python爬虫框架,Python爬虫框架全解析
Python爬虫框架通常指的是使用Python语言开发的爬虫程序所依赖的一系列工具和库,它们简化了数据抓取和解析过程,这些框架提供了丰富的API和模块,如Requests用于发送HTTP请求,BeautifulSoup或lxml用于解析HTML和XML文档,Scrapy则是一个功能强大的爬虫框架,支持异步处理和分布式爬取,使用Python爬虫框架,开发者可以高效地从各种网络资源中提取信息,同时框架也注重遵守网站使用协议和法律法规,确保数据抓取的合法性和正当性。
用户提问:我想学习Python爬虫,但是市面上有很多框架,我该如何选择合适的爬虫框架呢?
回答:选择合适的Python爬虫框架首先需要明确你的需求,比如爬取的数据类型、爬取频率、是否需要高并发等,下面我将从几个常见的爬虫框架进行介绍,帮助你更好地选择。
一:Scrapy框架介绍
-
Scrapy的优势:
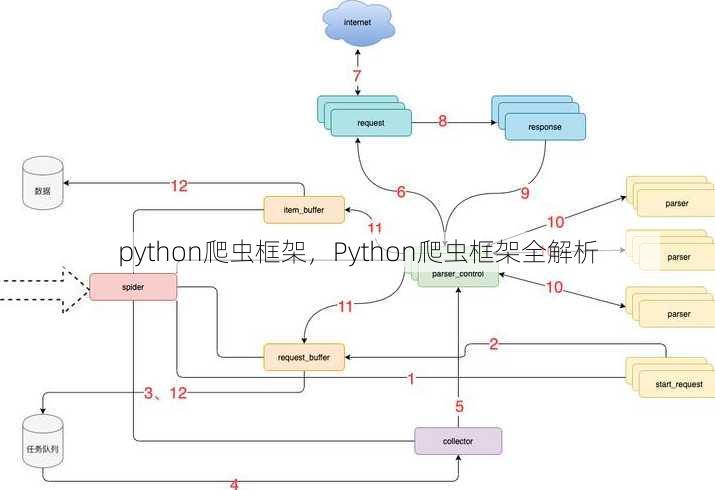
- 高性能:Scrapy是异步框架,可以处理大量并发请求,提高爬取效率。
- 易于扩展:Scrapy提供丰富的中间件和扩展插件,方便定制化需求。
- 易于使用:Scrapy拥有清晰的文档和社区支持,新手也能快速上手。
-
Scrapy的适用场景:
- 大规模数据爬取:适用于需要处理大量数据的情况,如网站数据抓取、电商数据抓取等。
- 高并发爬取:适用于需要同时处理多个请求的场景,如新闻网站爬取。
-
Scrapy的使用建议:
- 熟悉Scrapy架构:了解Scrapy的组件,如爬虫、爬虫引擎、下载器、爬虫中间件等。
- 合理设置爬取策略:根据目标网站的特点,合理设置请求深度、延迟等参数。
- 注意遵守法律法规:在爬取数据时,要遵守相关法律法规,尊重网站版权。
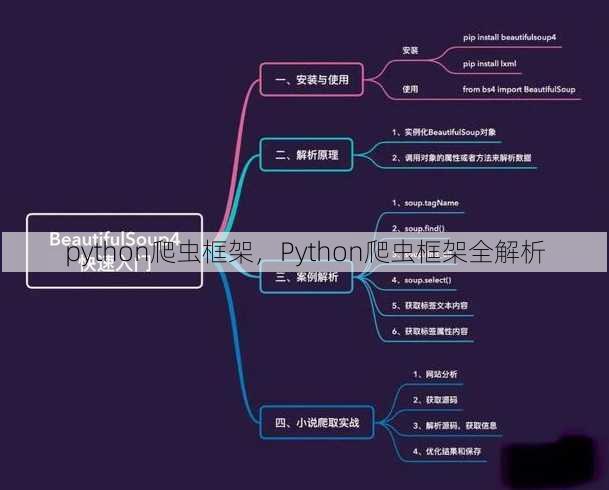
二:BeautifulSoup框架介绍
-
BeautifulSoup的优势:
- 解析HTML/XML:BeautifulSoup能够快速解析HTML/XML文档,提取所需数据。
- 简单易用:BeautifulSoup的语法简洁,易于学习。
- 跨平台:BeautifulSoup支持Python 2和Python 3。
-
BeautifulSoup的适用场景:
- 提取:适用于需要提取网页内容的场景,如文章、图片、视频等。
- 数据清洗:适用于对提取的数据进行清洗和处理的场景。
-
BeautifulSoup的使用建议:
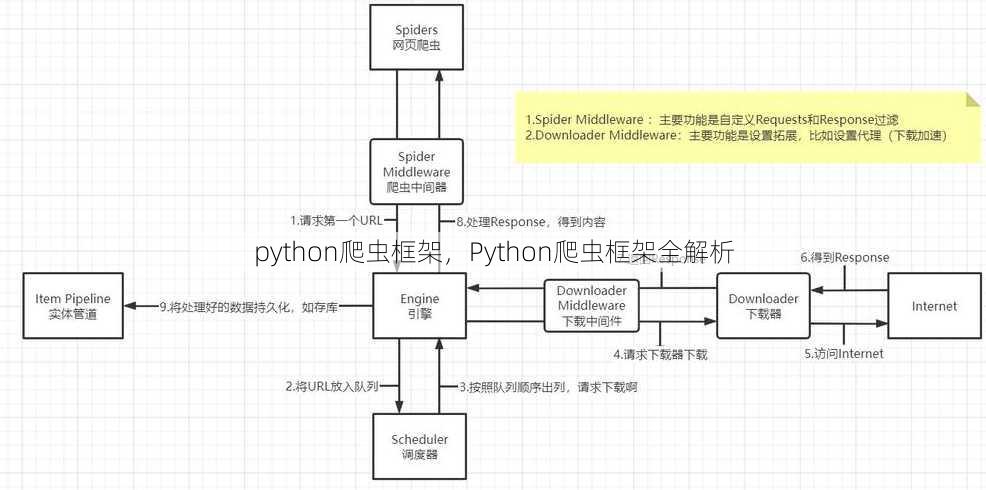
- 了解HTML/XML结构:在解析之前,要了解目标网页的HTML/XML结构。
- 掌握BeautifulSoup语法:熟悉BeautifulSoup的选择器、过滤器和方法。
- 注意异常处理:在解析过程中,要注意异常处理,防止程序崩溃。
三:Selenium框架介绍
-
Selenium的优势:
- 模拟浏览器行为:Selenium可以模拟浏览器操作,如点击、滚动、输入等。
