python爬国外网站,Python高效爬取国外网站攻略
Python爬取国外网站通常涉及使用爬虫框架如Scrapy或requests库,以及处理HTTP请求、解析HTML内容、分析CSS选择器等步骤,设置请求头以模拟浏览器访问,然后发送请求获取网站数据,利用BeautifulSoup或lxml等库解析HTML,提取所需信息,还需注意遵守目标网站的robots.txt规则,处理JavaScript渲染的页面可能需要Selenium或Puppeteer,在爬取过程中,还需处理异常、分页和并发请求等问题,以确保数据抓取的效率和准确性。
Python爬国外网站:轻松掌握
用户解答: 大家好,我是一名Python爱好者,最近在研究如何使用Python爬取国外网站的数据,我发现国外的网站对于爬虫的限制比较多,不知道该如何入手,请问各位大神有没有什么好的建议呢?
我将从以下几个方面为大家地讲解如何使用Python爬取国外网站的数据。
一:了解国外网站反爬虫机制
- 了解HTTP请求:了解HTTP请求的基本原理,包括GET和POST请求,以及请求头(Headers)的重要性。
- 分析网站结构:通过分析网站的结构,找出目标数据所在的URL和标签。
- 识别反爬虫策略:了解常见的反爬虫策略,如IP封禁、验证码、Cookies验证等。
二:使用Python库进行爬虫开发
- requests库:使用requests库发送HTTP请求,获取网页内容。
- BeautifulSoup库:使用BeautifulSoup库解析HTML文档,提取所需数据。
- Scrapy框架:使用Scrapy框架进行大规模数据爬取,提高效率。
三:绕过国外网站反爬虫策略
- 代理IP:使用代理IP绕过IP封禁,提高爬虫成功率。
- 更换User-Agent:模拟不同浏览器访问网站,降低被识别为爬虫的风险。
- 设置请求间隔:设置合理的请求间隔,避免短时间内发送过多请求。
四:处理爬取到的数据
- 数据清洗:对爬取到的数据进行清洗,去除无用信息。
- 数据存储:将清洗后的数据存储到数据库或文件中,方便后续处理。
- 数据分析:对存储的数据进行分析,提取有价值的信息。
五:遵守法律法规和道德规范
- 尊重版权:在爬取数据时,要尊重网站的版权,不得用于非法用途。
- 保护隐私:在爬取数据时,要保护用户隐私,不得泄露用户信息。
- 合理使用:合理使用爬取到的数据,不得滥用。
通过以上五个方面的讲解,相信大家对使用Python爬取国外网站的数据有了更深入的了解,下面,我将结合实际案例,为大家演示如何使用Python爬取国外网站的数据。
案例:爬取国外新闻网站文章标题和摘要
- 分析网站结构:通过分析网站结构,找出文章标题和摘要所在的URL和标签。
- 编写爬虫代码:使用requests库发送HTTP请求,获取网页内容;使用BeautifulSoup库解析HTML文档,提取文章标题和摘要。
- 存储数据:将爬取到的数据存储到数据库或文件中。
代码示例:
import requests
from bs4 import BeautifulSoup
# 网站URL
url = 'https://example.com/news'
# 发送HTTP请求
response = requests.get(url)
# 解析HTML文档
soup = BeautifulSoup(response.text, 'html.parser')
# 提取文章标题和摘要s = soup.find_all('h2', class_='title')
abstracts = soup.find_all('p', class_='abstract')
# 存储数据 abstract in zip(titles, abstracts):
print(title.text, abstract.text)
通过以上代码,我们可以轻松地爬取国外新闻网站的文章标题和摘要,这只是一个小案例,实际应用中,我们需要根据具体情况进行调整。
使用Python爬取国外网站的数据,需要掌握一定的技术知识,同时要遵守法律法规和道德规范,希望本文能为大家提供一些帮助,祝大家学习愉快!
