爬虫技术抓取网站数据,高效爬虫技术,网站数据抓取攻略
爬虫技术是一种用于从互联网上自动抓取数据的工具,它通过模拟人类浏览器的行为,访问网站并获取信息,这种技术广泛应用于数据挖掘、信息检索和搜索引擎等领域,爬虫可以抓取网页内容、HTML结构、图片、链接等,并按照一定的规则进行解析和存储,通过爬虫技术,可以高效地从大量网站中提取有价值的数据,为企业和个人提供便捷的数据获取途径。
嗨,我最近在研究如何使用爬虫技术来抓取网站数据,但是感觉有点一头雾水,我想知道,爬虫技术到底是怎么工作的?还有,有哪些常见的爬虫工具和库可以使用呢?
一:爬虫技术原理
- 网络请求:爬虫首先通过发送HTTP请求到目标网站,获取网页内容。
- 网页解析:使用解析库(如BeautifulSoup、lxml)从获取的HTML内容中提取有用信息。
- 数据存储:将解析后的数据存储到数据库或文件中,以便后续分析和使用。
- 遵循robots.txt:在爬取过程中,遵守目标网站的robots.txt文件规定,尊重网站爬虫策略。
- 异常处理:编写代码时,需要考虑网络请求失败、解析错误等异常情况,确保爬虫的稳定性。
二:常见爬虫工具和库
- Scrapy:Python的一个高级爬虫框架,功能强大,易于扩展。
- BeautifulSoup:用于解析HTML和XML文档,提取数据非常方便。
- Requests:用于发送HTTP请求,获取网页内容。
- Selenium:自动化浏览器操作,适合抓取动态加载的内容。
- Pandas:数据处理和分析的库,可以方便地对爬取到的数据进行处理。
三:爬虫策略
- 多线程/异步请求:使用多线程或异步请求可以提高爬取效率,减少等待时间。
- IP代理池:使用代理IP池可以避免被目标网站封禁,提高爬取成功率。
- 设置请求头:模拟浏览器访问,设置合适的User-Agent等请求头。
- 限速:设置合理的请求速度,避免对目标网站造成过大压力。
- 重试机制:在请求失败时,实现重试机制,提高爬取成功率。
四:数据清洗
- 去除无效数据:删除重复、无关的数据,确保数据的准确性。
- 数据格式化:统一数据格式,方便后续处理和分析。
- 文本处理:对文本数据进行分词、去停用词等处理,提高数据质量。
- 数据可视化:使用图表展示数据,便于理解和分析。
- 数据挖掘:运用机器学习等技术,从数据中挖掘有价值的信息。
五:法律和道德问题
- 尊重版权:在爬取数据时,要确保不侵犯目标网站的版权。
- 隐私保护:不爬取涉及个人隐私的数据,保护用户隐私。
- 数据安全:确保爬取到的数据安全,防止数据泄露。
- 合理使用:合理使用爬取到的数据,不得用于非法用途。
- 社会责任:作为爬虫开发者,要承担社会责任,遵守相关法律法规。
通过以上几个的深入探讨,相信大家对爬虫技术有了更全面的认识,在实际应用中,我们需要根据具体需求选择合适的爬虫工具和策略,确保爬取到的数据准确、有效,要时刻关注法律和道德问题,做一个有责任感的爬虫开发者。
其他相关扩展阅读资料参考文献:
爬虫技术抓取网站数据解析
爬虫技术的介绍
随着互联网的发展,网站数据抓取成为获取特定信息的重要方式之一,爬虫技术作为这一过程中的核心手段,被广泛应用于数据挖掘、搜索引擎等领域,爬虫技术通过模拟浏览器行为,自动抓取网站上的数据并存储下来,以供后续分析和处理。
爬虫技术的重要性及应用领域
数据挖掘:通过爬虫技术,可以系统地收集和分析特定网站的数据,为企业决策提供支持。
搜索引擎:搜索引擎需要不断地抓取互联网上的网页数据,以提供实时、准确的搜索结果。
竞品分析:在市场竞争激烈的环境下,通过爬虫抓取竞品网站的数据,可以了解对手的动态和策略。
爬虫技术的核心组件及原理
发送请求:爬虫首先向目标网站发送请求,模拟浏览器访问网站。
接收响应:网站服务器在收到请求后,会返回相应的HTML代码或其他格式的数据。
数据解析:爬虫通过特定的解析方法,如正则表达式或第三方库,提取所需的数据。
数据存储:将抓取到的数据存储到本地或数据库中,以便后续处理和分析。
爬虫技术的实际操作流程
确定目标网站:明确需要抓取的数据所在的网站。
分析网站结构:了解网站的页面结构、URL规律等,以便制定合适的爬虫策略。
编写爬虫代码:根据目标网站的结构,选择合适的编程语言和工具,编写爬虫代码。
测试与优化:对编写的爬虫进行测试,确保其稳定性和效率,并根据测试结果进行优化。
常见问题和解决方案
反爬虫机制:一些网站会采取反爬虫措施,如验证码、限制访问频率等,对此,需要采取相应的方法绕过这些机制,如使用代理IP、调整访问频率等。
数据格式多样:网站上的数据格式多样,如HTML、JSON、XML等,需要根据具体的数据格式选择合适的解析方法。
法律法规遵守:在抓取网站数据时,必须遵守相关法律法规,尊重网站的使用协议,避免非法获取和使用数据。
未来发展趋势及挑战
随着人工智能、大数据等技术的发展,爬虫技术将面临更多的应用场景和更大的发展空间,反爬虫技术也将不断进步,爬虫技术的挑战和难度将不断增大,爬虫技术将更加注重智能化、高效化和合规化,以适应互联网的发展需求。
爬虫技术在数据获取和分析方面具有重要意义,但也面临着一些挑战和问题,通过深入了解其原理、掌握核心技术、遵守法律法规,我们可以更好地利用爬虫技术,为互联网的发展做出贡献。
“爬虫技术抓取网站数据,高效爬虫技术,网站数据抓取攻略” 的相关文章
cmd命令启动mysql服务,如何使用cmd命令启动MySQL服务
使用cmd命令启动MySQL服务,首先确保MySQL已安装并配置正确,在命令提示符中,输入以下命令启动服务:,``bash,net start MySQL,`,如果MySQL服务未安装或未配置,系统将提示错误信息,若要检查服务状态,可以使用命令:,`bash,sc query state= all...

