怎么解析网页源代码,网页源代码解析全攻略
解析网页源代码通常涉及以下步骤:使用浏览器开发者工具(如Chrome的“检查”功能)获取网页的HTML源代码,可以使用编程语言如Python,借助库如BeautifulSoup或lxml来解析HTML,通过这些库,可以提取特定标签、属性或文本内容,对于更复杂的JavaScript渲染的网页,可能需要使用如Selenium工具模拟浏览器行为,对解析得到的数据进行清洗和整理,以满足特定需求。
如何解析网页源代码——新手指南
用户解答: 嗨,我最近在学习如何开发网站,但是看到网页源代码的时候总是感到一头雾水,我想知道,有没有什么简单的方法可以解析网页源代码,以便更好地理解网页的结构和内容呢?
下面,我就来为大家地讲解如何解析网页源代码。

一:什么是网页源代码?
- 定义:网页源代码是构成网页内容的原始HTML、CSS和JavaScript代码。
- 作用:通过解析源代码,我们可以了解网页的结构、样式和交互逻辑。
- 工具:浏览器开发者工具(如Chrome DevTools)可以方便地查看和编辑网页源代码。
二:如何查看网页源代码?
- 浏览器开发者工具:在大多数现代浏览器中,按下F12或右键选择“检查”即可打开开发者工具。
- 查看元素:在元素面板中,可以查看和编辑网页中的HTML元素。
- 网络面板:网络面板可以查看网页加载的所有资源,包括HTML、CSS、JavaScript等。
三:如何解析HTML?
- :HTML标签定义了网页的结构,如
<div>、<p>、<a>等。 - 属性:标签的属性提供了额外的信息,如
<a href="url">。 - 嵌套:HTML标签可以嵌套使用,形成复杂的结构。
- 工具:使用HTML解析库(如BeautifulSoup)可以方便地解析和操作HTML。
四:如何解析CSS?
- 选择器:CSS选择器用于定位和样式化HTML元素。
- 属性:CSS属性定义了元素的样式,如颜色、字体、布局等。
- 规则:CSS规则由选择器和属性组成,用于描述样式。
- 工具:使用CSS解析库(如CSSOM)可以提取和修改CSS样式。
五:如何解析JavaScript?
- 脚本:JavaScript代码通常位于
<script>标签中。 - 函数:JavaScript函数用于执行特定任务。
- 事件:JavaScript可以响应用户操作,如点击、滚动等。
- 工具:使用JavaScript解析库(如JSDOM)可以执行和调试JavaScript代码。
通过以上五个的讲解,相信大家对如何解析网页源代码有了更深入的了解,下面是一些总结:
- 了解基础:熟悉HTML、CSS和JavaScript的基本语法和结构。
- 使用工具:熟练使用浏览器开发者工具和其他解析库。
- 实践操作:通过实际操作来提高解析网页源代码的能力。
- 持续学习:随着技术的发展,不断学习新的解析方法和技巧。
希望这篇文章能帮助到那些对解析网页源代码感到困惑的新手,实践是检验真理的唯一标准,多动手操作,你一定会越来越熟练!
其他相关扩展阅读资料参考文献:
解析网页源代码是互联网技术学习与开发中的核心技能之一,无论是数据抓取、网站分析还是前端调试,都需要对网页源代码有清晰的理解,本文将从工具选择、基本结构、常见解析方法、实战应用和注意事项五个维度展开,帮助读者快速掌握关键要点。
工具选择:高效解析的关键
-
浏览器开发者工具
所有现代浏览器(如Chrome、Firefox)均内置开发者工具,右键点击页面选择“检查”即可打开,该工具能实时显示HTML、CSS和JavaScript代码,支持元素定位、代码修改和网络请求监控,是初学者的首选。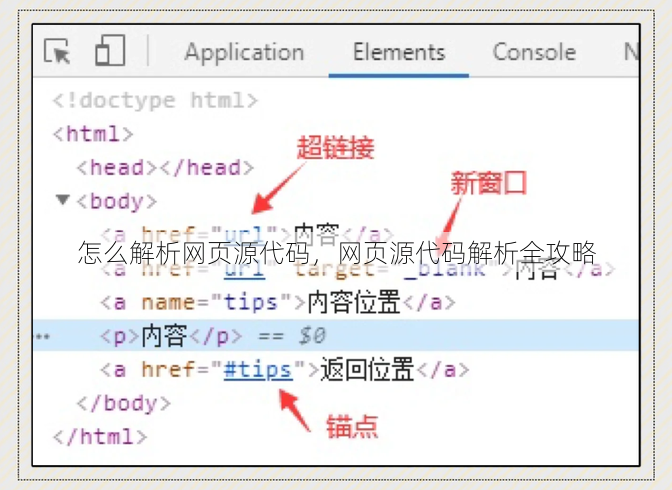
-
代码编辑器
使用专业编辑器(如VS Code、Sublime Text)可提升解析效率。安装HTML/CSS语法高亮插件能更直观地识别代码结构,同时支持代码折叠、搜索替换等功能,适合处理复杂源代码。 -
专用解析库
对于开发者,Python的BeautifulSoup和PyQuery是解析HTML的常用工具,而Selenium则能模拟浏览器操作,处理动态加载的内容。Node.js的Cheerio同样适用于快速解析网页数据。 -
在线工具
W3C Validator可验证HTML代码合法性,HTML Tidy能格式化乱码代码,这些工具适合快速检查代码问题,但无法处理复杂逻辑分析。 -
命令行工具
curl和wget能下载网页源代码,xmllint可验证XML/HTML格式,对于需要批量处理的场景,命令行工具能显著提升效率。
