应用程序中的服务器错误怎么解决,高效解决应用程序服务器错误的方法指南
在应用程序中遇到服务器错误时,首先检查网络连接是否稳定,若网络正常,可尝试刷新页面或重启应用程序,若问题依旧,可联系技术支持或查看官方论坛寻求解决方案,检查服务器端日志,确认错误类型,并按官方文档进行相应操作,若以上方法无效,建议寻求专业技术人员协助。
用户视角下的解决之道
用户解答: 最近我在使用一款在线购物应用时,遇到了服务器错误,页面一直无法加载,非常影响购物体验,我尝试了重启手机、清理缓存、甚至重启应用,但问题依旧存在,后来,我在应用内找到了客服联系方式,经过沟通,客服帮我解决了问题,这次经历让我对应用程序中的服务器错误有了更深的认识。
一:识别服务器错误
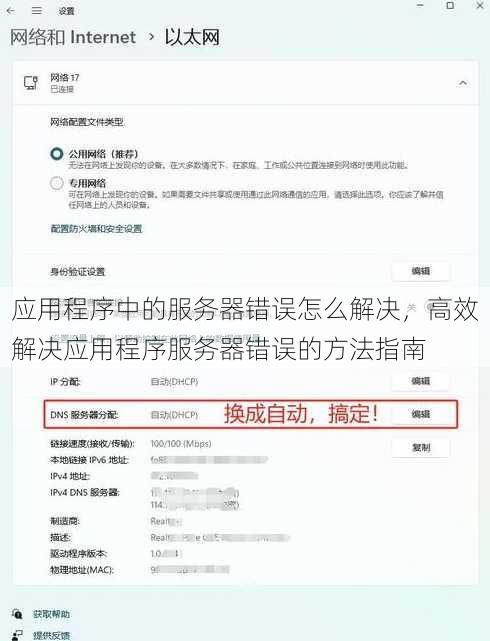
- 检查网络连接:确认你的设备是否连接到了稳定的网络,服务器错误可能是因为网络不稳定导致的。
- 查看应用内提示:大多数应用在遇到服务器错误时,都会在界面上给出相应的提示,如“服务器繁忙”、“无法连接到服务器”等。
- 查看其他用户反馈:在应用论坛或社交媒体上搜索,看看是否有其他用户遇到相同的问题,这有助于判断问题是否普遍。
二:解决服务器错误的方法
- 重启应用:简单地重启应用就能解决问题。
- 清理缓存:长时间使用应用会导致缓存积累,清理缓存可以释放内存,提高应用运行效率。
- 重启设备:如果应用重启和清理缓存都无法解决问题,尝试重启你的设备。
- 联系客服:如果以上方法都无法解决问题,可以尝试联系应用客服,寻求帮助。
三:预防服务器错误
- 定期更新应用:应用更新通常会修复已知的问题,包括服务器错误。
- 避免高峰时段使用:服务器在高峰时段可能会出现拥堵,尽量避开这些时段使用应用。
- 备份重要数据:定期备份你的数据,以防服务器错误导致数据丢失。
- 关注官方公告:关注应用官方发布的公告,了解服务器维护和升级信息。
四:服务器错误对用户体验的影响
- 影响使用效率:服务器错误会导致应用无法正常使用,影响用户的工作和生活效率。
- 降低用户满意度:频繁出现的服务器错误会降低用户对应用的满意度,甚至导致用户流失。
- 损害品牌形象:服务器错误频繁出现,会损害应用的品牌形象,影响用户对品牌的信任。
- 增加客服压力:服务器错误需要客服介入解决,会增加客服的工作压力。
五:如何提高服务器稳定性
- 优化服务器配置:合理配置服务器硬件和软件,提高服务器处理能力。
- 负载均衡:通过负载均衡技术,将用户请求分配到不同的服务器,避免单点过载。
- 数据备份:定期备份服务器数据,确保数据安全。
- 监控与预警:实时监控服务器运行状态,及时发现并处理问题。
- 优化应用代码:优化应用代码,减少服务器压力,提高应用运行效率。
应用程序中的服务器错误是用户常见的问题,了解其产生原因和解决方法,有助于提高用户体验,开发者也应关注服务器稳定性,为用户提供更好的服务。
其他相关扩展阅读资料参考文献:
识别服务器错误类型
- 网络问题:服务器错误常与网络连接异常相关,例如DNS解析失败、防火墙限制或网络延迟,需通过ping、traceroute或telnet等工具检查网络连通性,确认服务器IP是否可访问,端口是否开放。
- 代码错误:应用程序中的逻辑漏洞、语法错误或未处理的异常会导致服务器崩溃或功能异常,需通过代码审查、单元测试和集成测试定位问题,重点关注try-catch块是否覆盖所有可能异常。
- 数据库连接问题:数据库服务宕机、连接池耗尽或SQL语句错误会引发服务器响应缓慢或数据读写失败,需检查数据库服务状态、连接池配置及SQL语句的语法和执行效率。
- 资源耗尽:CPU、内存或磁盘空间不足会导致服务器性能下降甚至崩溃,需通过系统监控工具(如top、htop)实时观察资源使用情况,排查是否存在内存泄漏或磁盘满载问题。
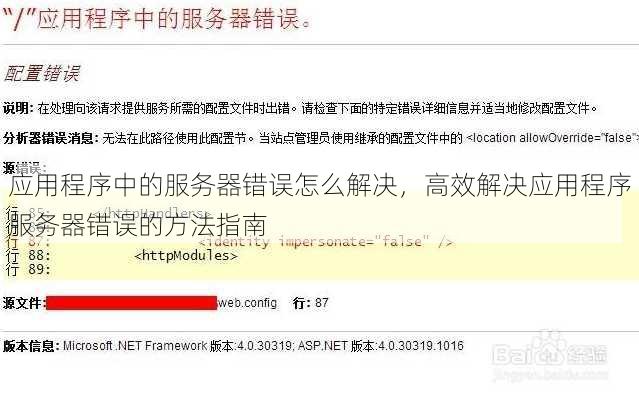
- 配置错误:错误的配置参数(如超时时间、端口绑定或权限设置)会引发服务器无法启动或运行异常,需逐一核对配置文件(如nginx.conf、application.properties),确保参数与实际环境匹配。
日志分析与调试
- 查看服务器日志:服务器日志是排查错误的核心依据,Nginx的access.log记录请求信息,error.log记录错误详情;Java应用可通过log4j或SLF4J查看日志,定位具体异常堆栈。
- 分析应用日志:结合业务逻辑分析日志内容,寻找错误模式,频繁出现500 Internal Server Error时,需检查后端服务是否因代码异常或依赖服务故障而崩溃。
- 使用调试工具:通过调试工具(如Postman、Wireshark)模拟请求并捕获网络数据包,确认请求是否到达服务器、响应是否正常,对于复杂逻辑,可使用Chrome开发者工具或Selenium进行前端到后端的全流程调试。
