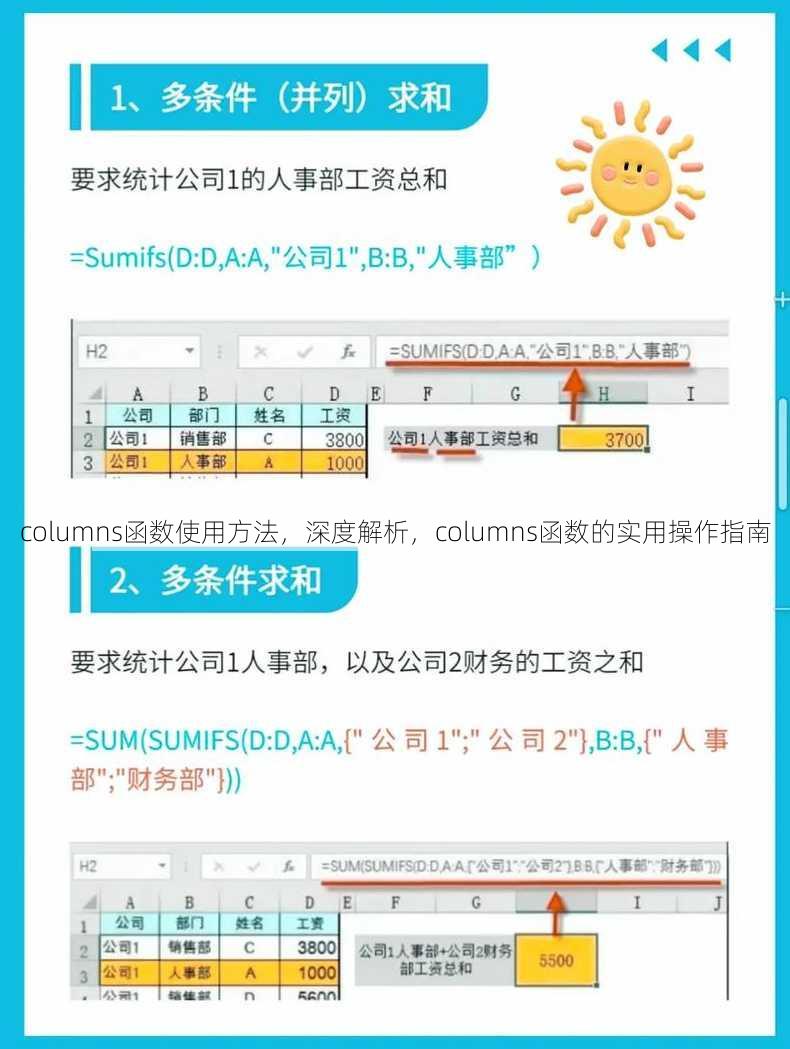
columns函数使用方法,深度解析,columns函数的实用操作指南
columns函数通常用于在编程语言如Python的Pandas库中处理数据框(DataFrame),该函数用于获取DataFrame中所有列的名称,使用方法如下:,``python,import pandas as pd,# 创建一个示例DataFrame,df = pd.DataFrame({, 'A': [1, 2, 3],, 'B': [4, 5, 6],, 'C': [7, 8, 9],}),# 获取所有列的名称,column_names = df.columns,# 输出列名,print(column_names),`,输出将显示DataFrame中的所有列名,如Index,A,B,C,columns`函数也可以接受参数来选择特定的列或返回列名的列表。
嗨,大家好!今天我想和大家分享一个在数据分析中非常有用的函数——columns函数,我最近在使用它时发现,这个函数真的很强大,能够帮助我们轻松地处理和分析数据,今天就来给大家详细介绍一下columns函数的使用方法。
一:columns函数的基本概念
- 定义:columns函数是Python中pandas库的一个函数,用于获取DataFrame中的列名。
- 语法:
df.columns,其中df是DataFrame的变量名。 - 返回值:返回一个包含列名的Series对象。
二:如何获取DataFrame的列名
-
直接使用:如果你已经有一个DataFrame对象,只需在变量名后加上
.columns即可获取列名。
import pandas as pd data = {'Name': ['Tom', 'Nick', 'John'], 'Age': [20, 21, 19]} df = pd.DataFrame(data) print(df.columns)运行上述代码,你会得到输出:
Index(['Name', 'Age'], dtype='object')。 -
通过索引访问:你还可以通过索引访问列名,例如
df.columns[0]会返回第一个列名。print(df.columns[0])
输出:
Name -
通过切片访问:如果你需要获取一部分列名,可以使用切片操作。
print(df.columns[:2])
输出:
Index(['Name', 'Age'], dtype='object')
三:如何获取DataFrame的列数量
-
使用len()函数:直接在列名Series对象上使用len()函数即可获取列数量。
print(len(df.columns))
输出:
2 -
使用len()函数结合索引:如果你需要获取特定列的数量,可以使用索引和len()函数。
print(len(df.columns[:2]))
输出:
2
四:如何修改DataFrame的列名
-
使用rename()函数:直接在DataFrame对象上使用rename()函数并传入列名映射即可修改列名。
df.rename(columns={'Name': 'NameNew'}, inplace=True) print(df.columns)输出:
Index(['NameNew', 'Age'], dtype='object') -
使用列名列表:你可以创建一个包含新列名的列表,并使用columns属性进行赋值。
new_columns = ['NameNew', 'AgeNew'] df.columns = new_columns print(df.columns)
输出:
Index(['NameNew', 'AgeNew'], dtype='object')
五:如何删除DataFrame的列
-
使用del语句:直接使用del语句删除指定列。
del df['Name'] print(df.columns)
输出:
Index(['Age'], dtype='object') -
使用drop()函数:使用drop()函数并传入列名或列名列表,即可删除指定列。
df.drop('Age', axis=1, inplace=True) print(df.columns)输出:
Index([], dtype='object')相信大家对columns函数的使用方法有了更深入的了解,columns函数在数据分析中非常实用,希望大家能够灵活运用,提高数据分析效率。
其他相关扩展阅读资料参考文献:
数据列的创建与访问
- 创建列:使用
df.columns = [...]可直接定义数据框的列名,例如df.columns = ['姓名', '年龄', '城市'],此方法适用于数据导入后需统一列名格式的场景。 - 访问列:通过
df['列名']或df.列名可快速获取单列数据,注意列名需与数据框实际列名完全匹配,否则会报错。 - 修改列:利用
df.rename(columns={旧列名:新列名}, inplace=True)可批量重命名列,inplace=True参数可直接修改原数据框,无需重新赋值。
数据预处理:列的数据类型转换与缺失值处理
- 转换数据类型:通过
df[column].astype(dtype)可将列数据强制转换为指定类型,例如df['年龄'].astype(int),确保数据类型统一是后续分析的前提。 - 处理缺失值:使用
df.dropna(subset=['列名'])删除缺失列,或df.fillna(value, inplace=True)填充缺失值,缺失值处理需结合业务逻辑判断,避免数据失真。 - 标准化/归一化:通过
df[column].apply(lambda x: (x - min)/max)对列数据进行标准化,标准化后的数据更适用于机器学习模型训练。
数据筛选:基于列的条件过滤
- 单列条件筛选:使用
df[df['列名'] > 值]可过滤满足条件的行,例如df[df['年龄'] > 30],条件表达式需严格符合逻辑运算规则。 - 多列组合筛选:通过
df[(df['列名1'] > 值1) & (df['列名2'] < 值2)]实现多列联合过滤,注意布尔运算符优先级,避免条件错误。 - 动态列名筛选:使用字典或列表动态指定列名,例如
