如何简单的开发hadoop应用,轻松入门,Hadoop应用开发指南
开发Hadoop应用可以遵循以下简单步骤:,1. 确定需求:明确应用目的和数据类型。,2. 环境搭建:安装Java、Hadoop和必要的依赖库。,3. 编写代码:使用Hadoop提供的API进行数据处理,如MapReduce或YARN。,4. 测试:在本地或集群环境中测试应用,确保其正确性。,5. 部署:将应用部署到Hadoop集群,进行大数据处理。,6. 调优:根据处理结果调整配置,优化性能。,7. 维护:定期检查和更新应用,确保其稳定运行。
如何简单开发Hadoop应用**
用户解答
“我一直对大数据处理很感兴趣,但听说Hadoop开发复杂又困难,我是一名普通的软件工程师,没有太多背景知识,想了解一下如何简单开发Hadoop应用,有没有什么入门级的建议?”
一:环境搭建
选择合适的Hadoop版本
- 原因:选择与你的项目需求相匹配的版本,例如Hadoop 2.x适合大规模集群,Hadoop 3.x提供了更高效的数据处理。
- 步骤:在Hadoop官网查看最新版本信息,根据需求选择合适的版本。
- 工具:使用Hadoop发行版,如Cloudera、Hortonworks等,它们提供了预配置的环境。
安装Java
- 原因:Hadoop基于Java开发,需要Java运行环境。
- 步骤:下载并安装与Hadoop兼容的Java版本。
- 验证:运行
java -version检查Java是否安装成功。
配置Hadoop环境变量
- 原因:设置环境变量可以让系统识别Hadoop的安装路径。
- 步骤:在系统环境变量中添加HADOOP_HOME、PATH等变量。
- 方法:在Windows系统中,通过系统属性设置;在Linux系统中,编辑.bashrc文件。
二:编写MapReduce程序
理解MapReduce编程模型
- 原因:MapReduce是Hadoop的核心,理解其编程模型对开发至关重要。
- 要点:MapReduce包含两个主要步骤:Map和Reduce。
- 资料:阅读官方文档或在线教程,如《Hadoop MapReduce实战指南》。
使用Hadoop Streaming
- 原因:对于简单的MapReduce任务,可以使用Hadoop Streaming,它允许你使用任何语言编写Map和Reduce程序。
- 步骤:编写shell脚本作为Map和Reduce程序,然后通过Hadoop Streaming运行。
- 示例:使用Python编写Map和Reduce函数,通过Hadoop Streaming进行处理。
利用Hadoop API
- 原因:对于复杂的应用,使用Hadoop API可以提供更丰富的功能。
- 步骤:学习Java或Scala等编程语言,使用Hadoop的API编写MapReduce程序。
- 工具:Hadoop MapReduce API、Hadoop Streaming API等。
三:数据处理
熟悉HDFS
- 原因:HDFS(Hadoop Distributed File System)是Hadoop的文件存储系统,了解其特性对数据处理至关重要。
- 要点:HDFS是分布式、高容错性的文件系统。
- 操作:使用Hadoop命令行工具如hdfs dfs进行文件操作。
