新手python爬虫代码,Python爬虫入门,新手代码实战指南
介绍了如何编写一个Python爬虫的基础代码,摘要如下:,“本文将指导新手如何使用Python编写简单的爬虫程序,通过实例代码,展示了如何使用Python内置库进行网页请求、解析HTML内容和提取所需数据,代码示例包括设置请求头、发送GET请求、解析响应内容以及提取特定信息等步骤,适合初学者学习和实践。”
新手Python爬虫代码入门指南**
用户解答
“嗨,我最近想学习Python爬虫,但是不知道从哪里开始,我听说Python爬虫很强大,但是代码看起来有点复杂,有没有什么好的入门教程或者简单的代码示例呢?”
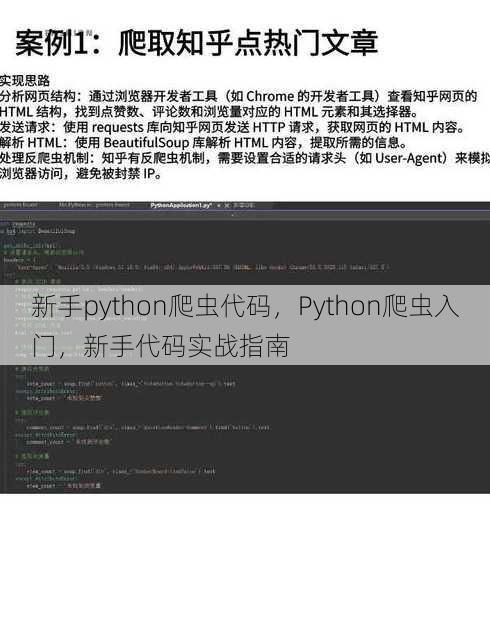
一:环境搭建
- 安装Python:你需要确保你的电脑上安装了Python,你可以从Python的官方网站下载并安装最新版本的Python。
- 安装第三方库:Python爬虫通常会用到一些第三方库,如
requests用于发送HTTP请求,BeautifulSoup用于解析HTML文档,你可以使用pip来安装这些库。 - 选择合适的IDE:为了更好地编写和调试代码,你可以选择一个合适的集成开发环境(IDE),如PyCharm或VS Code。
二:基础语法
- 变量和数据类型:在Python中,你需要了解变量和不同的数据类型,如字符串、整数、浮点数等。
- 条件语句和循环:了解如何使用
if语句和循环(如for和while)来控制程序的流程。 - 函数:学习如何定义和调用函数,这有助于组织代码并提高代码的可重用性。
三:发送HTTP请求
- 使用requests库:使用
requests.get()或requests.post()方法来发送HTTP请求。 - 处理响应:检查HTTP响应的状态码,如200表示请求成功,404表示页面未找到。
- 解析响应内容:你可以使用
response.text获取响应的HTML内容,或者使用response.json()获取JSON格式的数据。
四:解析HTML文档
- 使用BeautifulSoup:安装BeautifulSoup库后,你可以使用它来解析HTML文档。
- 查找元素:使用BeautifulSoup提供的各种方法来查找HTML元素,如
find()、find_all()等。 - 提取信息:从找到的元素中提取所需的信息,如文本内容、属性等。
五:保存数据
- 写入文件:你可以将提取的数据保存到文件中,如CSV或JSON格式。
- 数据库存储:如果你需要更复杂的存储方案,可以考虑使用数据库,如SQLite或MySQL。
- API接口:将数据通过API接口发送到其他系统或服务。
通过以上这些步骤,你可以逐步建立起自己的Python爬虫项目,爬虫编写过程中要遵守网站的使用条款和法律法规,不要过度抓取导致服务器压力过大,多实践、多调试是提高爬虫编写技能的关键,祝你学习愉快!
其他相关扩展阅读资料参考文献:
基础环境搭建
- 安装Python:选择Python 3.8或以上版本,下载后添加环境变量,确保命令行输入
python --version能正常显示版本号。 - 安装requests库:通过
pip install requests安装,它是发送HTTP请求的核心工具,可直接获取网页HTML内容。 - 安装BeautifulSoup:使用
pip install beautifulsoup4安装,配合requests用于解析网页结构,提取所需数据。
请求与响应处理
- 发送GET请求:用
requests.get(url, headers=headers)获取网页内容,headers参数需包含User-Agent模拟浏览器访问。 - 处理响应状态码:检查
response.status_code,若为200表示请求成功,403或500需排查是否被封禁或网络问题。 - 设置请求头:通过
headers={'User-Agent': 'Mozilla/5.0'}浏览器,避免被服务器直接拦截。
数据解析技巧
- 解析HTML结构:使用