powermill编程教学视频,PowerMill编程技能提升教学视频集
本视频为Powermill编程教学,旨在帮助用户掌握Powermill软件的编程技巧,内容涵盖从基础操作到高级应用,包括编程流程、工具选择、路径规划等关键知识点,通过实际案例演示,逐步讲解如何高效完成复杂加工任务,适合初学者及有一定基础的工程师学习使用。PowerMILL编程教学视频:轻松入门,高效...
c+软件哪个好用,C+软件推荐,好用工具大盘点
C++软件众多,具体哪个好用取决于个人需求和用途,常见且评价较高的有Visual Studio、Eclipse CDT、Code::Blocks等,Visual Studio功能强大,适合大型项目开发;Eclipse CDT轻量级,易于上手;Code::Blocks简单易用,适合初学者,建议根据个人...

儿童编程课哪个机构好,儿童编程课程推荐,哪家机构更胜一筹?
选择儿童编程课,建议关注机构的教学质量、师资力量、课程内容和教学方法,目前市场上比较受欢迎的机构有XX编程、YY编程和ZZ编程,XX编程以寓教于乐著称,YY编程注重培养孩子的逻辑思维能力,ZZ编程则强调项目实战,家长可以根据孩子的兴趣和需求,选择合适的机构。儿童编程课哪个机构好?真实用户分享选择心得...

html5是什么手机,HTML5兼容手机一览
HTML5是一种用于网页开发的编程语言标准,它不是手机,而是一种技术规范,HTML5支持丰富的多媒体内容,如视频和音频,且能在多种设备上运行,包括智能手机,可以说支持HTML5的手机是指那些能够运行HTML5网页和应用,提供流畅多媒体体验的手机,这些手机通常具备较好的性能和兼容性,能够支持现代网络技...
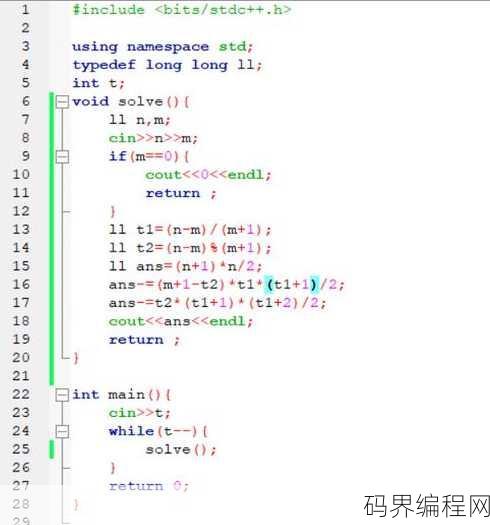
div教程,深度解析,div布局教程全攻略
本教程旨在全面介绍div的使用方法,从基础开始,详细讲解如何使用HTML中的div标签来创建和管理网页布局,内容包括div的基本属性、嵌套、样式应用、响应式设计等,通过实际案例,帮助读者掌握div在网页设计中的灵活运用,提升网页布局的效率与美观度。div教程 用户解答: 嗨,大家好!我最近在学习...
- 最新发布
-

2分钟前

9分钟前

15分钟前

23分钟前
30分钟前
- 热门阅读
-

908 浏览学习方法

242 浏览源码资料
-
224 浏览学习方法

219 浏览数据库

213 浏览编程语言