爬取一个网站的多个页面数据,多页面数据爬取攻略,高效抓取网站信息
爬取网站数据涉及使用编程工具或脚本从目标网站抓取多个页面的内容,这一过程通常包括以下步骤:分析网站结构以确定URL模式和页面内容布局;编写或使用现成的爬虫工具,如BeautifulSoup或Scrapy,来发送HTTP请求获取页面HTML;解析HTML以提取所需的数据,如文本、图片链接等;将提取的数据存储到数据库或文件中,整个过程需注意遵守网站的robots.txt规则,避免对网站服务器造成过大压力。
爬取一个网站的多个页面数据
用户解答: 嗨,大家好!最近我在做一个小项目,需要从某个网站上爬取大量的数据,我听说爬虫是个不错的选择,但是我对如何爬取多个页面的数据还是有点懵,能帮我普及一下这方面的知识吗?
一:了解爬虫的基本概念
-
什么是爬虫? 爬虫(Web Crawler)是一种自动化程序,用于在互联网上抓取信息,它通过模拟浏览器行为,访问网页,提取所需数据。
-
为什么需要爬虫? 爬虫可以帮助我们快速获取大量数据,进行数据分析、信息整理等。
-
爬虫的分类:
- 通用爬虫:广泛抓取网页,如百度、谷歌等搜索引擎。
- 聚焦爬虫:针对特定领域或网站进行抓取。
二:选择合适的爬虫工具
-
Python爬虫库推荐:
- requests:用于发送HTTP请求。
- BeautifulSoup:用于解析HTML和XML文档。
- Scrapy:一个强大的爬虫框架。
-
其他语言爬虫工具:
- Java:使用Jsoup库。
- PHP:使用phpQuery库。
-