df.filter(items=['列名1', '列名2']),适用于列名不确定或需批量处理的场景。
数据透视:列的聚合与分组统计
- groupby分组统计:通过
df.groupby('列名').mean()对列进行分组并计算均值,分组后需指定聚合函数以避免默认计算方式偏差。 - pivot_table透视表:使用
df.pivot_table(values='目标列', index='分组列', aggfunc='sum')生成多维统计表,values和index参数需明确指定,否则会报错。 - 交叉表分析:通过
pd.crosstab(index=行列, columns=列名, values=值列, aggfunc='sum')生成列与行列的交叉频率表,适用于分类变量的关联性分析。
数据合并:列的拼接与关联操作
- 列拼接:使用
pd.concat([df1, df2], axis=1)将两个数据框的列横向合并,axis=1参数确保列拼接而非行拼接。 - 列关联合并:通过
df.merge(right=其他数据框, on='公共列名')基于公共列名合并数据,on参数需与两个数据框的键列名一致。 - 列级联接:使用
df.join(other=其他数据框, on='列名')实现列级联接,join方法默认使用内联接,需根据需求调整类型。
进阶技巧:列的动态操作与性能优化
- 动态列名操作:通过
df.loc[:, '列名1':'列名2']选取连续列区间,或df.loc[:, df.columns.str.contains('关键字')]筛选包含特定关键字的列,动态操作能显著提升代码灵活性。 - 列的性能优化:避免频繁使用
df['列名']访问单列,改用df.values获取底层数据,数值型数据的处理效率远高于列名访问。 - 列的内存管理:通过
df.drop(columns=['冗余列'], inplace=True)删除无用列释放内存,大数据集处理时需及时清理冗余数据。
实际应用:列在数据分析中的关键作用
- 特征工程中的列处理:在构建模型前,通过
df[['列名1', '列名2']]提取特征列,特征列的选择直接影响模型效果。 - 数据可视化中的列映射:使用
df.plot(kind='bar', x='列名1', y='列名2')将列映射到图表的横纵坐标,列映射需与可视化目标一致。 - 数据导出时的列筛选:通过
df.to_csv('文件名.csv', columns=['需保留列名'])导出指定列,避免导出不必要的列节省存储空间。
常见误区与解决方案
- 列名重复问题:合并数据时若出现列名重复,需使用
df.rename(columns={重复列名:新列名}, inplace=True)重命名,重复列名会导致数据混淆。 - 列操作与索引冲突:修改列名后需同步更新索引,否则
df.set_index('列名')可能找不到对应列,列名与索引需保持逻辑一致性。 - 列操作效率低下:避免在循环中频繁修改列,改用向量化操作,例如
df['列名'] = df['列名'].str.replace('旧值', '新值'),向量化操作比逐行处理快百倍以上。
掌握columns函数的核心价值
- 列是数据操作的基石:无论是数据清洗、分析还是可视化,列都是最基础的单元,熟练使用columns函数能大幅提升数据处理效率。
- 灵活应对复杂场景:通过组合条件、分组统计和合并操作,columns函数可解决多维度数据问题,掌握其高级用法是数据分析进阶的关键。
- 优化代码结构与性能:合理使用列操作能简化代码逻辑,减少内存占用,高效利用columns函数是数据科学家必备技能。
延伸学习:列操作与其他函数的协同应用
- 与loc结合定位数据:
df.loc[df['列名'] > 值, ['目标列']]可同时筛选行和列,loc的条件筛选功能能精准控制数据范围。 - 与apply实现复杂计算:
df.apply(lambda row: row['列名1'] + row['列名2'], axis=1)对列进行行级计算,apply适用于自定义函数处理。 - 与query进行高效查询:
df.query('列名1 > 值 and 列名2 < 值', inplace=True)用字符串表达式筛选数据,query语法更简洁且性能更优。
十一、实战案例:列操作在真实数据中的应用
- 电商数据清洗:对订单表的
'订单金额'列使用astype(float)转换类型,并通过df['订单金额'].fillna(0, inplace=True)填充缺失值,确保数据一致性是分析的第一步。 - 用户行为分析:使用
df.groupby('用户ID')['点击次数'].sum()统计每个用户的总点击量,分组统计能揭示用户行为模式。 - 数据整合分析:通过
pd.merge(left=用户表, right=订单表, on='用户ID')合并用户信息与订单数据,列关联是跨数据集分析的核心。
十二、列操作的深度理解与实践
- 列操作贯穿数据全流程:从数据导入到导出,columns函数始终是核心工具,理解其功能能系统性提升数据处理能力。
- 避免常见错误:如列名拼写错误、数据类型不匹配等,错误排查需结合报错信息快速定位。
- 持续学习与实践:通过实际项目反复应用columns函数,实践是掌握复杂操作的最佳途径。
重要提示:
- 列名的大小写敏感性:Pandas对列名区分大小写,例如
df['Age']与df['age']视为不同列,需统一列名格式以避免错误。 - 列操作的链式调用:可将多个列操作串联,例如
df['列名'].astype(int).fillna(0),链式调用能简化代码并提高可读性。 - 列的索引与列名区分:
df.index用于定位行索引,而df.columns控制列名,混淆两者会导致逻辑错误。
通过以上12个的深入解析,可以看出columns函数在Pandas中的核心地位,无论是基础的数据列管理,还是复杂的分析操作,掌握其使用方法都能显著提升数据处理效率。建议在实际项目中结合具体需求,灵活运用columns函数的各类功能,逐步构建完整的数据分析流程。
“columns函数使用方法,深度解析,columns函数的实用操作指南” 的相关文章