- 日志分级与过滤:配置日志级别(如DEBUG、INFO、ERROR)并过滤关键信息,避免日志冗余,使用grep "ERROR" /var/log/nginx/error.log快速定位错误行。
- 日志追踪与关联:通过分布式追踪工具(如Zipkin、SkyWalking)关联请求链路,分析错误是否由某个微服务或中间件引发,实现精准定位。
配置优化与调整
- 调整超时参数:过长的超时时间可能导致服务器资源浪费,过短则可能引发请求中断,Nginx的proxy_read_timeout和proxy_connect_timeout需根据业务需求合理设置。
- 优化缓存策略:缓存配置不当会导致服务器负载过高或数据不一致,需检查缓存过期时间(如Redis的TTL)、缓存大小限制(如maxmemory)及缓存命中率,避免缓存雪崩或穿透。
- 修改连接池配置:数据库连接池过大可能占用过多内存,过小则导致连接竞争,需根据并发量调整连接池大小(如HikariCP的maximumPoolSize),并设置合理的空闲连接超时时间(idleTimeout)。
- 资源分配优先级:通过cgroups或Kubernetes资源限制设置服务器资源分配优先级,确保关键服务优先获取资源,为数据库分配更多CPU和内存,限制非核心服务的资源占用。
- 环境变量校验:错误的环境变量(如数据库密码、API密钥)可能导致服务器配置异常,需在部署前通过脚本校验环境变量是否正确加载,避免因参数缺失或错误引发服务中断。
资源管理与监控
- 实时监控资源使用:部署监控系统(如Prometheus + Grafana)跟踪CPU、内存、磁盘和网络流量,及时发现资源瓶颈,当内存使用率超过90%时,需检查是否有内存泄漏或缓存策略不当。
- 优化数据库查询性能:通过EXPLAIN分析SQL执行计划,定位慢查询并添加索引,对频繁查询的字段(如用户ID)创建复合索引,减少全表扫描时间。
- 调整线程池与并发数:线程池配置过小会导致请求排队,过大则可能引发线程竞争,需根据服务器硬件性能(如CPU核心数、内存容量)调整线程池大小(如Tomcat的maxThreads)。
- 负载均衡策略优化:使用Nginx或HAProxy实现负载均衡,避免单点故障,通过round-robin或least-connection算法分配流量,确保后端服务负载均衡。
- 定期清理无用数据:磁盘空间不足可能引发服务器崩溃,需定期清理日志文件、临时文件和缓存数据,设置logrotate定时压缩和删除旧日志,避免磁盘满载。
安全防护与容错机制
- 检查防火墙与端口配置:防火墙规则错误可能导致服务器无法被访问,需确认服务器端口是否开放(如iptables或ufw规则),并检查是否有IP白名单限制。
- 实现容错与降级策略:通过熔断机制(如Hystrix)防止服务雪崩,当某个依赖服务异常时,自动切换到备用方案或返回默认值,设置timeout和circuit breaker阈值,避免因单个服务故障影响整体系统。
- 定期备份与恢复测试:服务器数据丢失可能导致业务中断,需定期备份数据库和配置文件,并测试恢复流程,使用mysqldump备份MySQL数据库,确保备份文件可恢复。
- 防御DDoS攻击:通过Cloudflare或iptables限制请求频率,防止恶意流量导致服务器过载,设置rate limiting规则,限制单IP的请求次数。
- 安全补丁与更新:未修复的漏洞可能导致服务器被攻击,需定期更新操作系统和应用程序依赖库,使用yum update或apt upgrade安装安全补丁,关闭不必要的服务端口。
预防与长期维护
- 自动化测试与部署:通过CI/CD工具(如Jenkins、GitLab CI)实现代码的自动化测试和部署,减少人为操作失误,在部署前运行单元测试和集成测试,确保代码无明显错误。
- 建立错误预警机制:配置监控告警(如Zabbix、Datadog),当服务器出现异常时及时通知运维人员,设置CPU使用率超过90%的告警阈值,触发邮件或Slack通知。
- 定期压力测试:通过JMeter或Locust模拟高并发场景,验证服务器稳定性,测试1000个并发请求下的响应时间和错误率,优化服务器配置。
- 文档化与知识共享:记录常见错误的解决方案和排查步骤,形成团队知识库,将“数据库连接超时”处理流程写入文档,方便后续快速响应。
- 持续学习与技术迭代:关注行业最佳实践(如Kubernetes的自愈能力、Serverless架构的弹性伸缩),提升服务器稳定性,采用容器化部署减少环境差异,提高故障恢复效率。
服务器错误的解决需要系统性思维,从错误类型识别到日志分析,从配置优化到资源管理,再到安全防护和长期维护,每一步都至关重要,通过实时监控、自动化工具和标准化流程,可显著降低服务器故障率,提升应用程序的稳定性和用户体验,预防性措施(如压力测试、文档化)和持续技术迭代是避免服务器错误的根本之道。

