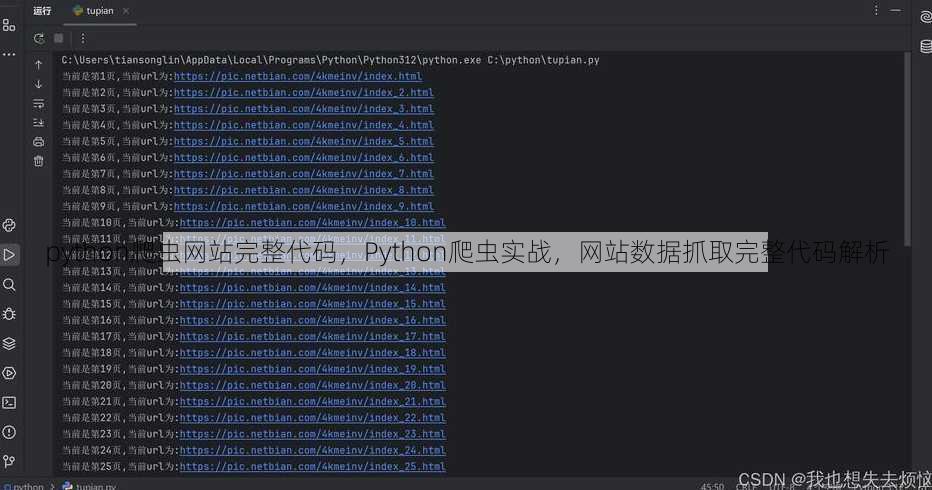
python爬虫网站完整代码,Python爬虫实战,网站数据抓取完整代码解析
由于您没有提供具体的Python爬虫网站完整代码内容,我无法为您生成摘要,请提供相关代码内容,我将为您制作摘要。
爬虫基本原理
- 定义:爬虫是一种自动化程序,用于从网站上抓取数据。
- 工作流程:
- 发送请求:使用
requests库向目标网站发送HTTP请求。 - 解析响应:使用
BeautifulSoup库解析返回的HTML内容。 - 提取数据:从解析后的HTML中提取所需数据。
- 存储数据:将提取的数据存储到文件或数据库中。
- 发送请求:使用
二:Python爬虫代码示例
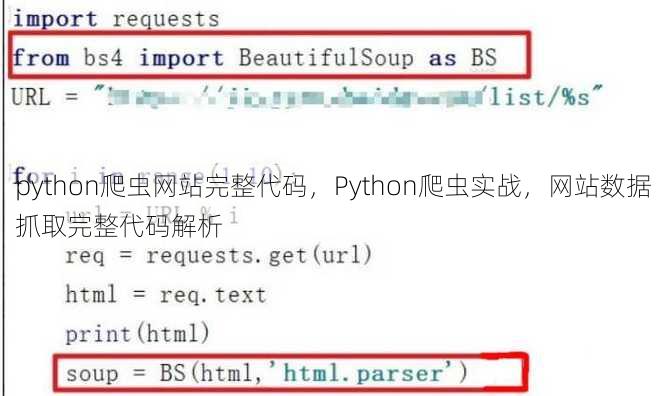
import requests
from bs4 import BeautifulSoup
# 发送请求
url = 'https://www.example.com'
response = requests.get(url)
# 解析响应
soup = BeautifulSoup(response.text, 'html.parser')
# 提取数据= soup.find('title').text
print('Title:', title)
# 存储数据
with open('data.txt', 'w') as file:
file.write(title)
三:常见爬虫库介绍
- requests:用于发送HTTP请求,是爬虫的基础库。
- BeautifulSoup:用于解析HTML和XML文档,提取数据。
- Scrapy:一个强大的爬虫框架,适用于大规模数据抓取。
- Selenium:用于模拟浏览器行为,适用于需要登录或JavaScript渲染的网站。
四:注意事项
- 遵守网站政策:在抓取数据前,确保目标网站允许爬虫访问。
- 设置请求头:模拟浏览器访问,避免被服务器识别为爬虫。
- 合理设置请求频率:避免对目标网站造成过大压力。
- 处理异常:在爬虫代码中添加异常处理,提高程序的稳定性。
五:进阶技巧
- 分布式爬虫:使用Scrapy-Redis等工具实现分布式爬虫,提高效率。
- 多线程爬虫:使用
threading或concurrent.futures模块实现多线程爬虫,加快数据抓取速度。 - 数据清洗:对抓取到的数据进行清洗,去除无用信息。
- 数据可视化:使用Matplotlib、Seaborn等库将数据可视化,更直观地展示数据。
通过以上几个方面的讲解,相信大家对Python爬虫有了更深入的了解,希望这个简单的爬虫示例能帮助到有需要的开发者。
其他相关扩展阅读资料参考文献:
基础环境搭建
-
安装核心库
首先需安装requests和BeautifulSoup,这是爬虫的基石,使用pip install requests beautifulsoup4即可完成。requests负责发送HTTP请求,BeautifulSoup用于解析HTML内容,二者结合能快速获取网页数据。 -
设置请求头
爬虫需模拟浏览器行为,否则容易被网站识别为异常流量,在代码中添加headers参数,headers = {'User-Agent': 'Mozilla/5.0'} response = requests.get(url, headers=headers)User-Agent是关键,需根据目标网站的反爬策略调整。
-
处理动态内容
若目标网站使用JavaScript渲染页面,需借助Selenium或Playwright,以Selenium为例,代码需初始化浏览器实例并加载页面:from selenium import webdriver driver = webdriver.Chrome() driver.get(url)
处理会显著增加代码复杂度,但能解决静态解析无法获取数据的问题。
核心代码结构
-
请求发送与响应处理
使用requests.get()发送请求后,需检查响应状态码,若状态码为200,说明请求成功;否则需排查网络问题或目标网站限制。可通过response.text或response.content获取,注意编码问题。 -
数据解析与提取
BeautifulSoup的find_all()和select()方法是提取数据的核心。soup = BeautifulSoup(response.text, 'html.parser') s = soup.select('h1.title')XPath则适合复杂结构,需配合
lxml使用:from lxml import etree html = etree.HTML(response.text) data = html.xpath('//div[@class="content"]/text()') -
异常处理与日志记录
爬虫需应对网络波动和服务器限制,添加try-except块捕获异常:try: response = requests.get(url, timeout=10) except requests.exceptions.RequestException as e: print(f"请求失败: {e}")日志记录能帮助排查问题,建议使用
logging模块记录关键信息。
反爬策略处理
-
设置请求头参数
