautiful Soup:Python的一个库,用于解析HTML和XML文档。
- Scrapy:一个强大的爬虫框架,用于构建复杂的数据抓取项目。
- Selenium:用于模拟浏览器行为,可以爬取动态生成的网页内容。
四:网站源码爬取的注意事项
- 效率:合理设置爬取速度,避免对目标网站造成过大压力。
- 数据格式:确保爬取到的数据格式正确,方便后续处理。
- 数据清洗:对爬取到的数据进行清洗,去除无效或重复的数据。
五:网站源码爬取的应用场景
- 搜索引擎:通过爬取网页内容,构建索引,提供搜索服务。
- 数据挖掘:从网站上获取数据,进行分析,发现有价值的信息。
- 舆情监控:监控特定关键词或话题,了解公众观点。
网站源码爬取是一个涉及多个方面的技术领域,在进行爬取时,我们需要了解其原理、选择合适的工具,并注意遵守相关法律法规,通过合理利用网站源码爬取技术,我们可以获取到大量的数据,为各种应用场景提供支持。
其他相关扩展阅读资料参考文献:
网站源码爬取的的介绍 随着互联网的发展,网站源码爬取逐渐成为了一个热门话题,网站源码爬取是指通过技术手段获取网站上的源代码信息,这对于数据分析、数据挖掘等方面具有重要意义,本文将围绕网站源码爬取这一主题,从几个展开地探讨。
一:网站源码爬取的原理
-
爬虫的工作原理是什么? 爬虫是一种自动化程序,通过模拟浏览器行为来访问网站并获取数据,它通过不断地访问链接,获取网页内容,从而实现对网站源码的爬取。
-
常见的网站爬虫有哪些? 常见的网站爬虫有Scrapy、BeautifulSoup等,这些爬虫工具具有不同的特点,适用于不同的场景,Scrapy是一个强大的爬虫框架,适用于爬取大型网站;而BeautifulSoup则更适合于解析HTML和XML文档。
-
爬虫如何解析网页源码? 爬虫通过解析网页源码来提取所需信息,常见的解析方法有正则表达式、XPath和CSS选择器,这些解析方法可以帮助爬虫准确地定位到目标数据,从而实现高效爬取。
二:网站源码爬取的技巧
-
如何提高爬虫的效率? 提高爬虫效率的关键在于优化爬虫的访问策略,可以通过设置合理的并发数、使用代理IP、合理设置爬取间隔等方式来提高效率。
-
如何避免被网站封禁? 为了避免被网站封禁,爬虫需要遵守网站的访问规则,合理设置访问频率,同时可以使用动态IP、合理设置User-Agent等方式来避免被识别为恶意爬虫。
-
如何处理爬取到的数据? 爬取到的数据需要进行处理和分析,可以通过数据存储、数据清洗、数据挖掘等方式来处理数据,从而提取出有价值的信息。
三:网站源码爬取的合法性问题
-
网站源码爬取是否合法? 网站源码爬取的合法性取决于具体的场景和使用目的,如果未经许可,擅自爬取涉及版权或隐私的源代码信息,则可能涉及违法行为。
-
如何合规地进行网站源码爬取? 为了合规地进行网站源码爬取,需要遵守相关法律法规和网站的访问规则,需要尊重网站的隐私和版权,避免对网站造成不必要的干扰和损害。
-
网站源码爬取的风险有哪些? 网站源码爬取存在一定的风险,如法律风险、技术风险等,在进行网站源码爬取时,需要充分了解相关风险,并采取相应的措施进行防范和应对。
四:网站源码爬取的未来发展
-
网站源码爬取的技术发展趋势是什么? 随着人工智能、大数据等技术的发展,网站源码爬取的技术也在不断进步,更加智能、高效的爬虫技术将会得到广泛应用。
-
网站源码爬取的应用前景如何? 网站源码爬取在数据分析、数据挖掘、竞争情报等领域具有广泛的应用前景,随着互联网的不断发展,网站源码爬取的应用场景也将不断扩展。
就是关于网站源码爬取的几个的探讨,希望本文能够帮助读者更好地了解网站源码爬取的相关知识,为未来的学习和工作提供有益的参考。
“网站源码爬取,网站源码高效爬取指南” 的相关文章
AI代码生成器测评,AI代码生成器深度评测揭秘
AI代码生成器测评主要针对当前市场上流行的代码生成工具进行综合评估,测评内容涵盖生成速度、代码质量、易用性、功能丰富度等方面,结果显示,部分工具在生成速度和代码质量上表现优异,但易用性和功能丰富度有待提高,用户在选择时应根据自身需求,综合考虑各项指标,以选择最适合自己的AI代码生成器。 大家好,我...
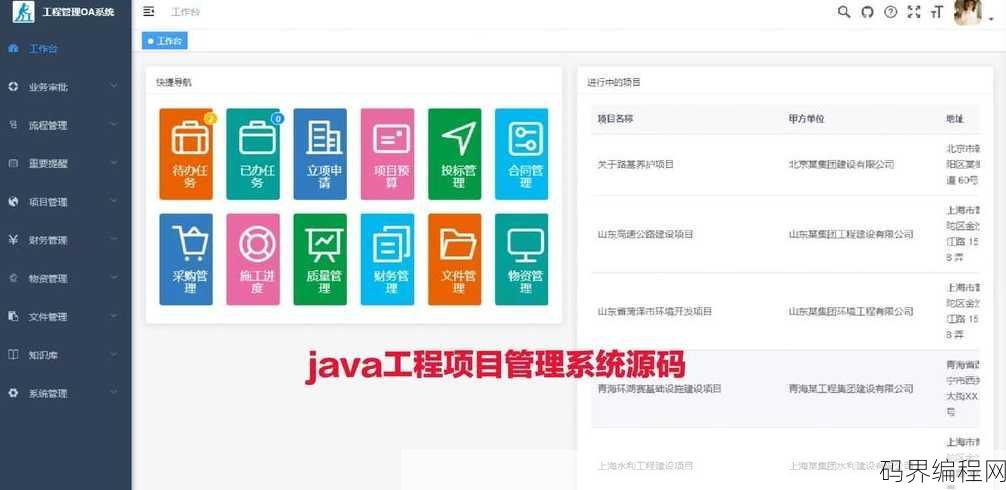
java源码怎么导入,Java源码导入指南
Java源码导入通常涉及以下步骤:,1. 下载Java源码:从Oracle官网或GitHub等平台下载所需Java版本的源码包。,2. 解压源码包:使用解压缩工具将下载的源码包解压到本地文件夹。,3. 设置环境变量:在系统环境变量中添加解压后的源码文件夹路径,例如在Windows中编辑Path变量。...
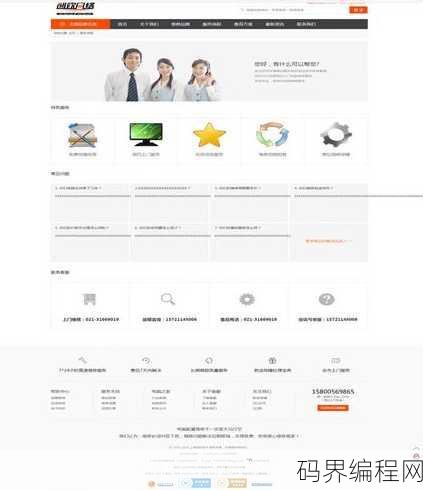
电脑公司网站源码,专业电脑公司网站源码大全分享
电脑公司网站源码是指电脑公司官方网站的原始代码,包括HTML、CSS、JavaScript等编程语言编写的内容,这些源码通常由公司内部开发团队编写,用于构建和展示公司的产品信息、服务内容以及用户交互界面,获取网站源码可以帮助开发者了解网站结构、设计风格和技术实现,以便进行二次开发或分析。 “嘿,我...