使用Hive和Pig
- 原因:Hive和Pig是Hadoop的数据处理工具,可以简化SQL查询和数据转换。
- Hive:适用于数据仓库和复杂查询,使用类似SQL的语法。
- Pig:适用于复杂的数据转换,使用Pig Latin语言。
- 选择:根据数据处理需求选择合适的工具。
利用Hadoop生态圈工具
- 原因:Hadoop生态圈提供了多种工具,可以扩展Hadoop的功能。
- 工具:Spark、HBase、Flink等。
- 应用:根据具体需求选择合适的工具,例如Spark适合实时数据处理,HBase适合非结构化数据存储。
四:测试和优化
编写单元测试
- 原因:单元测试可以帮助确保代码的正确性和稳定性。
- 步骤:使用JUnit等测试框架编写测试用例。
- 实践:为MapReduce程序编写单元测试,确保其逻辑正确。
性能监控
- 原因:监控Hadoop集群的性能可以帮助优化配置和资源分配。
- 工具:使用Ganglia、Nagios等监控工具。
- 指标:监控CPU、内存、磁盘IO等指标。
调优Hadoop配置
- 原因:优化Hadoop配置可以提高性能和效率。
- 步骤:根据集群规模和任务类型调整Hadoop配置参数。
- 参数:mapreduce.job.reduce.slowstart.completedmaps、dfs.replication等。
五:部署和运维
部署Hadoop集群
- 原因:部署Hadoop集群是使用Hadoop的基础。
- 步骤:使用Cloudera Manager、Ambari等工具部署集群。
- 注意事项:确保网络配置正确,集群组件之间通信正常。
实施自动化运维
- 原因:自动化运维可以提高运维效率,减少人工干预。
- 工具:使用Ansible、Puppet等自动化工具进行配置管理和自动化部署。
- 实践:编写自动化脚本,自动化处理日常运维任务。
安全性考虑
- 原因:保护Hadoop集群和数据安全至关重要。
- 措施:使用Kerberos进行身份验证,配置防火墙和SELinux等。
- 最佳实践:定期进行安全审计,确保集群安全。
通过以上步骤,即使是初学者也可以简单开发Hadoop应用,实践是学习的关键,多尝试、多实践,你会逐渐掌握Hadoop开发技能。
其他相关扩展阅读资料参考文献:
环境准备与基础配置
1 安装Hadoop
选择适合的Hadoop版本(如Hadoop 3.x),从Apache官网下载并解压到指定目录,确保系统已安装Java 8或更高版本,通过java -version验证。
2 配置环境变量
将Hadoop的bin目录添加到系统PATH变量,设置HADOOP_HOME环境变量,并修改~/.bashrc或systemd配置文件,使环境变量生效。
3 验证安装
运行hadoop version检查版本信息,启动HDFS和YARN服务后,使用jps命令确认NameNode、DataNode、ResourceManager等进程是否正常运行。
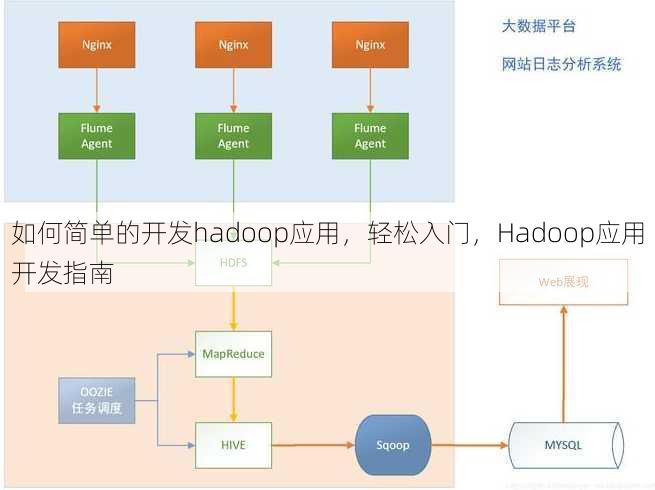
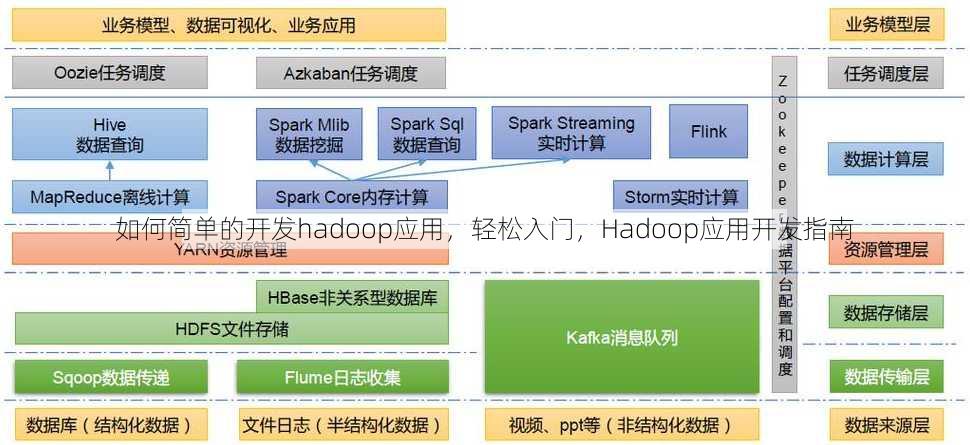
核心组件与数据处理流程
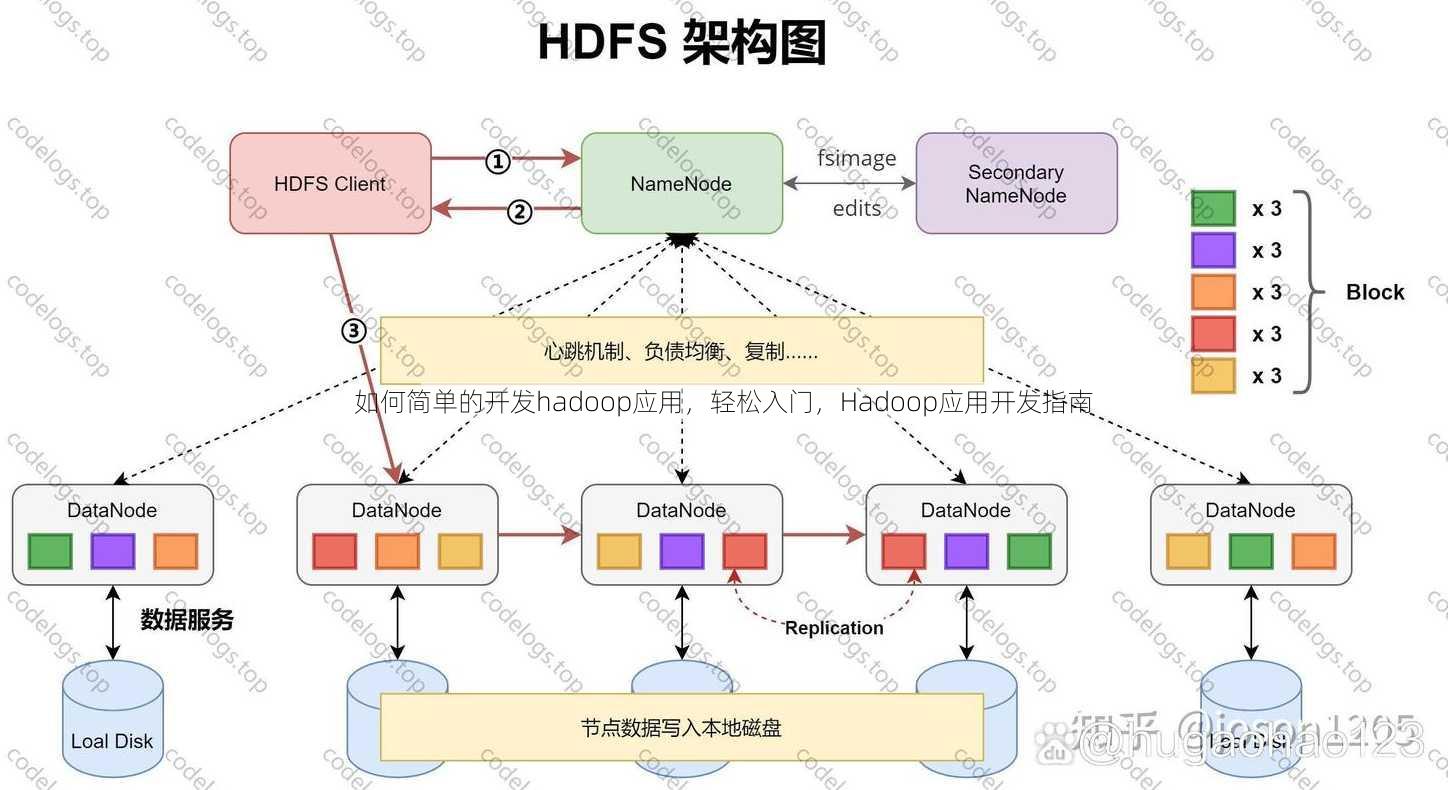