BeautifulSoup(html_content, 'html.parser')加载网页,通过soup.find_all('tag')定位标签。 - 提取特定数据:例如提取所有链接,使用
soup.find_all('a')并遍历获取href属性,for link in soup.find_all('a'): print(link.get('href'))。 - 处理动态内容:对于JavaScript渲染的页面,需用
Selenium或Playwright驱动浏览器,用户操作。
反爬策略应对
- 设置User-Agent:随机生成User-Agent字符串,如
headers={'User-Agent': 'Random-User-Agent-String'},避免被识别为爬虫。 - 控制请求频率:在代码中添加
time.sleep(2)延迟,防止因高频请求触发服务器风控机制。 - 使用代理IP:通过
proxies={'http': 'http://ip:port', 'https': 'https://ip:port'}参数设置代理,绕过IP封锁。
实战案例解析
- 爬取网页标题:用
soup.title.string直接获取页面标题,适用于简单数据提取场景。 - 保存数据到文件:将提取的数据写入CSV或JSON文件,例如
with open('data.csv', 'w') as f: csv.writer(f).writerow(data)。 - 处理异常情况:用
try-except捕获网络错误或解析异常,如try: response.raise_for_status() except: print("请求失败")。
进阶技巧与注意事项
- 使用Session对象:通过
session = requests.Session()维持会话,避免重复登录或Cookie失效问题。 - 处理验证码:对于需验证码的网站,可借助第三方服务(如云打码)或手动识别,但需注意合法性。
- 遵守robots.txt规则:检查目标网站的
robots.txt文件,确保爬取范围符合规定,避免法律风险。 - 数据清洗与格式化:去除多余空格、标点符号,统一数据格式(如日期、数字),提升数据可用性。
- 优化代码结构:将爬虫逻辑拆分为函数模块(如
fetch_data()、parse_data()),便于维护与扩展。
总结与学习路径
Python爬虫的核心在于理解请求-响应-解析流程,新手需从基础环境搭建开始,逐步掌握请求发送、数据提取和反爬策略。
- 学习路径建议:先熟悉HTTP协议,再学习requests和BeautifulSoup的使用,最后研究Selenium或Scrapy框架。
- 实践优先:通过小项目(如爬取新闻标题、商品价格)积累经验,逐步挑战复杂任务(如模拟登录、数据存储)。
- 注意合法合规:仅爬取公开数据,避免侵犯网站版权或隐私,遵守《计算机信息网络国际联网安全保护管理办法》。
代码示例参考:
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.find_all('h2')) # 提取所有h2标签
关键点提醒:
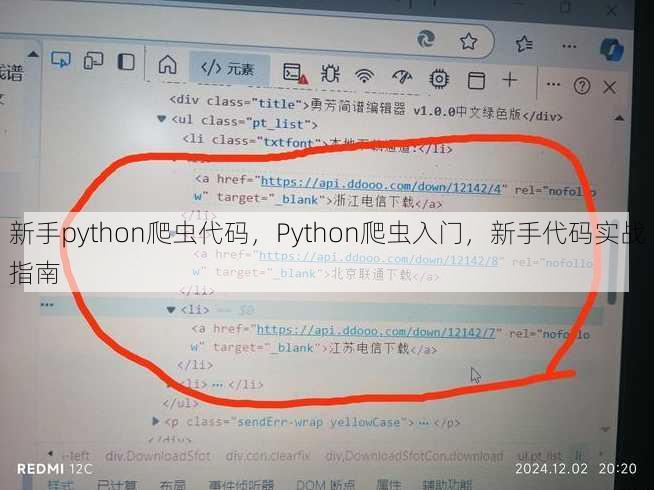
- 爬虫效率与稳定性:合理设置超时时间(
timeout=5)和重试机制,避免程序卡死。 - 数据存储格式:选择CSV、JSON或数据库存储,根据需求决定结构化程度。
- 调试工具使用:通过
print(response.text)查看原始数据,使用开发者工具分析网页结构。
新手常见误区:
- 盲目高频请求导致IP被封,需控制频率并使用代理。
- 忽略响应编码问题,使用
response.encoding='utf-8'确保数据正确解析。 - 未处理动态内容,导致数据缺失,需结合Selenium等工具。
最终建议:
爬虫技术需结合伦理与法律,新手应在合法范围内学习,优先选择公开数据源,并关注目标网站的反爬策略,通过不断实践和优化,逐步提升代码效率与稳定性,为后续复杂任务打下坚实基础。