- 支持多种浏览器:Selenium支持Chrome、Firefox、IE等多种浏览器。
- 自动化测试:Selenium可以用于自动化测试,提高测试效率。
-
Selenium的适用场景:
- 动态网页爬取:适用于需要模拟浏览器操作的场景,如登录、滑动验证码等。
- 自动化测试:适用于自动化测试,如功能测试、性能测试等。
-
Selenium的使用建议:
- 熟悉浏览器操作:在编写脚本之前,要熟悉目标网页的浏览器操作。
- 掌握Selenium API:了解Selenium的常用方法和选择器。
- 注意异常处理:在自动化测试过程中,要注意异常处理,防止测试失败。
四:PyQuery框架介绍
-
PyQuery的优势:
- 简洁语法:PyQuery的语法类似于jQuery,简洁易学。
- 高效解析:PyQuery能够快速解析HTML/XML文档,提取所需数据。
- 跨平台:PyQuery支持Python 2和Python 3。
-
PyQuery的适用场景:
- 提取:适用于需要提取网页内容的场景,如文章、图片、视频等。
- 数据清洗:适用于对提取的数据进行清洗和处理的场景。
-
PyQuery的使用建议:
- 了解HTML/XML结构:在解析之前,要了解目标网页的HTML/XML结构。
- 掌握PyQuery语法:熟悉PyQuery的选择器、过滤器和方法。
- 注意异常处理:在解析过程中,要注意异常处理,防止程序崩溃。
五:Scrapy-Redis框架介绍
-
Scrapy-Redis的优势:
- 分布式爬取:Scrapy-Redis可以将爬取任务分配到多个节点,提高爬取效率。
- 支持分布式队列:Scrapy-Redis支持Redis作为分布式队列,实现任务分发。
- 易于部署:Scrapy-Redis支持Scrapy的部署方式,方便使用。
-
Scrapy-Redis的适用场景:
- 大规模数据爬取:适用于需要处理大量数据的情况,如网站数据抓取、电商数据抓取等。
- 高并发爬取:适用于需要同时处理多个请求的场景,如新闻网站爬取。
-
Scrapy-Redis的使用建议:
- 熟悉Scrapy-Redis架构:了解Scrapy-Redis的组件,如爬虫、爬虫引擎、下载器、爬虫中间件等。
- 合理设置爬取策略:根据目标网站的特点,合理设置请求深度、延迟等参数。
- 注意遵守法律法规:在爬取数据时,要遵守相关法律法规,尊重网站版权。
通过以上介绍,相信你已经对Python爬虫框架有了更深入的了解,在选择合适的爬虫框架时,要根据你的实际需求进行选择,并结合相关框架的优势和适用场景进行综合考虑,希望这篇文章能帮助你更好地学习Python爬虫。
其他相关扩展阅读资料参考文献:
Scrapy框架的核心优势
- 高性能与异步IO:Scrapy基于异步IO模型,通过事件循环高效处理大量请求,单机可同时抓取数百个网页,显著提升爬虫效率。
- 结构化数据处理:内置强大的解析器,支持XPath、CSS选择器和JSON提取,可快速将网页内容转化为结构化数据(如字典、CSV)。