损失函数和代价函数,损失函数与代价函数的深度解析与区别对比
损失函数和代价函数是机器学习中用于评估模型预测结果与真实值之间差异的重要概念,损失函数衡量单个预测的误差,而代价函数则是对整个模型性能的总体评估,损失函数通常设计为预测值与真实值之间的差异的某种度量,如均方误差或交叉熵,代价函数则是多个损失函数的加权总和,用于在训练过程中指导模型优化,通过调整模型参...

数据库期末考试题及答案2022,2022年数据库期末考试试题及答案汇编
《数据库期末考试题及答案2022》提供了2022年度数据库课程的期末考试题目及对应答案,内容涵盖数据库基础理论、SQL语言、数据库设计、关系数据库标准理论等,旨在帮助考生全面复习和巩固数据库知识,为考试做好准备。 “数据库期末考试题及答案2022”,这个标题对于正在为数据库课程末考做准备的同学来说...
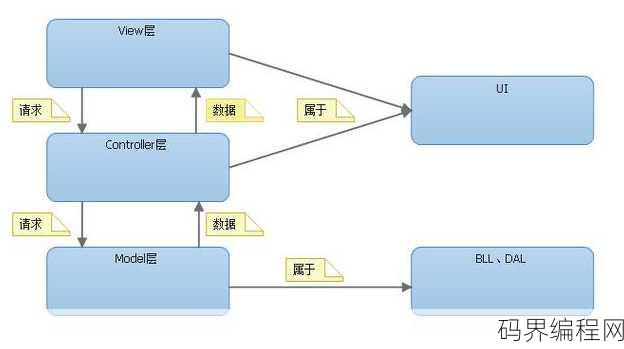
struts2工作原理和mvc,深入解析Struts2工作原理与MVC模式
Struts2是一个基于MVC(模型-视图-控制器)模式的Java Web框架,其工作原理如下:用户通过浏览器发送请求到服务器;Struts2的过滤器拦截请求,并将其交给Action处理器;Action处理器根据请求调用相应的Action类,该类负责处理业务逻辑;Action类将处理结果传递给视图层...