选择工具的原则:
- 易用性:工具简单易学,易于上手。
- 功能:满足项目需求,如支持多线程、分布式爬取等。
三:分析目标网站结构
-
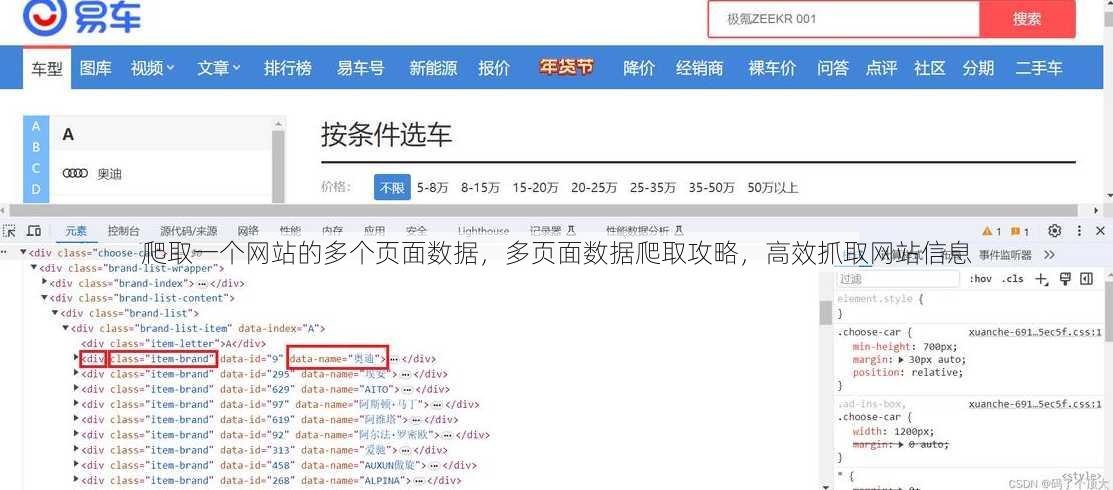
查看网页源码: 使用开发者工具查看网页源码,了解网页结构。
-
分析URL规律: 观察目标网站的URL,找出规律,方便编写爬虫逻辑。
-
确定数据提取规则: 根据网页结构,确定提取数据的标签、属性等。
四:编写爬虫代码
-
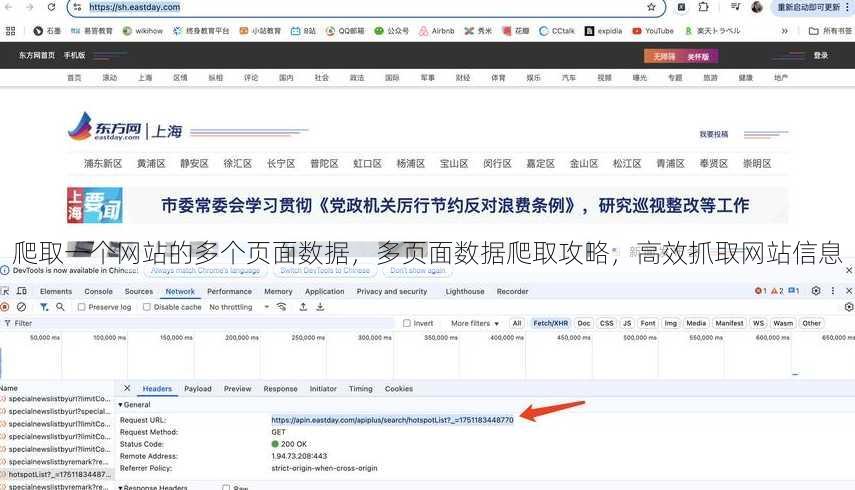
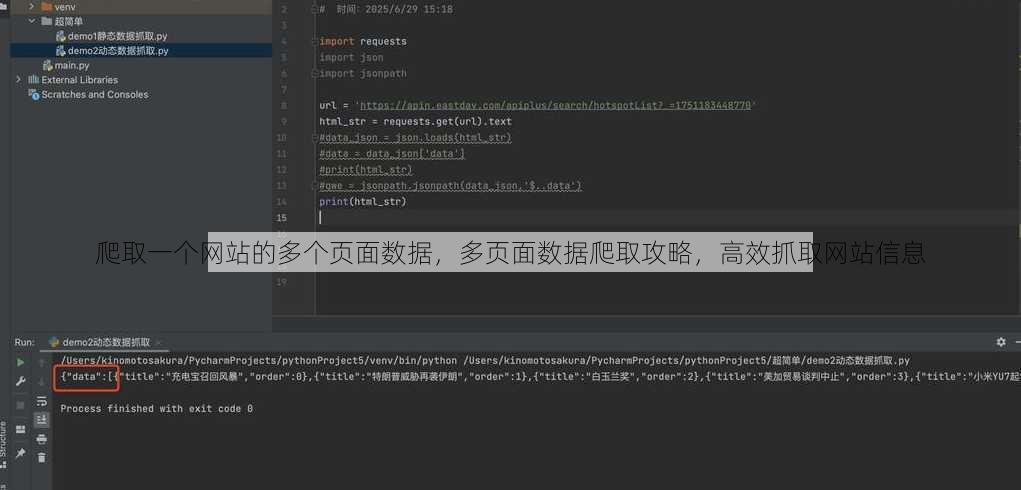
发起请求: 使用requests库发送HTTP请求,获取网页内容。
-
解析网页: 使用BeautifulSoup或Scrapy解析网页内容,提取所需数据。
-
存储数据: 将提取的数据存储到数据库、文件或其他存储介质。
-
处理异常: 编写异常处理逻辑,确保爬虫稳定运行。
五:遵守法律法规和道德规范
-
遵守robots.txt: 查看目标网站的robots.txt文件,了解允许爬取的页面。
-
限制爬取频率: 避免对目标网站造成过大压力,合理设置爬取频率。
-
尊重版权: 确保爬取的数据不侵犯他人版权。
-
道德规范: 不进行恶意爬取,不泄露他人隐私。
爬取一个网站的多个页面数据需要了解爬虫的基本概念、选择合适的工具、分析网站结构、编写代码以及遵守法律法规和道德规范,希望这篇文章能帮助你更好地理解爬虫技术,祝你项目顺利!