“应用程序中的服务器错误怎么解决,高效解决应用程序服务器错误的方法指南” 的相关文章
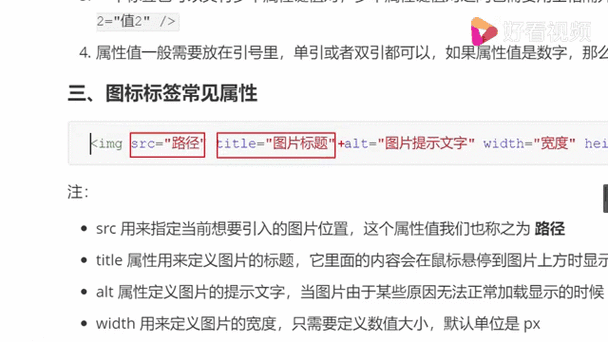
img标签,img标签在现代网页设计中的应用与技巧
img标签是HTML中用于插入图像的标签,它允许在网页中嵌入图片,并通过属性如src指定图片的URL,alt提供图片的替代文本,width和height设置图片尺寸,以及align调整图片的对齐方式,img标签本身不包含任何可见内容,但它是网页设计中展示图像的关键元素。解析img标签** 大家好,...

国内真正的永久免费砖石,国内独家永久免费钻石资源揭秘
国内推出一款真正的永久免费砖石,无需任何费用即可获得,用户只需下载指定应用,即可免费获得砖石奖励,无需充钱,此活动旨在让用户体验到公平、公正的游戏环境,让更多玩家享受游戏乐趣。国内真正的永久免费砖石 真实用户解答: 大家好,最近我在网上看到一个广告,说国内有一个网站可以永久免费领取砖石,真的假的...

colspan怎么用,如何使用colspan属性
colspan属性用于HTML表格中,用于指定一个单元格应横跨的列数,在表格的`或标签内使用colspan属性,并赋予它一个整数,表示该单元格应横跨多少列,colspan="3"`意味着该单元格会占据三列的空间,此属性适用于表格的行,使得表格布局更加灵活和紧凑。colspan怎么用 用户解答:...

余割函数图像与性质,余割函数的图像解析与性质探讨
余割函数,即csct函数,是三角函数的一种,其图像呈现周期性波动,在y轴两侧无限延伸,余割函数在第一、三象限为正值,在第二、四象限为负值,函数在x=π/2+kπ(k为整数)处取得无穷大值,在x=-π/2+kπ(k为整数)处取得无穷小值,余割函数的图像具有垂直渐近线,即x=π/2+kπ(k为整数),余...

jquery旋转动画,实现jQuery旋转动画的技巧与示例
jQuery旋转动画是一种利用jQuery库实现的网页元素旋转效果,通过简单的代码,可以轻松控制HTML元素的旋转角度,实现360度旋转、顺时针或逆时针旋转等效果,动画可以应用于图片、图标或任何可旋转的DOM元素,通过CSS3的transform属性和jQuery的动画函数如.animate()来实...
nodejs php,Node.js与PHP,现代Web开发的双剑合璧
Node.js 和 PHP 都是流行的服务器端编程语言,用于构建高性能的Web应用,Node.js 使用 JavaScript,以其非阻塞I/O和事件驱动特性著称,适合构建实时应用和快速Web服务,PHP 则历史悠久,被广泛用于内容管理系统和电子商务平台,两者各有优势,Node.js 更适合快速开发...
- 最新发布
-

2分钟前

9分钟前
13分钟前

19分钟前

28分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言