1 HDFS存储原理
HDFS是分布式文件系统,将大文件切分为128MB的数据块存储在集群中,通过副本机制(默认3份)保障数据可靠性,数据块大小和副本数可通过hdfs-site.xml配置。
2 MapReduce编程模型
MapReduce分为Map和Reduce两个阶段:Map阶段将输入数据拆分为键值对并处理,Reduce阶段汇总结果并输出,编写代码时需继承Mapper和Reducer类,定义map()和reduce()方法。
3 YARN资源管理
YARN负责集群资源调度,通过yarn-site.xml配置ResourceManager和NodeManager的通信端口,提交任务时使用yarn submit命令,监控任务状态可通过yarn application -list查看。
开发工具与代码实现
1 选择开发工具
推荐使用Eclipse或IntelliJ IDEA作为开发环境,安装Hadoop插件(如Hadoop Eclipse Plugin)以简化本地调试和集群连接。
2 编写MapReduce代码
以WordCount为例,代码需包含Mapper类处理输入文本,Reducer类统计词频,注意使用Configuration对象设置Job参数,如job.setJarByClass()指定主类。
3 使用Hive或Pig简化开发
Hive提供类SQL的查询语言,适合结构化数据处理;Pig通过脚本语言(Pig Latin)简化数据流操作,两者均可避免直接编写MapReduce代码,提升开发效率。
调试与性能优化
1 本地模式调试
在单机环境下运行Hadoop程序,通过hadoop jar命令指定-Dmapreduce.job.reduces=0参数,使程序以本地模式执行,快速验证逻辑正确性。
2 性能调优技巧
优化数据分区:根据业务需求合理设置分区键,减少数据倾斜;调整压缩格式:使用Snappy或Gzip压缩中间数据,降低网络传输开销;配置内存参数:通过yarn-site.xml调整yarn.nodemanager.resource.memory-mb提升任务执行效率。
3 常见问题排查
日志分析:查看logs目录下的hadoop-username.log文件,定位运行错误;资源监控:使用yarn node -list检查节点负载,避免资源不足导致任务失败;权限检查:确保HDFS目录权限为777,防止文件读写异常。
部署与维护
1 单机部署
在本地运行Hadoop集群,无需配置多节点,适合学习和测试,启动HDFS和YARN后,直接通过hadoop fs -put上传数据并运行程序。
2 集群部署
在多节点环境中部署Hadoop,需配置core-site.xml(指定HDFS地址)、hdfs-site.xml(设置副本数)、mapred-site.xml(配置MapReduce框架)和yarn-site.xml(定义资源调度器)。
3 日常维护
定期检查磁盘空间:通过hadoop dfs -df命令监控HDFS存储使用情况;备份重要数据:使用hadoop distcp工具复制关键数据到安全存储位置;更新配置参数:根据业务增长调整数据块大小或副本数,优化集群性能。
实际案例与应用场景
1 日志分析