- 中间件支持:提供请求拦截和响应处理机制,例如通过USER_AGENT伪装浏览器、PROXY池解决IP封锁、DOWNLOAD_DELAY控制请求频率。
- 可扩展性:通过自定义Spider、Item Pipeline和Middleware,可灵活适配不同爬取需求,如数据清洗、存储和反爬策略。
BeautifulSoup与Scrapy的对比
- 适用场景:BeautifulSoup适合小规模静态页面抓取,而Scrapy更适合复杂项目(如需处理反爬、分布式爬取)。
- 性能差异:BeautifulSoup是同步阻塞框架,Scrapy通过异步IO实现高并发,处理大规模数据时效率差距明显。
- 代码复杂度:BeautifulSoup代码简洁,只需几行即可完成抓取;Scrapy需要配置settings.py、定义Spider和Pipeline,复杂度更高。
- 学习曲线:BeautifulSoup适合初学者快速上手,Scrapy需掌握异步编程、中间件机制等概念,学习成本较高。
Selenium框架的适用场景
- 抓取:Selenium可模拟浏览器操作,解决JavaScript渲染页面的问题,适合抓取需要交互的动态网页。
- 反爬策略应对:通过headless模式绕过浏览器指纹检测,或使用验证码识别工具(如云打码)破解图形验证码。
- 浏览器自动化:支持点击、输入、下拉菜单等操作,可模拟用户行为,适用于需要登录或操作的网页(如电商比价)。
- 兼容性优势:支持Chrome、Firefox等主流浏览器,可兼容不同网页结构,但资源占用较高,不适合大规模爬取。
Requests-HTML框架的便捷性
- 简化请求流程:基于Requests库,通过HTMLSession直接发起请求,无需手动处理headers和cookies。
- 内置解析器:集成lxml库,支持XPath和CSS选择器,同时提供find()方法简化元素定位。
- 支持动态内容:通过JavaScript渲染功能(如使用PyExecJS)抓取动态加载的数据,但性能不如Scrapy。
- 跨平台兼容:代码结构轻量,适合快速开发小型爬虫,但缺乏Scrapy的分布式和反爬中间件支持。
异步爬虫框架的高效处理
- 异步IO机制:使用aiohttp或Playwright等框架,通过非阻塞方式并发处理请求,减少等待时间。
- 高并发能力:可同时发起数千个请求,适合大规模数据采集任务,但需注意服务器压力和法律风险。
- 资源管理优化:通过连接池复用TCP连接,降低资源消耗,提升爬虫稳定性。
- 性能提升:异步框架在抓取速度上比同步框架快3-10倍,但代码复杂度和调试难度更高。
Python爬虫框架的选择需结合具体需求:Scrapy适合复杂项目,BeautifulSoup适合快速开发,Selenium应对动态内容,Requests-HTML平衡便捷与功能,异步框架则追求极致性能。掌握框架的核心特性,才能高效完成爬虫任务,若需抓取需登录的动态网页,Selenium是首选;若追求高并发,异步框架更优。合理选择工具,避免过度设计,是爬虫开发的关键。
“python爬虫框架,Python爬虫框架全解析” 的相关文章