基本结构:理解代码的底层逻辑
-
HTML标签
网页源代码以HTML标签为核心,如<html>、<body>、<div>等,标签的嵌套关系决定了页面布局,通过标签层级可定位元素,例如<div class="gjqaerjgeihgjdfb3806-313e-f4fb-dea1 content">通常包含主要内容。
-
CSS样式
CSS代码通过<style>标签或外部文件定义,控制页面的视觉表现。内联样式(如style="color:red;")直接作用于元素,而外部样式表通过<link>引用,便于统一管理。 -
JavaScript脚本
JavaScript代码负责动态交互,通常通过<script>标签嵌入,关键功能包括事件监听、数据动态加载和DOM操作。注意:动态内容需等待脚本执行后才能完整解析。 -
元数据
<meta>定义网页元信息,如字符编码(charset="UTF-8")、页面描述(name="description")和关键词(name="keywords"),这些数据对SEO和浏览器渲染至关重要。 -
文档类型声明
<!DOCTYPE html>声明文档类型,确保浏览器以标准模式解析,缺失该声明可能导致页面显示异常,尤其在旧版浏览器中。
常见解析方法:灵活应对不同场景
-
正则表达式
正则表达式适合提取简单模式的数据,如邮箱地址或电话号码,但解析复杂结构时容易出错,需谨慎处理嵌套标签和特殊字符。 -
DOM解析
DOM(文档对象模型)解析将网页转化为可操作的树状结构,便于逐层分析元素,JavaScript中的document.getElementById()可直接获取指定元素。 -
XPath定位
XPath表达式通过路径语法定位元素,如//div[@class='gjqaerjgeihgjdfbad2e-ec1d-2071-3806 box'],它在处理复杂层级结构时优势明显,但需熟悉语法规则,否则易导致定位失败。 -
CSS选择器
CSS选择器(如.content p)比XPath更简洁,适合快速定位元素,结合JavaScript库(如jQuery)可实现高效操作,但对动态内容支持有限。 -
API接口调用
通过浏览器开发者工具的Network面板,可直接查看网页加载的API接口,解析API返回的数据(如JSON)能获取更结构化的信息,但需注意接口权限和反爬机制。
实战应用:从理论到操作
-
数据抓取
使用Python的requests库下载网页,再通过BeautifulSoup提取目标数据,抓取商品价格需定位<span class="gjqaerjgeihgjdfb313e-f4fb-dea1-f0ba price">标签并解析其内容。 -
自动化测试
Selenium可模拟用户操作,验证网页元素是否正确加载,测试登录功能时,需解析<input type="text">的ID和值,确保表单提交逻辑无误。 -
网页逆向工程
分析JavaScript代码可逆向破解网页功能,某些网站通过动态生成<script>实现数据加密,需用开发者工具调试脚本并提取关键逻辑。 -
SEO优化
检查<meta>是SEO优化的基础,优化页面描述时需确保name="description"的文本简洁且包含关键词,提升搜索引擎排名。 -
前端调试
通过开发者工具的Console面板,可直接执行JavaScript代码调试,修改<div>的样式或添加日志输出,快速定位页面问题。
注意事项:避免常见陷阱
-
法律风险
解析网页源代码需遵守robots.txt规则,避免抓取受版权保护的内容,商业网站可能限制爬虫访问,需提前确认授权协议。 -
处理
AJAX加载的数据无法通过静态解析获取,需使用Selenium或Puppeteer等工具模拟页面交互,社交媒体动态内容需等待异步请求完成。 -
编码问题
确保网页编码与解析工具一致,否则可能导致乱码,UTF-8编码的网页若用GBK解析,会出现字符显示异常。 -
性能优化
避免过度解析,减少不必要的标签和脚本处理,仅提取关键数据字段,而非遍历整个页面结构,提升解析效率。 -
数据格式转换
解析后的数据需转换为合适格式,如JSON或CSV,使用Python的json库将<script>中的数据解析为字典,便于后续处理。
掌握解析的核心价值
解析网页源代码不仅是技术操作,更是理解网页运行机制的关键。无论是开发、测试还是数据分析,掌握工具选择、结构解析和方法适配是成功的基础,通过不断实践,读者可逐步提升对网页源代码的分析能力,应对更复杂的互联网场景。解析的最终目标是提取有价值的信息,而非盲目复制代码。
“怎么解析网页源代码,网页源代码解析全攻略” 的相关文章

