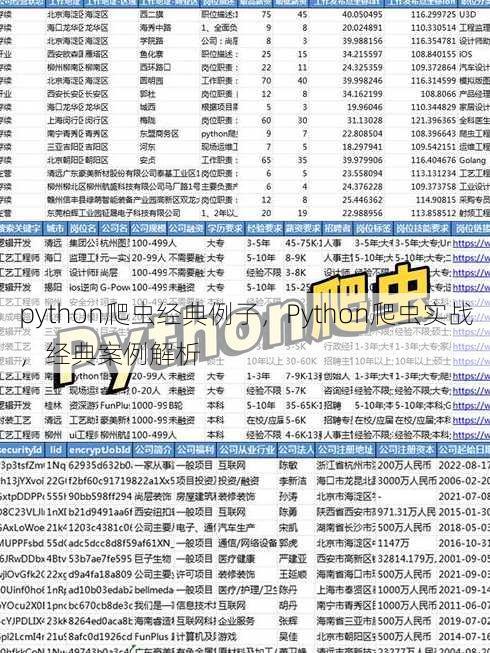
python爬虫经典例子,Python爬虫实战,经典案例解析
Python爬虫经典例子包括:爬取网页内容,如使用requests库获取网页HTML,然后用BeautifulSoup解析HTML,提取所需信息;爬取图片,如使用requests下载图片;爬取动态加载的内容,如使用Selenium模拟浏览器行为;爬取API数据,如使用requests调用API接口获取数据,这些例子展示了Python爬虫的基本原理和应用场景。
Python爬虫经典例子:从入门到精通
用户解答: 嗨,我是一名Python初学者,最近对爬虫很感兴趣,我想了解一些Python爬虫的经典例子,以便更好地学习和实践,你能给我推荐几个吗?
下面,我将从几个经典例子出发,地介绍Python爬虫的基本原理和应用。
一:爬取网页内容
-
使用
requests库获取网页内容-
基本原理:
requests库是Python中常用的HTTP库,可以发送HTTP请求,获取网页内容。 -
代码示例:
import requests url = 'http://example.com' response = requests.get(url) print(response.text)
-
注意事项:在使用
requests时,要注意处理异常,如连接错误、超时等。
-
-
解析网页内容

-
基本原理:使用
BeautifulSoup库可以方便地解析HTML或XML文档。 -
代码示例:
from bs4 import BeautifulSoup soup = BeautifulSoup(response.text, 'html.parser') print(soup.title.text)
-
注意事项:解析时要注意选择合适的解析器,如
html.parser、lxml等。
-
-
提取特定信息
- 基本原理:通过CSS选择器或XPath表达式,可以定位并提取页面中的特定信息。
- 代码示例:
print(soup.select('div.title')[0].text) - 注意事项:选择器要准确,避免提取到无关信息。
二:爬取动态网页内容
-
使用
Selenium库模拟浏览器行为-
基本原理:
Selenium可以用户在浏览器中的操作,如点击、输入等。 -
代码示例:
from selenium import webdriver driver = webdriver.Chrome() driver.get('http://example.com') print(driver.title) driver.quit() -
注意事项:
Selenium操作较为复杂,需要了解浏览器的工作原理。
-
-
处理JavaScript渲染的页面
-
基本原理:有些页面使用JavaScript动态生成内容,需要使用
Selenium等工具进行爬取。 -
代码示例:
from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, 'myElement')) ) print(element.text) -
注意事项:JavaScript渲染的页面爬取难度较大,需要耐心调试。
-
-
处理登录验证
- 基本原理:有些网站需要登录后才能访问特定内容,需要模拟登录过程。
- 代码示例:
driver.find_element(By.ID, 'username').send_keys('my_username') driver.find_element(By.ID, 'password').send_keys('my_password') driver.find_element(By.ID, 'login_button').click() - 注意事项:登录验证方式多样,需要根据实际情况进行处理。
三:数据存储与处理
-
使用
pandas库处理数据-
基本原理:
pandas是Python中常用的数据分析库,可以方便地处理表格数据。 -
代码示例:
import pandas as pd df = pd.DataFrame(data) print(df.head())
-
注意事项:
pandas操作较为简单,但要注意数据清洗和预处理。
-
-
使用
SQLAlchemy库存储数据-
基本原理:
SQLAlchemy是Python中常用的ORM(对象关系映射)库,可以方便地操作数据库。 -
代码示例:
from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://user:password@host/dbname') df.to_sql('table_name', con=engine, if_exists='append', index=False) -
注意事项:数据库操作要遵循SQL规范,注意数据安全。
-
-
使用
matplotlib库可视化数据-
基本原理:
matplotlib是Python中常用的绘图库,可以方便地生成图表。 -
代码示例:
import matplotlib.pyplot as plt plt.plot(df['date'], df['value']) plt.xlabel('Date') plt.ylabel('Value') plt.show() -
注意事项:图表样式要简洁明了,便于阅读。
-
通过以上经典例子,相信你已经对Python爬虫有了初步的了解,在实际应用中,要根据具体需求选择合适的工具和方法,不断积累经验,提高爬虫技能。
其他相关扩展阅读资料参考文献:
Python爬虫经典例子解析
爬虫基础概念及Python爬虫简介
随着互联网的发展,数据抓取变得越来越重要,Python作为一种强大的编程语言,其爬虫技术广泛应用于数据抓取领域,爬虫,是一种按照一定的规则自动抓取网络数据的程序,Python爬虫则是利用Python语言编写这些程序,实现数据的自动化抓取。
经典爬虫例子及其解析
爬取网页内容
这是爬虫最基础的应用之一,通过Python的requests库和BeautifulSoup库,可以轻松实现网页内容的爬取。
- 使用requests库获取网页HTML内容。
- 使用BeautifulSoup解析HTML,提取所需数据。
- 将提取的数据保存到本地文件或数据库中。
爬取图片
很多网站上有大量的图片资源,通过爬虫可以批量下载,以爬取微博图片为例。
- 分析网页结构,找到图片链接。
- 使用Python的requests库下载图片。
- 将下载的图片保存到本地目录。
爬取动态数据
对于动态加载的数据,如新闻网站上的新闻列表,可以使用Selenium库模拟浏览器行为进行爬取。
- 使用Selenium打开网页并模拟浏览器操作。
- 定位到动态数据所在元素并提取数据。
- 将数据保存或进一步处理。
爬虫技术的进阶应用
除了基础的数据抓取,爬虫技术还可以用于数据挖掘、舆情分析等领域,通过爬取社交媒体上的评论数据,进行舆情分析;通过爬取电商网站上的商品信息,进行价格监测和竞品分析,这些应用都需要对爬虫技术有深入的了解和实践经验。
注意事项与合规性建议
在进行爬虫开发时,必须遵守网站的爬虫协议和相关法律法规,尊重网站的数据使用规则,避免过度爬取和滥用数据,要注意保护个人隐私和数据安全,避免侵犯他人的合法权益,建议在使用爬虫技术时,先了解相关法律法规和网站规定,确保合法合规地进行数据抓取,Python爬虫作为一种强大的数据抓取工具,在互联网时代发挥着重要作用,通过学习和实践,可以更好地掌握这一技术,为数据分析和应用提供有力支持。
“python爬虫经典例子,Python爬虫实战,经典案例解析” 的相关文章