目标网站常通过User-Agent识别爬虫,需使用真实浏览器标识。headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'}随机更换User-Agent能降低被封禁的风险,可使用
fake_useragent库生成随机值。 -
使用代理IP池
高频请求易触发IP封禁,需构建代理IP池,代码示例:proxies = {'http': 'http://10.10.1.10:3128', 'https': 'https://10.10.1.10:1080'} response = requests.get(url, proxies=proxies)代理IP池需定期更新,可从第三方平台购买或使用免费资源,但需注意合法性和稳定性。
-
处理验证码与登录验证
部分网站需验证码或登录状态才能访问,需借助第三方工具如pyotp或Selenium模拟操作。from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, 'captcha')) )验证码处理复杂度高,建议优先选择无需登录的公开数据源。
数据存储与导出
-
结构化数据存储
CSV文件适合保存表格数据,代码示例:import csv with open('data.csv', 'w', newline='') as f: writer = csv.writer(f) writer.writerow(['标题', '内容']) writer.writerows(data)数据库存储需使用
pymysql或MongoDB,import pymongo client = pymongo.MongoClient('mongodb://localhost:27017/') db = client['crawler_db'] collection = db['data'] collection.insert_one({'title': '示例', 'content': '内容'}) -
非结构化数据导出
JSON格式能保留数据嵌套结构,适合API数据:import json with open('data.json', 'w') as f: json.dump(data, f, indent=4)文件分片处理大数据量时,需按时间或页码分割文件,避免内存溢出。
-
数据清洗与格式转换
提取的数据可能包含冗余信息,需使用正则表达式过滤无效内容:import re cleaned = re.sub(r'<.*?>', '', response.text)
标准化处理如统一时间格式、去除空格,能提升数据可用性。
法律与伦理问题
-
遵守网站robots.txt规则
robots.txt文件规定了爬虫可访问的路径,需优先遵循。import urllib.robotparser rp = urllib.robotparser.RobotFileParser() rp.set_url('https://example.com/robots.txt') rp.read() if rp.can_fetch('*', url): # 允许爬取违反规则可能导致法律纠纷或被封禁。
-
避免侵犯隐私与版权
爬虫需确保不抓取敏感信息(如个人数据)或未经授权的版权内容。数据脱敏处理(如去除手机号、地址)是必要步骤。 -
合规建议与备案
若需大规模爬取,建议联系网站管理员获取授权,并备案爬虫用途。法律风险可能涉及《计算机信息网络国际联网安全保护管理办法》等法规,需谨慎操作。
进阶优化技巧
-
异步请求提升效率
使用aiohttp和asyncio实现异步爬取,减少等待时间:import aiohttp async with aiohttp.ClientSession() as session: async with session.get(url) as resp: data = await resp.text()异步请求适合处理高并发任务,但需注意资源占用问题。
-
分布式爬虫框架
Scrapy-Redis可实现分布式爬虫,支持多节点协作:from scrapy_redis.spiders import RedisCrawlSpider class MySpider(RedisCrawlSpider): name = 'my_spider' start_urls = ['http://example.com']分布式架构能显著提升爬取速度,但需配置Redis服务器。
-
自动化工具集成
Playwright支持浏览器自动化,能处理复杂交互:from playwright.sync_api import sync_playwright with sync_playwright() as p: browser = p.chromium.launch() page = browser.new_page() page.goto(url) page.click('button#submit')自动化工具适合动态网页,但需学习其API接口。
Python爬虫的完整代码需覆盖环境搭建、数据获取、解析处理、存储优化和法律合规等环节。核心代码结构的合理性直接影响爬虫效率,而反爬策略的应对能力决定能否稳定运行,建议从简单网站入手,逐步掌握异步和分布式技术,同时始终遵守法律法规,避免技术滥用。
“python爬虫网站完整代码,Python爬虫实战,网站数据抓取完整代码解析” 的相关文章