css中常用的伪类选择器,CSS常用伪类选择器详解
CSS中常用的伪类选择器包括:,1. **:link**:选择未被访问过的链接。,2. **:visited**:选择已被访问过的链接。,3. **:hover**:当鼠标悬停在元素上时触发。,4. **:active**:在元素上点击时触发。,5. **:focus**:当元素获得焦点时触发,常用...
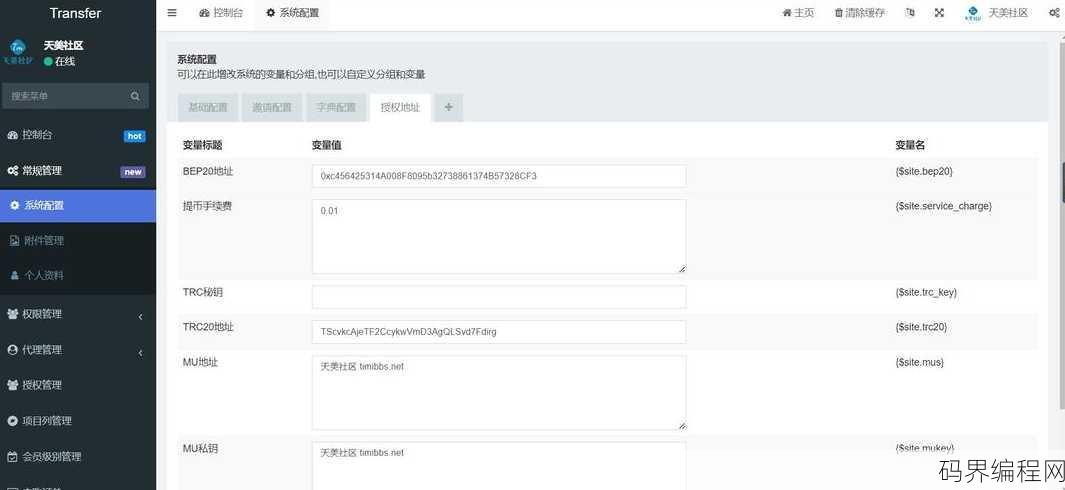
卡盟文章站源码,卡盟文章站源码全解析
卡盟文章站源码是一套专门为卡盟平台定制的文章发布系统源码,该源码具备文章管理、分类、评论等功能,支持SEO优化,易于安装和配置,用户可通过该源码快速搭建自己的文章站,实现内容发布、推广和用户互动,助力卡盟业务拓展。 你好,我在网上看到了“卡盟文章站源码”这个产品,想了解一下,我想知道这个源码具体能...

java贪吃蛇小游戏代码,Java版贪吃蛇游戏实现代码分享
本代码实现了一个简单的Java贪吃蛇小游戏,游戏通过控制方向键使蛇移动,吃到食物后增长,避免撞到自己或墙壁,代码中包含了游戏初始化、蛇和食物的生成、碰撞检测、得分统计等功能,适合用于学习和实践Java图形界面编程。用户提问:我想学习Java编程,能推荐一个适合初学者的项目吗?最好是游戏类的。 回答...
- 最新发布
-
2分钟前
8分钟前

17分钟前
24分钟前
30分钟前
- 热门阅读
-

918 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言