任意角的三角函数的定义,解析任意角的三角函数基本概念
任意角的三角函数定义:在直角坐标系中,以原点为顶点,射线为始边,与单位圆相交于点P,点P的坐标为(x,y),则该射线与x轴正半轴所夹的角为该射线的角度,任意角的三角函数包括正弦、余弦、正切、余切、余弦和正割,分别表示为sinθ、cosθ、tanθ、cotθ、secθ和cscθ,正弦和余弦表示点P的纵...
cms自助建站,一站式CMS自助建站解决方案
CMS自助建站是一种便捷的网站建设方式,用户无需编程知识即可通过可视化界面轻松搭建网站,它提供了丰富的模板和功能模块,支持内容管理、用户管理等操作,降低了网站建设门槛,适用于各类企业和个人快速搭建网站。轻松掌握CMS自助建站,开启您的互联网之旅 用户问答: 问:我是个新手,对建站一窍不通,听说现...
css高级选择器有哪些,CSS高级选择器详解
CSS高级选择器包括但不限于以下几种:,1. **属性选择器**:如 [attribute]、[attribute=value]、[attribute~=value] 等,用于匹配具有特定属性的元素。,2. **伪类选择器**:如 :hover、:active、:focus 等,用于匹配处于特定状态...
textarea文本域,探索 textarea 文本域的强大功能与应用
textarea文本域是一个强大的输入控件,允许用户输入多行文本,它广泛应用于网页表单中,用于收集用户的长篇评论、笔记或信息,textarea的强大功能包括自定义高度和宽度、限制字符数、只读属性以及富文本编辑等,通过灵活配置,textarea能够满足不同场景下的文本输入需求,提升用户体验,本文将深入...
帝国cms 历史类网站源码,帝国CMS定制版历史主题网站源码
帝国CMS是一款流行的内容管理系统,该历史类网站源码基于帝国CMS开发,集成了丰富的历史相关内容和功能,源码包含详细的历史资料库、时间线展示、专题报道模块,以及用户互动区,旨在为用户提供全面的历史信息浏览和交流平台,源码结构清晰,易于扩展和维护,适合历史爱好者或专业网站构建者使用。 大家好,我是一...
c+软件哪个好用,C+软件推荐,好用工具大盘点
C++软件众多,具体哪个好用取决于个人需求和用途,常见且评价较高的有Visual Studio、Eclipse CDT、Code::Blocks等,Visual Studio功能强大,适合大型项目开发;Eclipse CDT轻量级,易于上手;Code::Blocks简单易用,适合初学者,建议根据个人...
- 最新发布
-

5秒前
7分钟前
13分钟前

20分钟前

27分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言