使用Hadoop处理海量日志文件,提取用户行为数据,通过MapReduce统计访问频率最高的IP地址,或使用Hive分析用户点击热图。
2 数据清洗
对原始数据进行去重、格式转换等操作,利用Hadoop的分布式计算能力提升处理速度,使用Pig Latin脚本过滤无效记录并生成标准化数据集。
3 机器学习预处理
在Hadoop集群上运行Spark或Mahout,对大规模数据进行特征提取和模型训练,使用MapReduce实现协同过滤算法,或通过Hive进行数据特征统计。
安全与权限管理
1 开启HDFS安全模式
通过hadoop dfsadmin -safemode on命令进入安全模式,防止未授权用户访问数据,安全模式下,所有写操作会被阻断,直到手动关闭。
2 配置Kerberos认证
在生产环境中,需启用Kerberos认证,通过krb5.conf文件设置Realm和Keytab路径,使用kinit命令生成票据,确保集群访问安全性。
3 权限控制策略
利用HDFS的ACL(访问控制列表)或RBAC(基于角色的访问控制)限制用户对目录的读写权限,使用hadoop fs -chmod修改目录权限,或通过hadoop fs -setfacl设置细粒度访问策略。
未来趋势与扩展建议
1 与云平台结合
将Hadoop部署在AWS EMR、阿里云MaxCompute等云服务上,利用弹性计算资源降低运维成本,云平台通常提供预配置的集群模板,简化部署流程。
2 引入容器化技术
使用Docker打包Hadoop应用,通过docker run命令快速部署到Kubernetes集群,容器化可实现环境一致性,提升应用可移植性。
3 与大数据生态工具联动
结合Flink、Kafka等工具构建实时数据处理流水线,使用Kafka作为数据源,Flink进行流式计算,Hadoop存储结果,形成端到端的数据分析方案。
常见误区与解决方案
1 忽略数据倾斜问题
在MapReduce任务中,若某些Key的数据量远大于其他Key,会导致任务执行缓慢,解决方案:使用Combiner类进行局部分组,或调整分区策略。
2 配置文件错误
错误的core-site.xml或hdfs-site.xml会导致Hadoop无法启动,解决方案:核对配置项(如fs.defaultFS和dfs.replication),确保与集群实际地址一致。
3 忽视资源分配
未合理分配YARN资源可能导致任务排队或失败,解决方案:通过yarn.scheduler.capacity.maximum-am-resource-percent设置资源上限,避免资源争抢。
总结与实践建议
1 简化开发流程
通过Hive、Pig等工具减少对底层MapReduce的依赖,快速实现数据处理需求。
2 注重文档与社区支持
参考官方文档(如Hadoop官方手册)和开源社区(如Stack Overflow)获取最新技术动态和问题解决方案。
3 持续学习与实践
从简单案例(如WordCount)入手,逐步扩展到复杂场景(如实时分析),定期参与Hadoop相关培训或认证,提升技术深度。
工具链推荐
1 开发工具
- Eclipse:集成Hadoop插件,支持代码调试和集群连接。
- IntelliJ IDEA:提供更强大的代码分析功能,适合大型项目开发。
2 数据处理工具 - Hive:适合结构化数据查询,支持SQL语法。