contract,智能合约,构建去中心化信任的数字桥梁
智能合约,作为构建去中心化信任的关键技术,通过合约自动执行,确保各方在数字世界中的权益和承诺得以实现,它消除了传统交易中的中介环节,降低了交易成本,提高了效率,成为连接数字经济的数字桥梁。合同,企业与个人合作的桥梁 我最近遇到了一些合同方面的问题,想请教一下这方面的知识,我听说合同很重要,但是具体...

织梦网名,编织梦想的网名天地
织梦网名,一个专注于提供创意网名的平台,旨在帮助用户寻找独特、有意义的网名,通过丰富的词汇库和个性化定制,用户可以轻松打造出符合自己个性和兴趣的网名,无论是用于社交媒体、游戏还是其他网络空间,都能展现个性风采,织梦网名致力于为用户提供一站式网名解决方案,让每个人都能在虚拟世界中留下独特的印记。织梦网...

随机数生成器懒人工具,一键式随机数生成,懒人必备工具
懒人随机数生成器是一款便捷的在线工具,用户只需输入所需的数字范围和数量,即可一键生成随机数列表,它简化了随机数生成的过程,节省用户时间和精力,适用于各类场景,如抽奖、密码生成、随机选择等。随机数生成器懒人工具——轻松解决你的随机需求 真实用户解答: 嗨,我是小明,一个程序员,最近在写一个需要随机...
php读取文件夹所有文件,PHP遍历文件夹中所有文件的技巧与代码示例
PHP读取文件夹中所有文件的代码摘要如下:,``php,,`,此代码段使用scandir()函数获取指定文件夹内的所有文件和目录列表,然后遍历这些条目,排除.和..`(代表当前目录和父目录),并输出每个文件的名称。 嗨,大家好!我最近在做一个PHP项目,需要在服务器上读取一个文件夹中所有的文件,我...
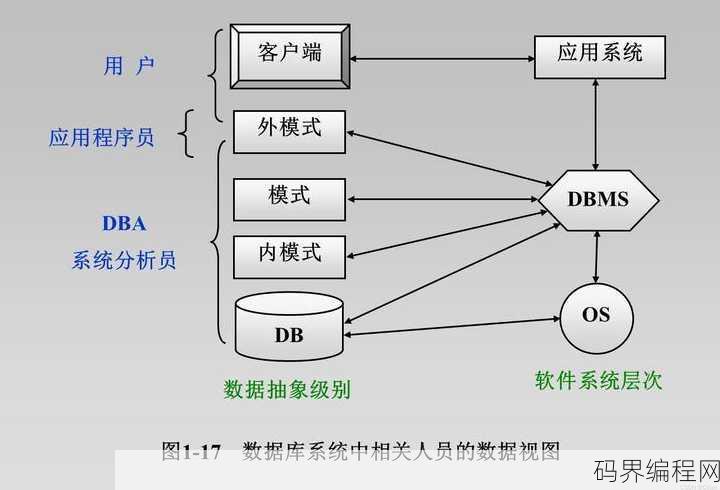
数据库系统主要包括,数据库系统核心组成部分解析
数据库系统主要包括数据库、数据库管理系统(DBMS)、数据库管理员(DBA)、应用程序和用户,数据库是存储数据的仓库,由表、视图、索引等组成;数据库管理系统负责数据库的创建、维护、查询和管理;数据库管理员负责数据库的安全、备份和恢复;应用程序通过数据库管理系统与数据库交互,实现对数据的操作;用户则是...

第一ppt模板免费下载官网,免费下载第一PPT模板官方网站
提供的是关于“第一ppt模板免费下载官网”的信息,摘要如下:,介绍了一个提供免费PPT模板下载的官方网站,用户可以在此平台免费下载各种风格的PPT模板,方便快捷地用于商务演示、教学展示等场合。”第一PPT模板免费下载官网,轻松打造专业演示文稿 用户解答: 嗨,我最近在准备一个重要的项目汇报,但是...
- 最新发布
-
7分钟前
14分钟前
21分钟前

24分钟前

32分钟前
- 热门阅读
-

912 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言