其他相关扩展阅读资料参考文献:
爬取一个网站的多个页面数据——入门与实践
随着互联网的发展,数据爬取已成为获取网站信息的重要手段,本文将介绍如何爬取一个网站的多个页面数据,从以下五个展开深入探讨。
一:了解网站结构与数据爬取
- 网站结构分析:在进行数据爬取前,需了解网站的结构,包括页面布局、URL规律等,这是制定爬取策略的基础。 2.爬虫基础知识:了解爬虫的基本原理,包括网页请求、数据解析等,有助于更有效地进行网站数据爬取。
- 数据爬取的必要性:在大数据时代,通过数据爬取可以快速获取大量结构化数据,为分析和决策提供支持。
二:选择合适的爬取工具与技术
- 爬虫框架选择:根据需求和经验,选择合适的爬虫框架,如Scrapy、PySpider等。 2.数据解析技术:掌握HTML、XPath、正则表达式等数据解析技术,以便准确提取所需信息。
- 应对反爬虫策略:了解网站可能采取的反爬虫策略,如验证码、请求限制等,并学会如何应对。
三:制定爬取策略与实现过程
- 制定爬取目标:明确爬取的数据类型、数量及质量要求,制定合理的爬取策略。 2.数据爬取的步骤:包括发送请求、获取页面、解析数据、存储数据等步骤,需要详细规划。
- 应对动态加载内容:对于含有动态加载内容的页面,需使用相应技术抓取异步请求的数据。
四:数据存储与处理
- 数据存储方式选择:根据需求选择合适的数据存储方式,如数据库、文件存储等。 2.数据处理技术:掌握数据处理技术,如数据清洗、去重、转换等,以提高数据质量。
- 数据安全保护:在数据存储和处理过程中,需注意保护用户隐私和信息安全,遵守相关法律法规。
五:实践案例分享与经验总结
- 实战案例分享:分享成功的网站数据爬取案例,展示具体实现过程与技巧。 2.经验总结:总结在网站数据爬取过程中的经验教训,提高爬取效率和成功率。
- 展望未来趋势:分析数据爬取技术的未来发展趋势,探讨新技术在网站数据爬取中的应用前景。
通过以上五个的介绍,相信读者对如何爬取一个网站的多个页面数据有了更深入的了解,在实际操作中,还需不断学习和积累经验,以应对各种挑战。
“爬取一个网站的多个页面数据,多页面数据爬取攻略,高效抓取网站信息” 的相关文章

sql增加字段语句,SQL语句添加新字段教程
在SQL中,增加字段的语句通常使用ALTER TABLE语句配合ADD COLUMN子句来完成,以下是一个基本的增加字段的SQL语句示例:,``sql,ALTER TABLE table_name,ADD COLUMN column_name column_type [CONSTRAINTS];,`...
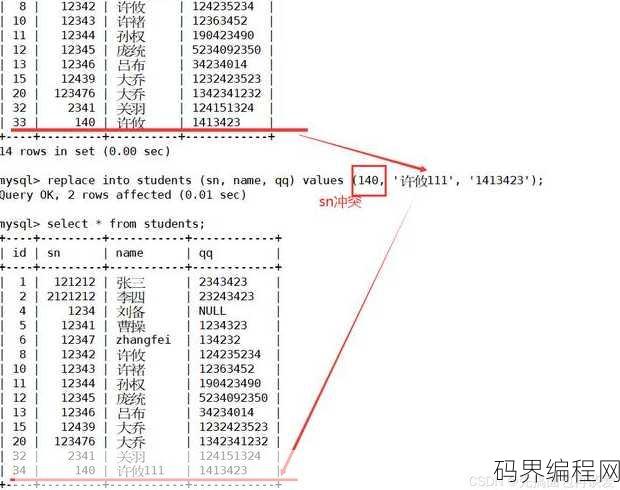
insert一个表到另一个表,将一个表插入到另一个表中
在数据库操作中,使用INSERT语句将一个表的数据插入到另一个表中,通常涉及以下步骤:选择目标表,然后使用INSERT INTO语句指定插入数据的字段和来源,若要将表A的数据插入到表B中,可以使用以下SQL语句:INSERT INTO B (列1, 列2, ...) SELECT 列1, 列2, ....