forms,探索表单设计与应用新趋势
您未提供具体内容,因此我无法生成摘要,请提供相关内容,以便我能够为您生成100-300字的摘要。forms的使用与优化** 用户解答 作为一名经常使用各种网站和应用程序的用户,我深知forms(表单)在用户体验中的重要性,一个设计合理、易于操作的表单,能够极大地提升用户的满意度,在实际使用中,我...

源代码网页,揭秘源代码,网页背后的编程奥秘
您提供的“源代码网页”这一内容较为宽泛,无法直接生成摘要,请提供更具体的信息或内容,以便我为您生成合适的摘要,您可以提供网页的主题、关键信息或具体内容等。如何窥视网页背后的秘密 用户解答: 嗨,大家好!最近我在学习网页开发,对源代码网页特别感兴趣,我发现通过查看网页的源代码,可以了解网站的很多信...
数据库系统工程师真题,数据库系统工程师历年真题解析
数据库系统工程师真题主要涉及数据库的基本概念、设计、实施与维护等方面的知识,考生需掌握数据库模型、关系代数、SQL语言、数据库设计规范、事务管理、索引与视图等内容,真题形式包括选择题、填空题、简答题和综合应用题,旨在考察考生对数据库理论知识的掌握程度以及实际应用能力。数据库系统工程师真题解析与备考攻...
- 最新发布
-
29秒前
8分钟前
11分钟前

19分钟前

25分钟前
- 热门阅读
-

916 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言