group by,分组统计,深入理解SQL中的GROUP BY语句
GROUP BY 是SQL查询中的一种语句,用于对查询结果进行分组,它允许用户按照一个或多个列对数据进行分组,并可以与聚合函数一起使用,以计算每个组的统计信息,如总和、平均值、计数等,通过GROUP BY,用户可以更有效地分析和展示数据。
解析SQL中的“GROUP BY”
用户解答: 嗨,大家好!我最近在学习SQL数据库,遇到了一个挺有意思的问题,我在处理数据时,需要按照某个字段进行分组统计,这时候就经常用到“GROUP BY”语句,我对这个语句的理解还不够深入,想请教一下大家,有没有什么好的解释或者例子可以帮助我更好地理解“GROUP BY”呢?
下面,我就从几个出发,为大家地解析一下“GROUP BY”。

一:什么是GROUP BY?
- 定义:GROUP BY是SQL中用于对结果集进行分组的一种语句。
- 作用:通过GROUP BY,可以将具有相同值的记录分组在一起,并对每个组进行聚合操作。
- 使用场景:当你需要统计某个字段在不同值下的总数、平均值、最大值等时,GROUP BY就非常有用了。
二:GROUP BY的语法
- 基本语法:SELECT column_name(s), aggregate_function(column_name) FROM table_name GROUP BY column_name;
- 聚合函数:常用的聚合函数有COUNT(), SUM(), AVG(), MAX(), MIN()等。
- 多列分组:GROUP BY可以同时对多个列进行分组,GROUP BY column1, column2。
三:GROUP BY与HAVING的区别
- GROUP BY:用于对结果集进行分组,不涉及筛选条件。
- HAVING:用于对分组后的结果集进行筛选,相当于SQL中的WHERE子句。
- 使用场景:GROUP BY用于分组,HAVING用于筛选分组后的结果。
四:GROUP BY的注意事项
- **避免使用SELECT **:在使用GROUP BY时,避免使用SELECT ,而是指定具体的列名,这样可以提高查询效率。
- 避免使用非聚合函数:在GROUP BY子句中,避免使用非聚合函数,如DISTINCT、ORDER BY等。
- 使用索引:如果查询中包含GROUP BY的列,建议在该列上创建索引,以提高查询性能。
五:GROUP BY的实际应用
- 统计销售额:SELECT product_name, SUM(sales_amount) FROM sales GROUP BY product_name;
- 统计客户数量:SELECT customer_region, COUNT(customer_id) FROM customers GROUP BY customer_region;
- 统计订单数量:SELECT order_date, COUNT(order_id) FROM orders GROUP BY order_date;
通过以上解析,相信大家对GROUP BY有了更深入的理解,在实际应用中,GROUP BY是一个非常实用的SQL语句,可以帮助我们快速统计和分析数据,希望这篇文章能对大家有所帮助!
其他相关扩展阅读资料参考文献:
GROUP BY的核心作用
-
实现数据分类统计
GROUP BY的核心功能是将数据表中的行按指定字段分组,便于进行聚合计算,统计每个部门的员工数量时,需通过GROUP BY部门字段,再结合COUNT()函数。分组后,每组的数据会被视为一个整体,所有非分组字段需使用聚合函数处理,否则会报错。 -
支持多维数据透视
GROUP BY可以同时按多个字段分组,实现数据的多维交叉分析,按“地区-产品类型”组合分组,可同时统计各区域不同产品的销售总量。多字段分组时需注意字段顺序,避免因逻辑混乱导致结果偏差。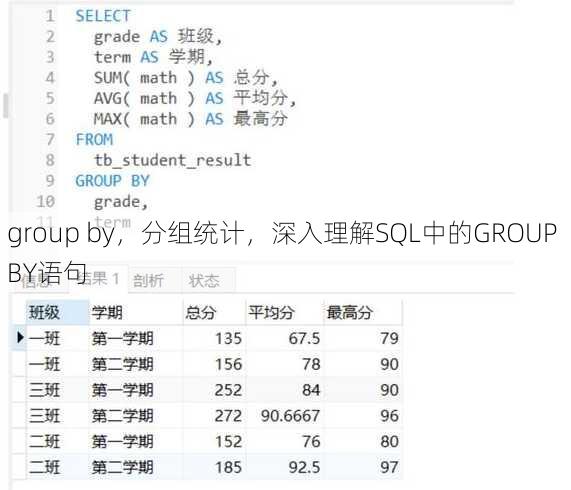
-
去重与唯一性筛选
当需要获取某一字段的唯一值时,GROUP BY可替代DISTINCT关键字,查询所有不同客户的订单数量,需用GROUP BY客户ID。与DISTINCT的区别在于,GROUP BY能结合聚合函数进行更复杂的统计,而DISTINCT仅用于去重。
GROUP BY的语法与实现细节
-
基本语法结构
GROUP BY的语法为:SELECT 字段1, 字段2, 聚合函数(...) FROM 表名 GROUP BY 字段1, 字段2。必须将非聚合字段放入GROUP BY子句,否则数据库无法确定如何归类。 -
分组条件的灵活运用
分组条件可通过表达式实现,例如按“年份”分组时,可使用YEAR(订单日期)作为分组字段。分组条件需与数据表中的字段类型兼容,避免因数据格式问题导致分组失败。 -
与HAVING的协同过滤
HAVING用于过滤分组后的结果集,与GROUP BY配合使用可实现复杂条件筛选,统计销售额超过10万元的部门,需在GROUP BY后添加HAVING SUM(销售额) > 100000。HAVING与WHERE的区别在于,WHERE过滤原始数据,HAVING过滤聚合结果。
GROUP BY的实际应用场景
-
统计报表生成
在业务报表中,GROUP BY常用于按时间、地域或产品分类统计,按月统计销售额,需用GROUP BY YEAR(订单日期), MONTH(订单日期),再结合SUM()计算总和。分组字段的选择需与业务需求高度匹配,否则统计结果失去意义。 -