aligner,创新科技引领,aligner重塑牙齿矫正新体验
Aligner是一种用于牙齿矫正的透明矫治器,通过逐步调整牙齿位置来达到矫正效果,它由一系列定制化的透明塑料矫治器组成,患者需按顺序佩戴,每副矫治器持续两周左右,Aligner相较于传统金属牙套,具有美观、舒适、方便等优点,适用于轻至中度牙齿不齐的患者。用户提问:我想了解aligner是什么,它有什...

正则表达式是用来干什么的,揭秘正则表达式,高效数据处理利器
正则表达式是一种用于处理字符串的强大工具,主要用于匹配、搜索、替换文本,它通过特定的符号和字符组合,定义一组规则,从而实现对文本的精确查找和操作,在编程和数据处理中,正则表达式广泛应用于验证输入格式、提取信息、文本替换等场景,极大提高了处理文本的效率和准确性。正则表达式是用来干什么的 用户解答:...

plc编程软件怎么下载安装,PLC编程软件下载与安装指南
PLC编程软件的下载与安装步骤如下:访问PLC制造商的官方网站或授权经销商网站,下载适用于您PLC型号的编程软件,下载完成后,运行安装程序,按照提示进行安装,在安装过程中,可能需要选择安装组件、设置语言和配置路径,安装完成后,运行软件并按照软件指南进行配置,以便与您的PLC进行通信,确保在安装过程中...

c语言入门自学笔记,C语言自学笔记,入门实践指南
本笔记为C语言入门自学指南,涵盖基础知识、语法规则、数据类型、运算符、控制结构、函数、数组、指针等核心概念,通过实例讲解,帮助初学者快速掌握C语言编程,逐步提升编程能力,笔记内容丰富,适合自学爱好者阅读。C语言入门自学笔记 大家好,我是小王,一个刚刚开始学习C语言的新手,我花了不少时间自学C语...

java包下载,Java包一键下载指南
Java包下载通常指的是从官方或第三方仓库下载Java库、框架或工具的压缩文件,用户可以通过Java的包管理工具如Maven或Gradle,或者直接访问官方网站如Central Repository来下载所需的Java包,下载过程通常涉及指定包的名称和版本,然后系统会自动下载并安装到本地仓库中,以便...

onkeydown,探索onkeydown事件,网页交互新维度
"onkeydown"是一个JavaScript事件,当用户按下键盘上的任意键时触发,此事件可以用于检测用户输入,实现如文本框内容变化、表单验证等动态交互功能,开发者可以通过监听此事件,编写代码来响应按键操作,增强网页或应用程序的用户体验。解析“onkeydown”事件 用户解答: “我最近在使...
- 最新发布
-
4分钟前

12分钟前

18分钟前

26分钟前
33分钟前
- 热门阅读
-

903 浏览学习方法

242 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言