delete语句可以写group by吗,删除操作中能否使用GROUP BY子句?
不可以,在SQL中,DELETE语句不支持直接使用GROUP BY子句,GROUP BY通常用于SELECT语句中,用于对查询结果进行分组和聚合,而DELETE语句用于删除数据库中的记录,它通常与WHERE子句结合使用来指定要删除的记录,如果你需要根据分组条件删除数据,你可能需要使用子查询或者临时表来实现这一功能。
delete语句可以写group by吗?
真实用户解答: 嗨,我最近在使用SQL进行数据库操作时,遇到了一个问题,我在思考,能否在delete语句中使用group by呢?我知道group by通常用于select语句中对数据进行分组统计,但我在删除数据时也想进行一些分组操作,所以想请教一下,delete语句中是否可以使用group by?
下面,我将从几个出发,深入探讨这个问题。

一:delete语句与group by的基本概念
- delete语句的作用:delete语句用于从数据库表中删除记录。
- group by的作用:group by用于对select语句中的结果集进行分组,常与聚合函数(如count、sum、avg等)一起使用。
- delete语句中不直接支持group by:在标准的SQL语法中,delete语句不支持直接使用group by。
二:为何delete语句不支持group by
- 删除操作的单行特性:delete语句通常是针对单条记录进行的删除操作,而group by需要多行数据来进行分组统计。
- 事务的一致性:使用group by可能会涉及到复杂的逻辑,这可能会破坏删除操作的事务一致性。
- 性能考虑:在delete语句中使用group by可能会降低查询性能。
三:替代方案
- 先select后delete:可以先使用select语句结合group by进行数据筛选,然后根据筛选结果进行delete操作。
- 示例:
SELECT id FROM table GROUP BY condition HAVING count(*) > 1;然后根据select的结果进行delete操作。
- 示例:
- 临时表或视图:可以将需要删除的数据先存储到临时表或视图中,然后对这些临时数据执行delete操作。
- 示例:
CREATE TEMPORARY TABLE temp_table AS SELECT * FROM table GROUP BY condition;然后删除temp_table中的数据。
- 示例:
- 存储过程:可以将删除逻辑封装在存储过程中,使用group by进行数据筛选。
四:实际应用中的注意事项
- 数据一致性:在使用替代方案时,要注意保证数据的一致性,避免误删数据。
- 性能优化:在执行删除操作时,要注意性能优化,避免长时间锁定表。
- 权限控制:确保有足够的权限来执行delete操作和相关数据库操作。
五:总结
虽然delete语句本身不支持直接使用group by,但我们可以通过一些替代方案来实现类似的功能,在实际应用中,要根据具体需求和数据库的特点选择合适的方法,确保数据的安全性和操作的效率,希望这篇文章能帮助你更好地理解这个问题。
其他相关扩展阅读资料参考文献:
语法层面的限制
-
标准SQL不支持直接使用GROUP BY
在SQL标准中,DELETE语句本身不允许直接包含GROUP BY子句,GROUP BY主要用于SELECT语句中对数据进行分组聚合,而DELETE的目的是删除行,二者功能本质不同,若强行在DELETE中使用GROUP BY,数据库会报错,DELETE FROM table GROUP BY column会导致语法错误。 -
GROUP BY需配合子查询使用
虽然DELETE不能直接使用GROUP BY,但可以通过子查询实现间接分组删除。DELETE FROM table WHERE column IN (SELECT MAX(column) FROM table GROUP BY another_column),这种写法利用子查询筛选出需要删除的行,但需注意子查询必须返回单一值(如MAX、MIN等聚合函数)。
-
GROUP BY无法用于删除重复数据
删除重复数据时,GROUP BY无法直接替代DISTINCT或唯一索引,若要删除某个字段重复的记录,需先通过子查询定位重复项,再结合ROW_NUMBER()等窗口函数实现删除,如:DELETE FROM table WHERE id NOT IN (SELECT MIN(id) FROM table GROUP BY column)。