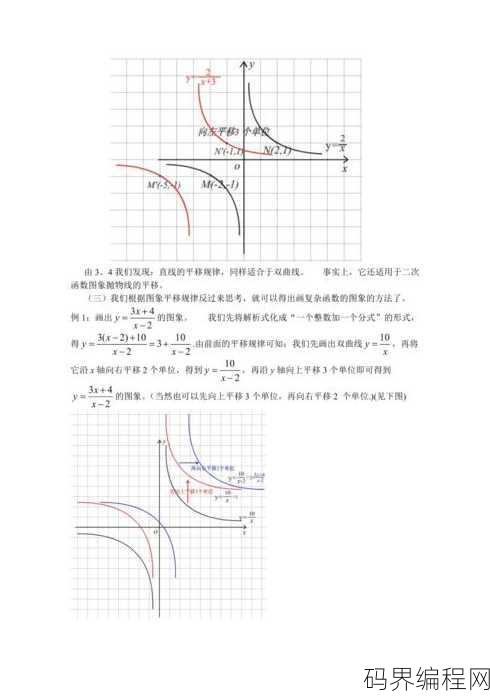
反比例函数图像平移,反比例函数图像的平移变换解析
反比例函数图像平移是指在坐标系中,将反比例函数的图像沿x轴或y轴方向移动一定的距离,这种平移不会改变函数的形状,但会改变图像的位置,当沿x轴平移时,函数的常数项发生变化;沿y轴平移时,函数的系数发生变化,将y=k/x的图像沿x轴向右平移a个单位,得到y=k/(x-a)的图像。 嗨,我最近在学习反比...
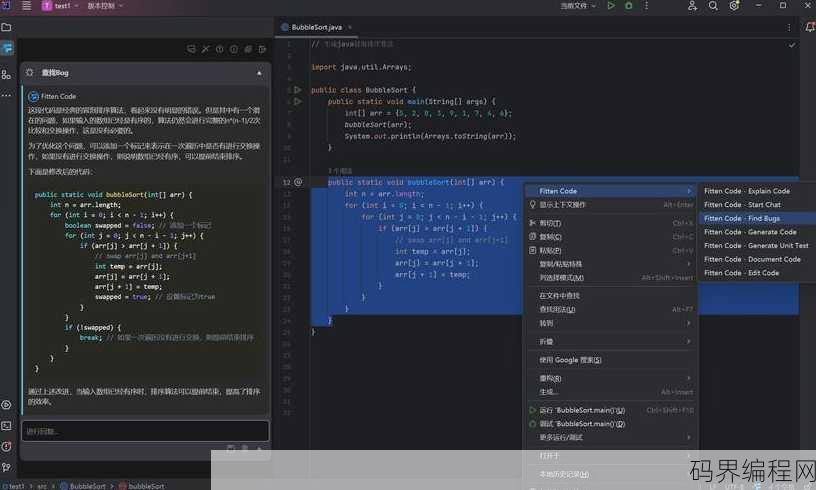
ai写程序python,Python编程,AI助力高效程序编写实践
AI编写程序主要涉及使用Python语言进行软件开发,Python以其简洁明了的语法和丰富的库支持,成为AI和机器学习领域的主流编程语言,AI编写程序的过程包括数据预处理、模型选择、训练和优化等步骤,通过Python,AI可以处理和分析大量数据,实现智能决策和预测,广泛应用于自然语言处理、图像识别、...

css背景渐变,探索CSS背景渐变技巧与应用
CSS背景渐变是一种通过CSS3属性实现的视觉效果,允许网页元素背景颜色从一种颜色平滑过渡到另一种颜色,渐变可以水平、垂直、对角线或径向进行,通过定义起点、终点和中间色来实现丰富的视觉效果,支持渐变的CSS属性包括linear-gradient和radial-gradient,这些属性使得设计师能够...

html是干嘛的,HTML,构建网页结构的基础技术揭秘
HTML,即超文本标记语言,是一种用于创建网页的标准标记语言,它通过一系列标签(如`、、`等)来定义网页的结构和内容,HTML使得网页能够在浏览器中正确显示文本、图片、链接等多种元素,是网页制作的基础,通过HTML,开发者可以构建出结构清晰、内容丰富的网页,为用户提供便捷的网络浏览体验。HTML是干...
- 最新发布
-

1分钟前
9分钟前
12分钟前
20分钟前

26分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言