爬虫系统(爬虫管理系统)
本文目录一览:
爬虫是什么
1、网络爬虫通俗地讲,就是自动在网络上抓取数据的程序。以下是关于网络爬虫的几点详细解释:行为模拟:网络爬虫像隐身的探索者,模拟人类的点击行为,在各个网站间无声无息地穿梭。它们通过发送请求到目标网站,获取网页内容。数据抓取:爬虫的主要任务是抓取数据。无论是网页上的文本、图片还是其他信息,只要爬虫被设计来抓取,它们都能完成这一任务。
2、技术层面,爬虫核心是前端技术,黑客是为信息安全;数据层面,一个是公开,一个是私有。爬虫是黑客的一个小小技能。数据公私之分 爬虫是获取公开的数据,黑客是获取私有的数据。一个是将用户浏览的数据用程序自动化的方式收集起来,一个是寻找漏洞获取私密数据,又可分为白帽黑客和黑帽黑客。
3、卫生间出现的晶莹透亮的软体爬虫可能是鼻涕虫,也称为蜒蚰。这种小动物体态柔软,常见于潮湿的环境中。 鼻涕虫对盐的反应非常敏感。由于盐的浓度高于它们体内的水分浓度,它们会因为体内水分被吸出而死亡,看起来就像化成了一摊水。
4、被骂“爬虫”是指在互联网上从网页中提取数据的程序,它可以收集大量的数据并分析。但是,爬虫也被用于非法、不道德或侵犯隐私的目的。因此,大部分的人对爬虫不是持赞成的态度。在某些情况下,爬虫被用来获取敏感信息或者大规模的数据盗取。
简单的网络爬虫架构有哪些构成?
1、简单的网络爬虫架构通常由以下四个主要组成部分构成: 爬取器(Crawler):用于获取网页内容的程序,可以通过HTTP协议来请求网站的页面,并从响应中获取所需的数据。 解析器(Parser):用于解析网页内容的程序,可以将HTML、XML等格式的文档转换为程序可识别的结构化数据。
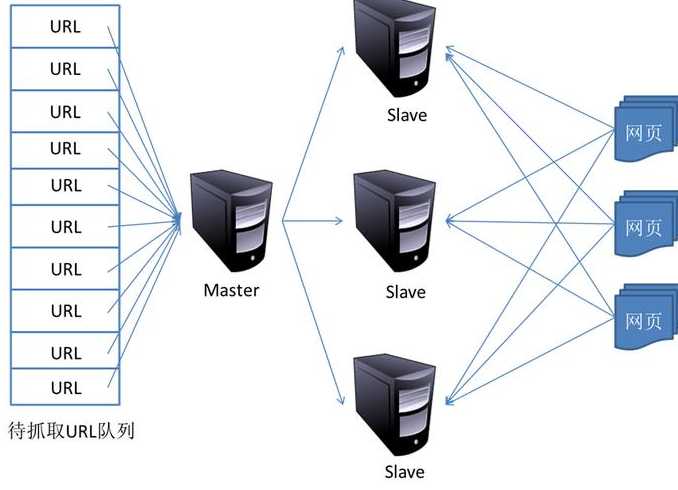
2、主流爬虫框架通常由以下部分组成:种子URL库:URL用于定位互联网中的各类资源,如最常见的网页链接,还有常见的文件资源、流媒体资源等。种子URL库作为网络爬虫的入口,标识出爬虫应该从何处开始运行,指明了数据来源。数据下载器:针对不同的数据种类,需要不同的下载方式。
3、Python爬虫网络库Python爬虫网络库主要包括:urllib、requests、grab、pycurl、urllibhttplibRoboBrowser、MechanicalSoup、mechanize、socket、Unirest for Python、hyper、PySocks、treq以及aiohttp等。
python的爬虫框架有哪些?
Scrapy框架 Scrapy是一个成熟、高效的Python爬虫框架,能快速提取网络数据。广泛应用于爬虫开发、数据挖掘、数据监测、自动化测试等领域。 Crawley框架 Crawley框架专注于改变数据获取方式,提供简单易用的工具,帮助开发者高效开发。
Scrapy,是一个高级爬虫框架,专为快速高效地抓取网站并提取结构化数据而设计。除了用于构建复杂的爬虫项目,Scrapy还支持项目文件结构,内置选择器功能,能够快速异步处理请求,自动化提取数据。
python爬虫框架讲解:Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。
python爬虫框架有哪些?python爬虫框架讲解
1、Scrapy框架 Scrapy是一个成熟、高效的Python爬虫框架,能快速提取网络数据。广泛应用于爬虫开发、数据挖掘、数据监测、自动化测试等领域。 Crawley框架 Crawley框架专注于改变数据获取方式,提供简单易用的工具,帮助开发者高效开发。
2、Scrapy,是一个高级爬虫框架,专为快速高效地抓取网站并提取结构化数据而设计。除了用于构建复杂的爬虫项目,Scrapy还支持项目文件结构,内置选择器功能,能够快速异步处理请求,自动化提取数据。
3、python爬虫框架讲解:Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。
盘点10大“网络爬虫”工具,看看有没有你用过的
八爪鱼:国内知名且业界领先的网络爬虫软件,以其多场景适应性和丰富的功能著称,是众多职业人士的首选。火车头:以高灵活度和强大性能深受用户喜爱。其分布式高速采集系统打破操作局限,高效提升效率,适用于数据抓取、处理、分析及挖掘。
八爪鱼,国内知名且业界领先的网络爬虫软件。其多场景适应性,以及丰富的功能如模板采集、智能采集、云采集等,使其成为众多职业人士的首选。火车头,以高灵活度和强大性能著称,深受用户喜爱。其分布式高速采集系统,打破操作局限,高效提升效率。适用于数据抓取、处理、分析及挖掘。
八爪鱼:简介:国内知名且领先的爬虫工具,适用于多种职业,如产品、运营等。功能:提供模板采集、智能采集等多元功能,适合复杂业务场景。火车头:简介:人气爆棚的抓取处理工具。特点:配置灵活,性能强大,拥有分布式采集系统和实时监控,适合大量数据采集和处理。收费版本性价比高。
Scrapy是一个非常强大的爬虫框架,支持异步爬取,可以处理复杂的网页结构。BeautifulSoup则以其简洁的API和强大的HTML解析能力著称,适合处理HTML文档。Requests库则以其简单易用的特点受到广泛欢迎,适合进行HTTP请求。除了Python,还有其他语言的爬虫工具也很出色。
“爬虫系统(爬虫管理系统)” 的相关文章