- Pig:通过脚本语言简化数据流操作,适合半结构化数据处理。
3 监控工具 - Ambari:提供图形化界面监控Hadoop集群状态。
- Ganglia:实时监控节点资源使用情况,及时发现瓶颈。
常见问题速查
1 HDFS无法启动
检查hdfs-site.xml中的dfs.replication是否与集群节点数匹配,确保所有DataNode服务正常运行。
2 MapReduce任务失败
查看日志中的ClassNotFoundException或NullPointerException,确认依赖库是否正确打包,代码逻辑是否异常。
3 YARN资源不足
通过yarn.nodemanager.resource.memory-mb调整内存分配,或增加集群节点数量以提升计算能力。
进阶学习方向
1 学习分布式计算框架
深入理解MapReduce的执行原理,探索Spark等更高效的计算框架。
2 掌握数据分区策略
根据数据特征选择合适的分区键,避免数据倾斜影响性能。
3 研究容错与高可用机制
配置HDFS的HA(高可用)模式,确保NameNode故障时集群仍能正常运行。
开发效率提升技巧
1 使用模板代码
编写通用的MapReduce模板,减少重复代码量,提升开发速度。
2 自动化测试
通过Jenkins或TestNG构建自动化测试流程,确保代码在不同数据集下稳定运行。
3 优化代码结构
采用模块化设计,将数据处理逻辑拆分为独立的Mapper和Reducer类,便于维护和扩展。
社区与资源获取
1 参与开源社区
关注Hadoop官方论坛和GitHub仓库,获取最新版本和社区支持。
2 学习在线课程
通过Coursera、Udemy等平台学习Hadoop开发课程,掌握实战技巧。
3 阅读技术博客
参考技术博客(如Cloudera博客)了解最佳实践和常见问题解决方案。
通过以上步骤和技巧,开发者可以快速入门Hadoop应用开发,逐步掌握分布式计算的核心原理。关键在于理解HDFS、MapReduce和YARN的基本功能,并结合实际需求选择合适的工具和优化策略,无论是处理日志、清洗数据还是构建机器学习模型,Hadoop都能提供强大的支持,持续学习和实践是提升Hadoop开发能力的核心路径,同时利用社区资源和工具链可显著降低开发门槛。
“如何简单的开发hadoop应用,轻松入门,Hadoop应用开发指南” 的相关文章
jquery和js的关系,jQuery与JavaScript的紧密联系解析
jQuery是一个快速、小型且功能丰富的JavaScript库,它简化了JavaScript编程中的许多任务,如HTML文档遍历和操作、事件处理和动画,jQuery可以看作是JavaScript的一个扩展,它依赖于JavaScript的核心功能,但不是JavaScript本身,简而言之,jQuery...

php类,PHP类设计与实现指南
PHP类是PHP编程语言中用于组织代码和实现复用的一种结构,它通过定义属性(变量)和方法(函数)来封装数据和操作,使得代码更加模块化和易于维护,类可以创建对象,对象是类的实例,可以通过对象调用类中定义的方法和访问属性,使用类可以提高代码的可读性、可扩展性和可重用性,是PHP面向对象编程(OOP)的核...

哪家编程机构比较好,编程机构哪家强?一探究竟!