实际应用场景的可行性
-
删除冗余数据的必要性
在数据清洗中,GROUP BY常用于识别冗余记录,删除某个分类下重复的订单数据,需先通过GROUP BY定位重复项,再用子查询筛选保留唯一记录,但此过程需确保逻辑正确,避免误删关键数据。 -
结合条件分组删除的场景
当需要根据特定条件删除分组中的部分数据时,GROUP BY可辅助实现,删除某个用户组中年龄大于30的记录,需先通过GROUP BY分组,再用HAVING筛选符合条件的组,最终通过子查询执行删除操作。 -
性能与风险的权衡
使用GROUP BY结合DELETE可能引发性能问题,尤其是对大数据表。需谨慎评估查询复杂度,避免因分组操作导致全表扫描或锁表。删除操作前必须验证数据,防止误删导致数据丢失。
数据库系统的差异与注意事项
-
MySQL允许GROUP BY在DELETE子查询中使用
在MySQL中,DELETE语句可以通过子查询嵌套GROUP BY,但仅限于子查询返回单一值的情况。DELETE FROM orders WHERE order_id IN (SELECT order_id FROM orders GROUP BY customer_id HAVING COUNT(*) > 1),此功能需注意版本兼容性,高版本MySQL支持更复杂的子查询。 -
PostgreSQL不支持GROUP BY在DELETE中直接使用
PostgreSQL严格遵循SQL标准,不允许在DELETE语句中直接使用GROUP BY,若需实现类似功能,需通过CTE(公共表表达式)或临时表分步操作,WITH cte AS (SELECT MAX(id) FROM table GROUP BY column) DELETE FROM table WHERE id NOT IN (SELECT id FROM cte);
此方法更符合标准,但实现步骤更繁琐。
-
SQL Server支持GROUP BY在DELETE子查询中
SQL Server允许在DELETE语句的子查询中使用GROUP BY,但需确保子查询结果与主表字段类型匹配。DELETE FROM table WHERE column IN (SELECT column FROM table GROUP BY column HAVING COUNT(*) > 1);
此写法在SQL Server中有效,但需注意子查询可能返回多个值,需配合IN或EXISTS等条件。
替代方案与最佳实践
-
使用ROW_NUMBER()实现精准删除
对于需要删除分组中重复数据的场景,ROW_NUMBER()是更安全的替代方案。DELETE FROM table WHERE id IN ( SELECT id FROM ( SELECT id, ROW_NUMBER() OVER (PARTITION BY column ORDER BY created_at) AS rn FROM table ) t WHERE rn > 1 );该方法能明确删除重复项中的非最新记录,避免误删。
-
优先使用唯一索引或约束
建立唯一索引是预防重复数据的首选方案,为用户表的邮箱字段添加唯一索引后,插入重复数据会自动报错,无需依赖DELETE和GROUP BY。 -
分批次删除以降低风险
大规模删除操作建议分批次执行,避免因一次性删除导致数据库锁表或事务回滚。DELETE FROM table WHERE id IN ( SELECT id FROM ( SELECT id FROM table ORDER BY created_at LIMIT 1000 ) t );通过限制删除数量,可减少对系统资源的占用。
常见误区与解决方案
-
误以为GROUP BY能直接删除数据
部分开发者可能误以为GROUP BY可以直接用于DELETE,但实际需通过子查询或窗口函数间接实现。需明确DELETE与GROUP BY的功能边界。 -
忽略分组逻辑的正确性
若分组条件设计错误,可能导致删除范围扩大或遗漏关键数据。需在执行前通过SELECT验证分组结果。 -
过度依赖GROUP BY导致性能下降
频繁使用GROUP BY结合DELETE可能引发索引失效,建议优化查询语句或增加索引,为分组字段添加索引可显著提升查询效率。
DELETE语句无法直接使用GROUP BY,但可通过子查询、窗口函数等间接实现,实际应用中需根据数据库系统特性选择合适方法,并注重性能优化与数据验证。正确理解语法规则与业务逻辑是避免误操作的关键。
“delete语句可以写group by吗,删除操作中能否使用GROUP BY子句?” 的相关文章