java书籍图片,Java编程经典书籍精选图集
较为简略,无法生成具体的摘要,请提供更多关于该Java书籍的详细信息,如书名、作者、内容的介绍等,以便我为您生成一段摘要。Java书籍图片:开启编程之旅的指南针 用户解答: 嗨,大家好!我是一名Java初学者,最近在找一些关于Java编程的书籍,希望能找到一些既有深度又有广度的,我在网上看到了很...
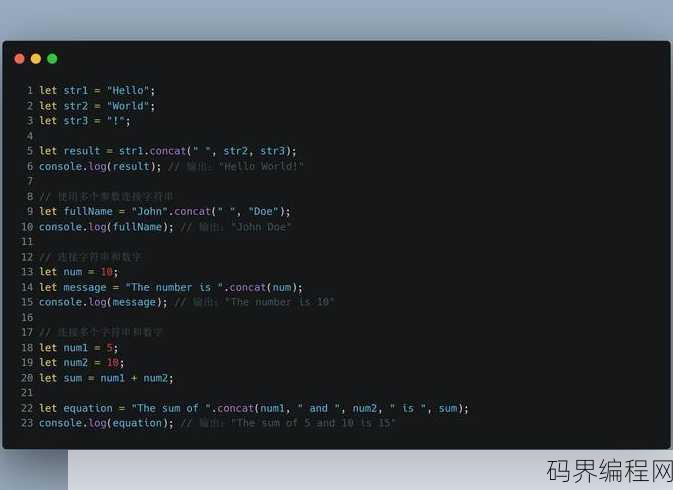
js拼接字符串方法,JavaScript字符串拼接技巧汇总
JavaScript中拼接字符串的方法有多种,最常见的是使用加号(+)操作符,"Hello, " + "world!",还可以使用模板字符串(ES6引入),使用反引号(` `)包围字符串,并在其中插入变量,如: Hello, ${name}! ,还可以使用字符串的concat()方法,或者使用jo...