在选择编程机构时,应考虑教学质量、师资力量、课程设置、学生评价等多个因素,以下机构在业界口碑较好:XX编程学院,以其严谨的教学体系和资深教师团队著称;YY技术学校,课程全面,注重实践能力培养;ZZ教育中心,学生评价高,就业率优秀,建议根据个人需求和兴趣,实地考察或咨询在读学生,以选择最适合自己的编程...
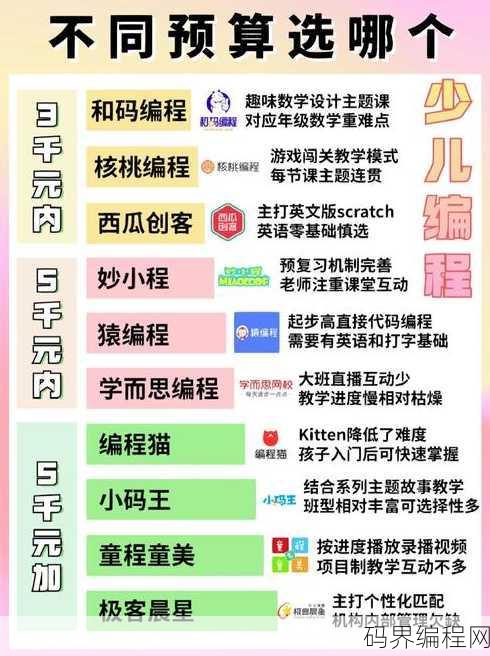
在线编程课哪个比较好,2023年度在线编程课程对比,哪家更胜一筹?
在线编程课程种类繁多,选择适合自己的很重要,推荐以下几款:1.慕课网:课程丰富,涵盖前端、后端、移动端等多个领域;2.极客学院:注重实战,课程内容紧跟行业趋势;3.网易云课堂:课程体系完善,适合初学者和进阶者;4.腾讯课堂:课程质量较高,师资力量雄厚;5.猿辅导:针对青少年编程教育,注重培养编程思维...
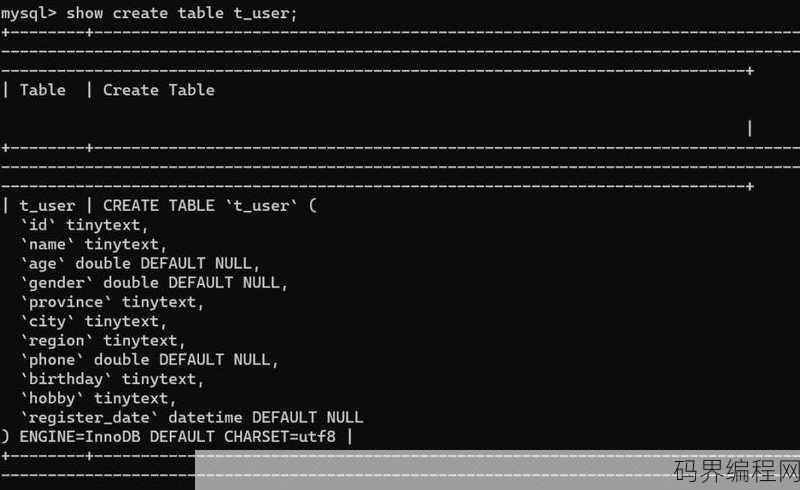
数据库中insert into的用法,数据库基础,Insert into 语句的详细用法解析
INSERT INTO 是SQL语句中用于向数据库表中插入新记录的命令,其基本结构如下:,``sql,INSERT INTO 表名 (列1, 列2, ..., 列N),VALUES (值1, 值2, ..., 值N);,``,这里,“表名”是要插入数据的表名,“列1, 列2, ..., 列N”是表中...

网站制作报价,网站定制服务报价一览
网站制作报价涉及多个因素,包括设计风格、功能需求、页面数量等,基础报价通常包括域名注册、服务器租赁、网站设计、前端开发、后端编程等,定制化服务如电子商务功能、SEO优化、移动适配等会额外收费,具体报价需根据项目详细需求与设计师沟通确定。 大家好,我最近在准备建立一个自己的网站,但不太清楚网站制作的...
- 最新发布
-
1分钟前

8分钟前

15分钟前
21分钟前

26分钟前
- 热门阅读
-

916 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言