其他相关扩展阅读资料参考文献:
法律与伦理风险规避
- 遵守robots.txt规则
爬虫操作前必须检查目标网站的robots.txt文件,明确允许爬取的路径和频率。若未遵循该规则,可能被网站封禁或面临法律诉讼,亚马逊的robots.txt限制了对商品详情页的爬取频率,需在代码中设置请求间隔。 - 尊重数据使用协议
许多国外网站通过服务条款限制爬虫行为,如禁止商业用途或要求授权。擅自抓取敏感数据(如用户信息)可能违反GDPR等国际隐私法规,需确保数据用途符合法律框架。 - 避免DDoS攻击嫌疑
高频请求易被误判为恶意攻击。需在代码中加入随机延迟和请求头伪装,用户行为,降低被封IP的概率,使用time.sleep()随机休眠1-3秒,或伪造User-Agent字段。
技术实现核心要点
- 选择合适库与工具
Python的requests库适合基础爬取,但需配合BeautifulSoup或lxml解析HTML。复杂场景建议使用Scrapy框架,其内置的异步处理和数据管道能显著提升效率。 - 处理动态加载内容
国外网站常采用JavaScript动态渲染页面,传统requests无法获取完整数据,需使用Selenium或Playwright模拟浏览器操作,例如通过driver.get()加载网页后提取DOM元素。 - 应对反爬机制
网站常设置验证码、IP封锁或请求频率限制。需在代码中集成验证码识别服务(如2Captcha)或IP代理池,通过proxies参数轮换IP地址,绕过限制。
实战案例解析
- 亚马逊商品信息抓取
目标:提取商品标题、价格和评价。需解析动态加载的AJAX接口,通过Chrome开发者工具定位API请求地址,使用requests.get()获取JSON数据。 - Reddit论坛数据采集
关注:抓取帖子标题、作者和评论。需处理OAuth认证,通过praw库登录账号后获取API权限,避免因未授权导致的403错误。 - Twitter实时数据抓取
需求:获取推文内容和时间戳。需使用Twitter API v2,申请API密钥后调用GET /2/tweets/search接口,设置查询参数(如关键词、时间范围)过滤数据。
反爬策略应对技巧
- IP代理池搭建
直接使用第三方代理服务(如BrightData),通过proxies参数动态切换IP,避免单点IP被封,可设置代理类型(HTTP/HTTPS)和地理位置(欧美/亚洲)匹配目标网站需求。 - 请求头模拟与指纹混淆
伪造User-Agent和Referer字段,模拟主流浏览器(如Chrome 120)的请求头,使用random模块随机生成Accept-Language值,避免被识别为爬虫。 - 分布式爬虫部署
利用Scrapy-Redis实现任务分发,将爬取任务存入Redis队列,由多台机器并行处理,可设置分布式日志和任务状态监控,确保爬虫稳定性。
数据处理与存储优化
- 数据清洗标准化
使用Pandas库处理重复和缺失值,例如通过drop_duplicates()和fillna()清理抓取数据,对非结构化文本需应用正则表达式提取关键信息(如价格、评分)。 - 多维度存储方案
结构化数据推荐存储于MySQL或PostgreSQL,非结构化数据可用MongoDB保存。实时分析需求可采用Elasticsearch,通过索引字段实现快速检索和可视化。 - 自动化报告生成
使用Jinja2模板引擎生成HTML报告,整合抓取数据并添加图表,通过Matplotlib绘制价格趋势图,或使用Plotly生成交互式数据看板,提升数据价值。
Python爬虫技术在抓取国外网站数据时具有显著优势,但需兼顾法律合规、技术实现和数据安全。掌握核心库的使用、反爬策略的应对及数据处理的技巧,才能在实际应用中高效完成任务,建议从简单网站(如新闻站点)入手,逐步积累经验后挑战复杂目标(如社交平台)。始终遵循“最小必要原则”,确保爬虫行为在合法范围内,避免因技术滥用导致的负面影响。
“python爬国外网站,Python高效爬取国外网站攻略” 的相关文章
编程类型,编程领域的分类解析
您未提供具体内容,因此我无法生成摘要,请提供相关内容,以便我能够根据内容生成摘要。探秘编程类型 用户解答: 嗨,我最近在学习编程,但是对编程类型有点困惑,我听说有前端和后端编程,还有全栈开发,这些到底有什么区别呢?能不能给我简单介绍一下? 一:前端编程 定义: 前端编程,顾名思义,是指负责...