“新手python爬虫代码,Python爬虫入门,新手代码实战指南” 的相关文章

beanpole包包,Beanpole时尚长款手提包推荐
beanpole包包,一款时尚潮流的单肩包,采用优质面料制作,设计简约大方,其独特的造型和实用性,深受年轻消费者的喜爱,beanpole包包不仅适合日常出行,也适合各种场合佩戴,为你的生活增添一份时尚魅力。 自从入手了这款beanpole包包,我的生活真的发生了翻天覆地的变化,这款包包的设计简约而...
java编译器网页版,在线Java编译器平台
Java编译器网页版是一款在线Java代码编译和运行工具,用户无需安装任何软件即可在网页上编写、编译和运行Java代码,它支持多种Java版本,并提供实时错误提示和调试功能,方便开发者进行代码测试和调试,用户可以在线分享代码,提高开发效率。Java编译器网页版——轻松在线编译Java代码 用户解答...
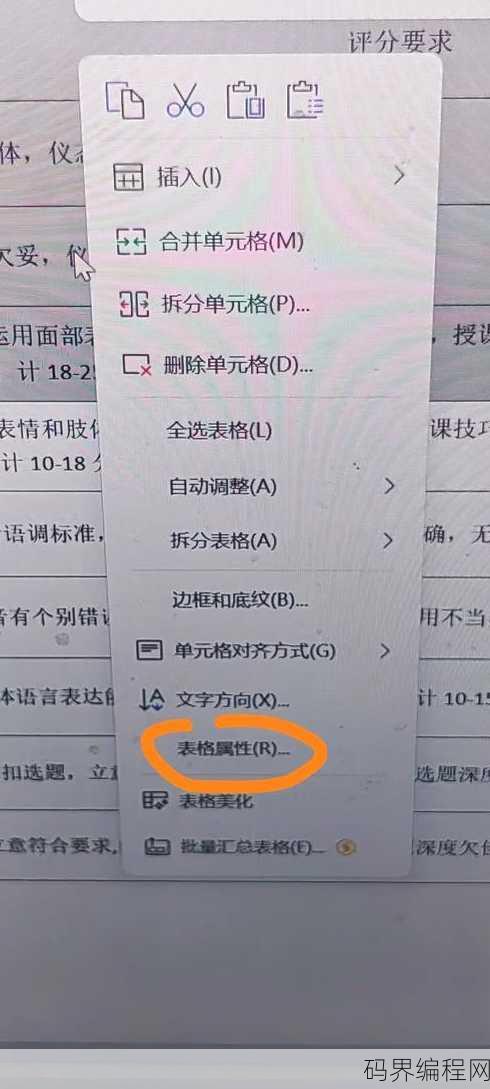
word表格怎么消除文本框边框,Word表格文本框去边框小技巧
在Word中消除文本框边框,首先选中要修改的文本框,点击“格式”选项卡,找到“形状轮廓”按钮,在弹出的菜单中选择“无轮廓”,这样就可以轻松去除文本框的边框了。Word表格怎么消除文本框边框——轻松掌握技巧 大家好,我是一名经常使用Word进行文档编辑的职场人士,我想和大家分享一个关于Word表格的...

学python哪个机构好些,Python学习哪家机构更优秀?
选择学习Python的机构,推荐关注以下几点:师资力量、课程设置、实践机会、学员评价,以下是一些口碑较好的Python培训机构:1. 猿辅导:拥有丰富的教学经验和优秀的师资团队,课程内容全面,2. 老男孩教育:注重实践,课程紧跟行业需求,3. 前端社:专注于前端技术,Python课程质量高,4. 猿...

源代码审计,源代码安全审查,深入源代码审计的艺术与实践
源代码审计是一项系统性的安全检查过程,旨在识别和修复软件源代码中的潜在安全漏洞,通过深入代码逻辑,审计师可以评估软件的健壮性和安全性,预防恶意攻击,审计内容涵盖代码质量、逻辑漏洞、数据保护等方面,确保软件在开发过程中遵循安全最佳实践。了解源代码审计 作为一名软件开发者,你是否曾想过,自己的代码是否...

单片机c语言入门自学视频,单片机C语言自学教程视频系列
本视频教程为单片机C语言入门学习,适合初学者,内容涵盖单片机基础知识、C语言基础语法、编程环境搭建、简单程序编写等,通过实际操作引导学习,帮助用户快速掌握单片机编程技能,视频循序渐进,适合自学,适合电子爱好者及嵌入式系统开发者学习使用。用户提问:我想自学单片机C语言,有没有推荐的入门视频教程? 解...
- 最新发布
-
3分钟前

11分钟前

18分钟前
25分钟前
28分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言