绝世剑神叶云免费阅读,叶云,绝世剑神传奇免费畅读
《绝世剑神叶云》是一部免费阅读的武侠小说,讲述了主角叶云凭借绝世剑法,历经磨难,最终成为一代剑神的传奇故事,在江湖中,叶云以一柄神剑,挑战各方势力,守护正义,谱写了一段荡气回肠的武侠传奇。:绝世剑神叶云免费阅读——带你领略剑道巅峰的奇幻之旅 : 作为一个热爱玄幻小说的读者,我最近迷上了一本名为《...

vb语言编写,VB语言编程技巧与应用
您未提供具体内容,因此我无法为您生成摘要,请提供您希望摘要的内容,以便我为您生成合适的摘要。VB语言编写之旅 用户解答: 嗨,我是一名初学者,最近对VB语言很感兴趣,想学习一下,但是我对VB语言一无所知,不知道从何入手,请问有没有什么好的建议或者教程推荐呢? 下面,我将从几个出发,为你详细解答...
在线编程课哪个比较好,2023年度在线编程课程对比,哪家更胜一筹?
在线编程课程种类繁多,选择适合自己的很重要,推荐以下几款:1.慕课网:课程丰富,涵盖前端、后端、移动端等多个领域;2.极客学院:注重实战,课程内容紧跟行业趋势;3.网易云课堂:课程体系完善,适合初学者和进阶者;4.腾讯课堂:课程质量较高,师资力量雄厚;5.猿辅导:针对青少年编程教育,注重培养编程思维...
怎么做程序员,成为程序员之路指南
成为一名程序员,首先需要掌握编程语言,如Python、Java等,学习基础知识,如数据结构、算法和计算机网络,通过实际项目积累经验,参与开源项目或自己动手开发,不断学习新技术,提高解决问题的能力,加强团队协作和沟通技巧,适应快节奏的软件开发环境,不断实践和反思,逐步成长为一名优秀的程序员。 嗨,我...

css让div居中,CSS实现Div水平垂直居中
CSS实现div居中的方法有几种:1. 使用flex布局;2. 使用绝对定位和transform属性;3. 使用表格布局;4. 使用grid布局,具体实现步骤如下:1. 使用flex布局,将父元素设置为display: flex;,然后设置justify-content: center;和align...
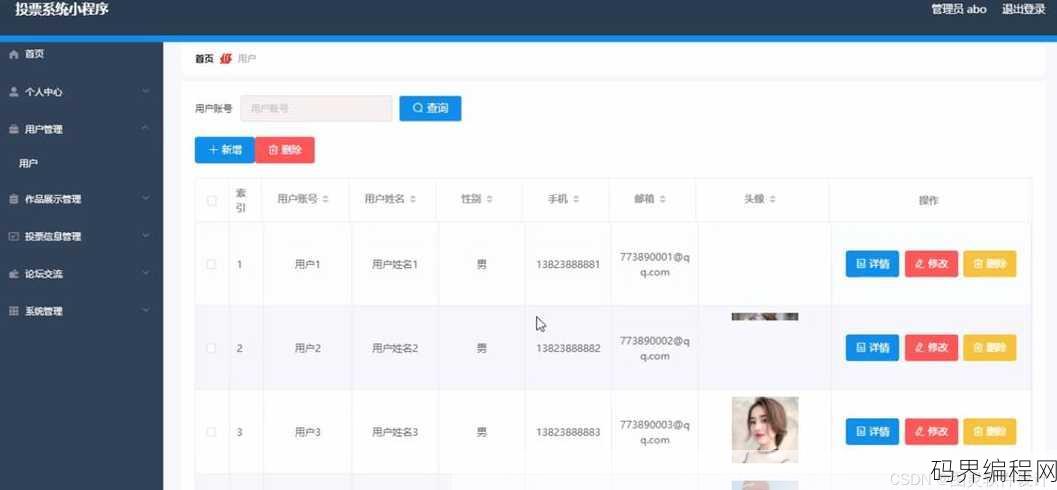
asp投票系统源码,完整ASP投票系统源码解析与下载
ASP投票系统源码是一套基于Active Server Pages技术的投票系统代码,该系统允许用户通过网页进行投票,后台通过ASP脚本处理投票数据,支持多选、单选等多种投票方式,源码包括投票页面的设计和数据库操作脚本,适用于网站增加互动性和用户参与度,系统简单易用,适合中小型网站或活动进行在线投票...
- 最新发布
-

2分钟前
8分钟前
15分钟前

22分钟前

29分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言