columns函数是什么意思,深入解析,columns函数在编程中的含义与应用
columns函数通常用于数据库查询中,它指的是在SQL语句中用来指定查询结果中应包含的列,这个函数可以用来选择特定的列,排除不需要的列,或者对列进行重命名,在SQL查询中,SELECT columns FROM table_name;会从table_name表中选取指定的columns列,在不同的...

七星瓢虫java模拟器,Java版七星瓢虫模拟器体验之旅
七星瓢虫Java模拟器是一款模拟七星瓢虫行为的Java应用程序,该模拟器通过图形界面展示七星瓢虫的运动轨迹和觅食行为,旨在帮助用户了解昆虫生态学,用户可以观察七星瓢虫在不同环境下的反应,以及它们如何寻找食物和适应环境,模拟器包含多种可调节参数,如食物分布、温度和湿度,允许用户进行实验研究。七星瓢虫J...

开鲁网站seo,开鲁网站SEO优化策略全解析
开鲁网站SEO(搜索引擎优化)策略涉及提升网站在搜索引擎结果页面(SERP)中的排名,吸引更多潜在访客,这包括优化关键词、提升网站结构、增强用户体验、增加外部链接以及持续的内容更新,通过实施这些策略,开鲁网站能更有效地在竞争激烈的网络环境中脱颖而出,提升品牌知名度和市场份额。用户提问:我想了解一下开...
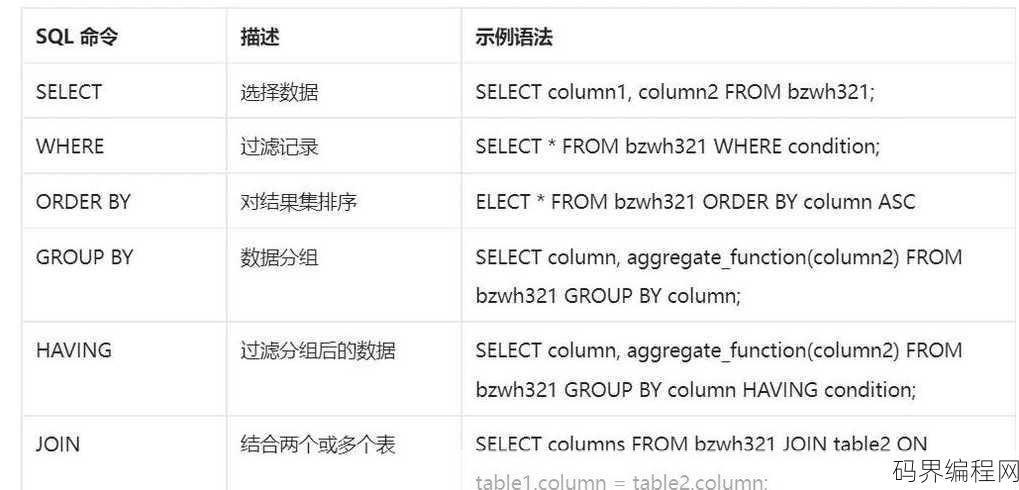
sql数据库入门自学教程,SQL数据库自学入门指南
本教程旨在帮助初学者快速掌握SQL数据库,从基础知识入手,逐步讲解SQL语言、数据库设计、数据查询、数据插入、更新和删除等操作,通过实例演示,让读者轻松学会如何使用SQL进行数据库管理,教程内容丰富,图文并茂,适合自学。SQL数据库入门自学教程** 大家好,我是小明,一个对编程充满热情的初学者,我...
- 最新发布
-
4分钟前
12分钟前
19分钟前
25分钟前
32分钟前
- 热门阅读
-

916 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言