数据透视表构建
GROUP BY可将多维数据转换为二维表格,例如将销售数据按地区和产品类型分组,生成每个区域不同产品的销量分布。数据透视时需确保分组字段的组合不会导致数据膨胀,避免性能问题。 -
用户行为分析
在用户分析场景中,GROUP BY可用于统计用户活跃度、购买频次等,按用户ID分组后计算每个用户的订单数量,可发现高价值用户或流失用户。分组粒度需根据分析目标调整,过细可能遗漏趋势,过粗则失去细节。
GROUP BY的性能优化策略
-
合理使用索引
在分组字段上建立索引可大幅提升查询效率,对“客户ID”字段加索引后,GROUP BY操作的执行时间会显著减少。索引优化需权衡存储成本与查询性能,避免过度索引导致写入延迟。 -
避免过度分组
过多的分组字段会增加计算复杂度,甚至引发性能瓶颈,同时按“地区、产品类型、时间”分组可能导致数据碎片化。分组字段应尽量精简,仅保留必要的分类维度。 -
利用分区表加速查询
将数据表按分组字段(如时间或地域)进行分区后,GROUP BY可直接作用于分区数据,减少扫描量,按“年份”分区的订单表,查询某一年的销售数据效率更高。分区策略需与业务场景和数据分布规律一致,否则无法发挥优势。
GROUP BY的常见误区与解决方案
-
忽略排序导致结果混乱
GROUP BY分组后,若未配合ORDER BY排序,结果可能无序,按部门分组后未排序,可能导致数据展示不符合预期。建议在分组后明确指定排序字段,确保结果可读性。 -
分组字段与WHERE顺序混淆
WHERE子句用于过滤原始数据,而GROUP BY字段需在WHERE之后定义,先筛选出某区域的数据,再按产品类型分组。错误的顺序可能导致分组逻辑失效,需严格遵循语法规范。 -
误解分组粒度的边界
分组粒度过细可能无法反映整体趋势,过粗则可能丢失关键信息,按“用户ID”分组统计订单数量,可能无法看出用户群体的分布规律。需根据分析目标动态调整分组粒度,例如按“用户等级”分组时,结果更具业务价值。
GROUP BY的扩展应用
-
结合子查询实现嵌套分组
GROUP BY可与子查询嵌套使用,例如先按部门分组计算平均工资,再将结果按地区分组。子查询需确保返回的数据结构与外层GROUP BY字段兼容,否则会引发错误。 -
使用ROLLUP进行层级汇总
ROLLUP是GROUP BY的扩展功能,可生成多层级汇总结果,按“地区-部门”分组时,ROLLUP会自动计算每个地区的总销售额和各部门的子总和。ROLLUP适用于需要多级统计的复杂场景,但需注意结果集的解读逻辑。 -
处理空值与分组逻辑
GROUP BY对空值的处理需特别注意,例如将NULL值视为一个独立分组,若需排除空值,需在WHERE中添加条件过滤。空值可能导致统计结果失真,需根据业务需求明确处理规则。
GROUP BY的实践建议
-
优先选择可计算的字段
GROUP BY字段应为数值型或有限枚举值,避免因字符串分组导致性能下降,按“订单状态”分组时,需确保状态值数量可控。字段值过多可能引发分组效率问题,需提前规划数据结构。 -
避免在分组中使用非确定性函数
非确定性函数(如NOW()或RAND())在分组时可能导致结果不可预测,按用户ID分组时,若使用RAND()生成随机数,每组的值会随机变化。应确保分组字段的稳定性,以保证结果的可重复性。 -
结合窗口函数提升灵活性
在部分数据库中,GROUP BY可与窗口函数(如ROW_NUMBER()或RANK())结合使用,实现更复杂的分组逻辑,按部门分组后计算每个员工的排名。窗口函数需注意分组条件与排序字段的关联性,避免逻辑冲突。
GROUP BY的未来趋势
-
与大数据技术的深度融合
随着数据量增长,GROUP BY在分布式数据库中的优化成为关键,Hadoop或Spark中通过分区策略提升分组效率。未来分组操作将更依赖并行计算和内存管理,减少磁盘I/O开销。 -
智能化分组策略
AI技术可能被引入数据库,自动推荐分组字段和粒度,根据历史数据预测最佳分组维度。智能化分组需结合业务场景和数据特征,避免过度依赖算法导致误判。 -
跨数据库兼容性挑战
不同数据库对GROUP BY的支持存在差异,例如MySQL与PostgreSQL在ROLLUP或窗口函数的实现上有所不同。开发者需熟悉目标数据库的语法特性,确保分组逻辑的可移植性。
GROUP BY是数据库查询中不可或缺的工具,其核心价值在于通过分组实现数据的分类与聚合。正确使用GROUP BY需理解其语法规范、性能影响及业务场景适配性,无论是生成报表、分析用户行为,还是优化查询效率,GROUP BY都能发挥关键作用。避免常见误区,合理规划分组策略,才能充分发挥其潜力,随着技术发展,GROUP BY将在大数据和AI领域迎来更广泛的应用,但其基础逻辑始终是数据分组的核心。
“group by,分组统计,深入理解SQL中的GROUP BY语句” 的相关文章
简单网址导航源码,一键打造个性化简单网址导航——源码分享
本源码为简单网址导航,包含常用网站分类和链接,用户可快速访问所需网站,代码简洁易懂,易于修改和扩展,适合个人或企业建立自己的网址导航网站。简单网址导航源码,轻松打造个性化导航网站 我在网上寻找了一些关于简单网址导航源码的信息,希望能打造一个适合自己的导航网站,经过一番搜索和比较,我发现了一些不错的...