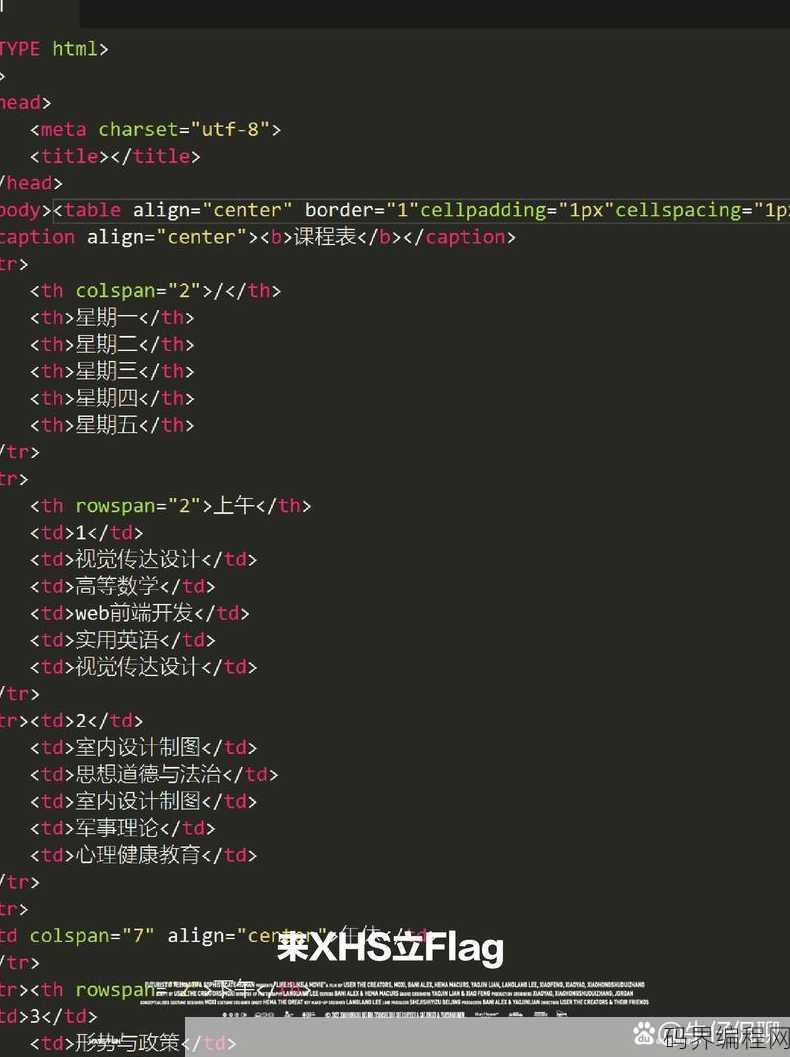
html文字滚动,HTML实现文字滚动效果教程
HTML文字滚动通常指的是在网页上实现文字的自动或手动滚动效果,这可以通过CSS样式和JavaScript脚本来实现,使用CSS,可以通过设置overflow属性为hidden并配合white-space为nowrap来创建一个滚动容器,然后通过修改height属性来限制内容的高度,从而触发滚动,J...
beanfun注册,Beanfun官方注册指南
Beanfun注册流程简要的介绍:用户需访问Beanfun官方网站,填写个人资料,包括姓名、邮箱等,并设置密码,随后,通过邮箱验证激活账户,注册成功后,用户可享受Beanfun提供的游戏、娱乐等服务,请注意保护个人信息,确保账户安全。beanfun注册全攻略:轻松开启游戏之旅 真实用户解答: 大...
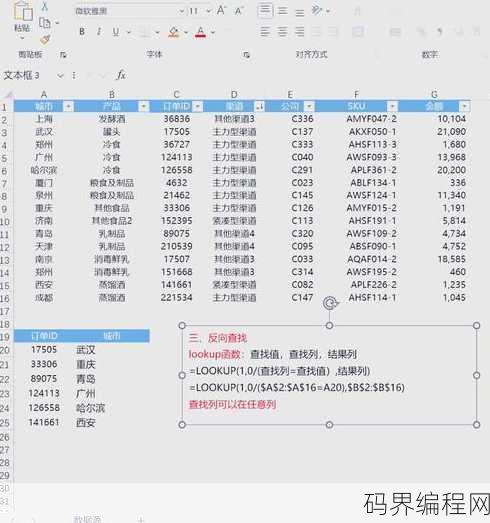
lookup函数实例,探索lookup函数的实际应用案例
lookup函数实例通常指的是在编程或数据处理中使用lookup函数来查找特定值或信息,在Excel中,lookup函数可以用来从数据表中查找与指定值匹配的值,以下是一个简单的lookup函数实例摘要:,在Excel中,lookup函数通过指定查找值和查找范围,返回与查找值相匹配的第一个值,若要在销...

绝世剑神 林辰,剑神林辰,绝世锋芒
《绝世剑神 林辰》讲述了一位天才少年林辰,因身世之谜而踏上修炼之路,历经磨难,凭借一柄绝世神剑,逐渐揭开家族沉睡千年的秘密,在追求武道巅峰的过程中,他结识了红颜知己,结识了挚友,更与邪恶势力展开了一场惊心动魄的较量,凭借坚韧不拔的意志和卓越的剑术,林辰终成一代绝世剑神。【用户解答】 嗨,大家好!最...

网页设计与制作期末考试,网页设计与制作期末考试总结
本次网页设计与制作期末考试主要涵盖网页设计的基本原则、HTML/CSS基本语法、网页布局技术、响应式设计、JavaScript基础应用等内容,考生需掌握网页制作流程,能够独立完成一个具有良好用户体验的网页设计,考试形式包括理论知识和实际操作两部分,旨在评估学生对网页设计与制作知识的掌握程度。 大家...
- 最新发布
-
6分钟前
11分钟前
16分钟前

25分钟前
32分钟前
- 热门阅读
-

918 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言