require,探索require的奥秘,深入理解JavaScript模块化编程
探索JavaScript模块化编程的核心——require机制,本文深入剖析require的原理和用法,帮助读者全面理解模块化编程的精髓,掌握如何高效利用require进行模块管理,提升JavaScript项目的可维护性和扩展性。解析“require” 我在使用某个编程语言的时候,遇到了一个叫做“...
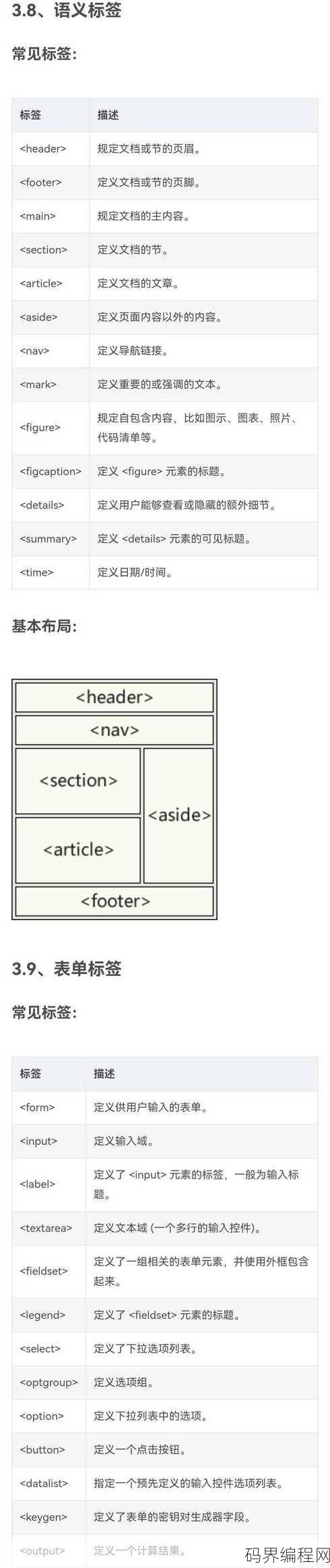
html中textarea的用法,HTML textarea标签,实现文本区域输入的实用指南
HTML中的`标签用于创建多行的文本输入控件,用户可以在其中输入和编辑文本,基本用法如下:在标签内写入内容,并使用rows和cols属性来设置文本区域的高度和宽度,还可以通过readonly属性使其变为只读,或使用disabled属性禁用输入,name`属性用于在表单提交时将数据发送到服务器。HTM...
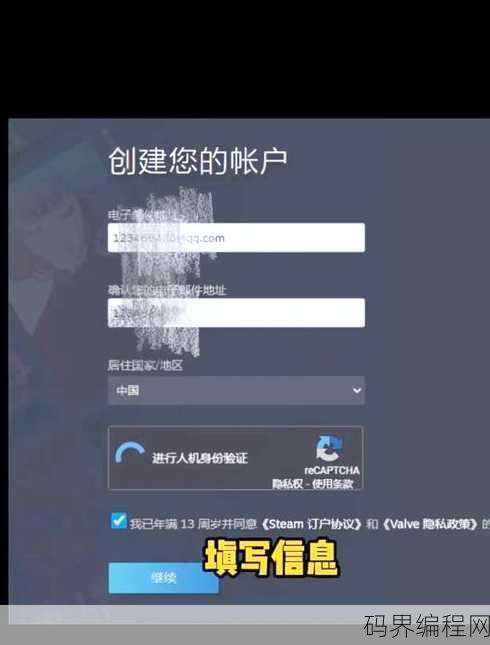
beanfun账号怎么注册啊,Beanfun账号注册指南
beanfun账号注册步骤如下:访问beanfun官方网站或下载beanfun客户端;点击注册按钮,选择注册方式(如手机号、邮箱等);输入相关信息,如用户名、密码、手机号或邮箱;完成验证码验证;阅读并同意服务条款;点击注册完成,注册成功后,即可使用beanfun账号享受相关服务。beanfun账号怎...
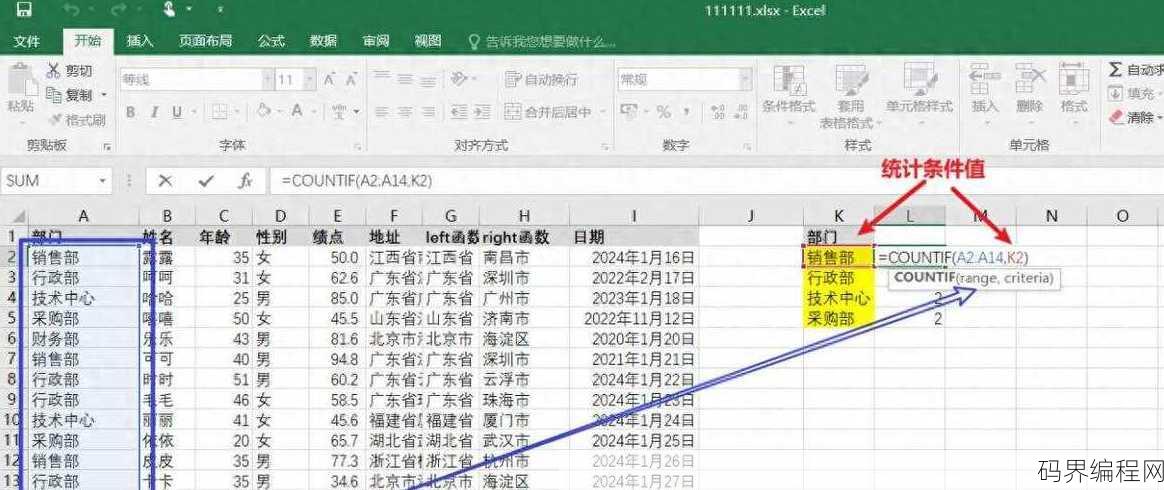
count和countif的操作,Excel中Count与Countif函数应用技巧对比
count和countif是Excel中的两个函数,用于统计数据集中的数值或符合特定条件的单元格数量,count函数简单统计包含数字的单元格数量,而countif函数则允许你指定一个条件,只统计满足该条件的单元格数量,count(A1:A10)会计算A1到A10区域中所有包含数字的单元格数量,而co...

address函数怎么使用,深入解析,address函数的实用指南
address函数通常用于编程语言中,用于获取变量的内存地址,以下是使用address函数的基本步骤和摘要:,address函数用于获取变量的内存地址,在C++中,可以使用&操作符直接获取变量的地址,或者使用std::addressof函数,int var = 10;,则address(var)或s...

网页设计与制作教案,网页设计与制作教学大纲
本教案旨在教授网页设计与制作的基本知识和技能,课程内容包括网页设计原则、HTML/CSS基础、页面布局、交互设计以及常用网页设计工具的使用,学生将通过实践项目学习如何创建结构清晰、美观实用的网页,并掌握代码编辑、图片处理等关键技术,课程旨在培养学生的网页设计思维和动手能力,为将来从事相关领域工作打下...
- 最新发布
-

6分钟前

13分钟前
20分钟前
26分钟前

34分钟前
- 热门阅读
-

912 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言