contract,智能合约,构建去中心化信任的数字桥梁
智能合约,作为构建去中心化信任的关键技术,通过合约自动执行,确保各方在数字世界中的权益和承诺得以实现,它消除了传统交易中的中介环节,降低了交易成本,提高了效率,成为连接数字经济的数字桥梁。合同,企业与个人合作的桥梁 我最近遇到了一些合同方面的问题,想请教一下这方面的知识,我听说合同很重要,但是具体...

sumproduct完整用法,Sumproduct函数的全面解析与应用
sumproduct函数在Excel中用于计算数组或范围中对应元素的乘积,然后将这些乘积相加,其完整用法为:,SUMPRODUCT(array1, [array2], ...)。,这里,array1是必须的,其他[array2], [array3], ...是可选的数组或范围,函数可以处理两个或多个...

java是什么公司开发的,Java语言由哪家公司开发?
Java是由Sun Microsystems公司开发的,它是一种高级、面向对象的编程语言,设计初衷是为了使网络计算变得更加简单,自从1995年发布以来,Java在软件开发领域获得了广泛的应用,并且由于其跨平台的特性,Java程序可以在多种操作系统和设备上运行,Sun Microsystems后来被O...
dedecms后台地址,揭秘DedeCMS后台地址设置与安全防护
DedeCMS后台地址通常是指DedeCMS内容管理系统中的管理界面访问地址,这个地址通常是隐藏的,需要通过特定的路径来访问,DedeCMS后台地址格式为:http://您的域名/dede/,您的域名”需要替换成您的实际网站域名,出于安全考虑,后台地址不应公开,应通过安全的方式进行访问,例如使用SS...

java包下载,Java包一键下载指南
Java包下载通常指的是从官方或第三方仓库下载Java库、框架或工具的压缩文件,用户可以通过Java的包管理工具如Maven或Gradle,或者直接访问官方网站如Central Repository来下载所需的Java包,下载过程通常涉及指定包的名称和版本,然后系统会自动下载并安装到本地仓库中,以便...
- 最新发布
-

4分钟前
10分钟前

15分钟前

22分钟前
29分钟前
- 热门阅读
-

916 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言