webscraper下载,高效网页数据抓取工具,Webscraper下载指南
Webscraper是一款强大的网络爬虫工具,它能够自动抓取网站数据,包括网页内容、图片、视频等,用户只需输入目标网站地址,Webscraper便能够根据预设规则高效地提取所需信息,这款工具支持多种编程语言,操作简单,非常适合进行数据挖掘和网页自动化处理。
WebScraper下载全攻略
用户解答: 嗨,大家好!最近我在网上看到一个很强大的工具——WebScraper,听说它可以自动下载网页内容,对于数据收集和分析来说非常实用,但是我对这个工具不是很了解,想请教一下,WebScraper下载具体是怎么操作的?需要什么条件?还有,下载下来的数据如何处理呢?
下面,我将从几个出发,为大家地讲解WebScraper下载的相关知识。
一:WebScraper简介
-
什么是WebScraper? WebScraper是一款开源的Python库,它可以帮助用户从网站上抓取数据,并将其保存为CSV、JSON或其他格式。
-
WebScraper的优势
- 简单易用:WebScraper的语法简洁,易于上手。
- 功能强大:支持多种数据抓取需求,如表格、列表、图片等。
- 跨平台:支持Windows、Mac和Linux操作系统。
-
WebScraper的适用场景
- 数据分析师:用于收集网站数据,进行数据分析和可视化。
- 内容创作者:抓取网站内容,用于内容创作或比较分析。
- 研究人员:从公开网站获取数据,进行学术研究。
二:WebScraper下载步骤
-
安装Python 您需要在您的计算机上安装Python,WebScraper是基于Python的,因此Python是必须的。
-
安装WebScraper库 打开命令行窗口,输入以下命令安装WebScraper库:
pip install scrapy
-
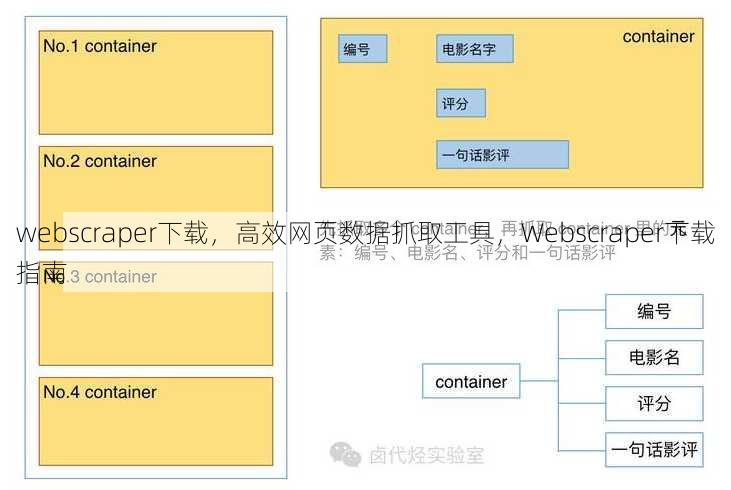
编写爬虫代码 使用Python编写爬虫代码,以下是一个简单的示例:
import scrapy class MySpider(scrapy.Spider): name = 'my_spider' start_urls = ['http://example.com'] def parse(self, response): for item in response.css('div.item'): yield { 'title': item.css('h2.title::text').get(), 'description': item.css('p.description::text').get(), } -
运行爬虫 在命令行窗口中,运行以下命令启动爬虫:
scrapy crawl my_spider
-
查看下载结果 爬虫运行完成后,数据将被保存到当前目录下的CSV文件中。
三:WebScraper数据存储
-
CSV格式 WebScraper默认将数据保存为CSV格式,方便用户进行数据处理和分析。
-
JSON格式 如果您需要以JSON格式存储数据,可以在爬虫代码中指定:

from scrapy.crawler import CrawlerProcess process = CrawlerProcess(settings={ 'FEED_FORMAT': 'json', 'FEED_URI': 'output.json', }) process.crawl(MySpider) process.start() -
数据库存储 您也可以将数据存储到数据库中,如MySQL、PostgreSQL等。
四:WebScraper注意事项
-
遵守网站robots.txt规则 在抓取数据之前,请确保您遵守目标网站的robots.txt规则,避免违规操作。
-
设置合理的爬取速度 避免过快地抓取数据,以免对目标网站造成压力。
-
处理异常情况 在爬虫代码中,要考虑并处理可能出现的异常情况,如网络错误、数据格式错误等。
五:WebScraper未来展望
-
功能扩展 随着Web技术的发展,WebScraper可能会增加更多功能,如支持异步请求、更强大的解析器等。
-
社区支持 WebScraper社区会持续提供更新和改进,为用户提供更好的使用体验。
WebScraper是一款功能强大的数据抓取工具,可以帮助用户轻松地从网站上获取数据,通过本文的讲解,相信大家对WebScraper下载有了更深入的了解,希望这篇文章能对您有所帮助!
其他相关扩展阅读资料参考文献:
Web Scraper下载:入门与实践
随着互联网的发展,数据获取变得越来越重要,Web Scraper作为一种能够从网站上提取数据的方法,受到了广泛关注,本文将介绍Web Scraper下载及其相关实践,帮助读者更好地理解和应用这一工具,本文将从以下五个展开。
一:Web Scraper简介
- Web Scraper定义:Web Scraper是一种自动化工具,用于从网站上提取结构化数据,通过模拟浏览器行为,Web Scraper能够获取网页内容并转换为可分析的数据格式。
- Web Scraper作用:Web Scraper可以大大提高数据获取效率,节省人工操作时间,它还能处理大量数据,为数据分析、数据挖掘等提供有力支持。
- Web Scraper应用领域:Web Scraper广泛应用于各个领域,如电商、金融、新闻等,通过提取网站数据,企业可以了解市场动态、竞争对手情况,为个人决策提供有力依据。
二:Web Scraper下载与安装
- 选择合适的Web Scraper工具:市面上存在多种Web Scraper工具,如Scrapy、PySpider等,读者可以根据自己的需求和编程水平选择合适的工具。
- 下载与安装步骤:以Scrapy为例,读者可以在官方网站上下载相应版本的Scrapy,然后按照官方文档进行安装,安装过程中需要注意Python环境的配置。
- 常见问题及解决方案:在下载和安装过程中,读者可能会遇到网络问题、版本不兼容等问题,针对这些问题,读者可以参考官方文档或社区论坛,寻求解决方案。
三:Web Scraper使用教程
- 基础知识:了解HTML、CSS和JavaScript等基础知识,有助于更好地使用Web Scraper。
- 抓取策略:根据网站结构,选择合适的抓取策略,如深度优先搜索、广度优先搜索等。
- 实战案例:通过实际案例,介绍Web Scraper的具体应用,读者可以通过实践,逐步掌握Web Scraper的使用方法。
四:Web Scraper优化与进阶
- 提高抓取效率:通过优化抓取策略、调整并发数等方式,提高Web Scraper的抓取效率。
- 处理反爬虫机制:部分网站会设置反爬虫机制,读者需要了解并应对这些机制,以保证Web Scraper的正常运行。
- 数据清洗与存储:提取的数据可能需要进行清洗和整理,以便后续分析,读者还需要了解如何存储和管理这些数据。
五:Web Scraper的未来发展
- 技术发展:随着技术的不断发展,Web Scraper的性能和效率将不断提高,应用范围也将进一步扩大。
- 法律法规:读者需要了解相关的法律法规,以确保在使用Web Scraper时遵守规定,避免侵权。
- 面临的挑战:Web Scraper面临着网站结构变化、反爬虫机制等挑战,读者需要关注这些挑战,并寻找解决方案。
Web Scraper作为一种强大的数据获取工具,具有广泛的应用前景,通过本文的介绍,读者可以深入了解Web Scraper的下载、安装、使用、优化及未来发展等方面知识,希望读者能够充分利用Web Scraper,提高工作效率,为数据分析、数据挖掘等提供有力支持。
“webscraper下载,高效网页数据抓取工具,Webscraper下载指南” 的相关文章

黎曼函数连续吗,黎曼函数的连续性探究
黎曼函数是黎曼积分理论中的核心概念,它是一个定义在实数集上的函数,关于黎曼函数是否连续,这取决于具体的函数形式,在黎曼积分中,通常假设被积函数是连续的,但这并不是必须的,黎曼函数本身并不一定是连续的,但许多重要的黎曼函数都是连续的,黎曼ζ函数在实数域内除了在s=1处不连续外,其他地方都是连续的,黎曼...

java是什么公司开发的,Java语言由哪家公司开发?
Java是由Sun Microsystems公司开发的,它是一种高级、面向对象的编程语言,设计初衷是为了使网络计算变得更加简单,自从1995年发布以来,Java在软件开发领域获得了广泛的应用,并且由于其跨平台的特性,Java程序可以在多种操作系统和设备上运行,Sun Microsystems后来被O...

全栈开发者网站,全栈开发者必备网站大全
全栈开发者网站是一个专注于全栈开发者的在线平台,提供全面的资源和服务,网站内容包括编程教程、工具推荐、项目案例分享、社区讨论以及职业发展指导,用户可以在这里学习前端、后端和全栈开发技能,交流经验,寻找合作机会,助力成为优秀的全栈工程师。构建你的技术王国 用户解答: 大家好,我是一名软件开发新手,...
空白代码生成器,一键生成,高效空白代码生成器
空白代码生成器是一款便捷的工具,旨在帮助开发者快速创建项目框架,用户只需输入项目名称、选择编程语言和框架,即可一键生成相应的空白代码,该工具支持多种编程语言,如Java、Python、C++等,并支持多种框架,如Spring Boot、Django等,通过使用空白代码生成器,开发者可以节省大量时间,...

asp安装教程,ASP环境搭建与安装指南
本教程详细介绍了如何安装ASP(Active Server Pages),确保您的服务器支持ASP,如Windows Server,下载并安装IIS(Internet Information Services),配置好网站和虚拟目录,设置ASP环境变量,创建ASP文件并上传到服务器,通过浏览器访问U...
数据库建模工具,高效数据库建模利器,探索专业工具新境界
数据库建模工具是一款用于设计和创建数据库结构的软件,它支持多种数据库类型,包括关系型数据库和非关系型数据库,用户可以通过图形界面直观地创建数据库模式、表、索引和视图等,同时提供数据建模、数据分析和数据转换等功能,该工具简化了数据库设计过程,提高了开发效率,适用于数据库管理员、开发者和数据分析师等。数...
- 最新发布
-
3分钟前
10分钟前
17分钟前
24分钟前
31分钟前
- 热门阅读
-

910 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言