python3爬虫入门教程,Python 3 爬虫实战入门指南
本教程为Python3爬虫入门指南,旨在帮助初学者快速掌握爬虫基础知识,内容涵盖Python爬虫环境搭建、常用库介绍(如requests、BeautifulSoup)、数据抓取与解析、错误处理及日志记录等,通过实际案例,学习如何从网页中提取信息,实现数据的自动化收集,教程适合对爬虫感兴趣的编程新手,助你轻松入门爬虫世界。
嗨,大家好!我最近对Python爬虫很感兴趣,想学习一下,但是我对编程基础不是很扎实,不知道从哪里开始,有没有什么好的入门教程推荐呢?谢谢!
一:Python爬虫基础知识
-
什么是爬虫?
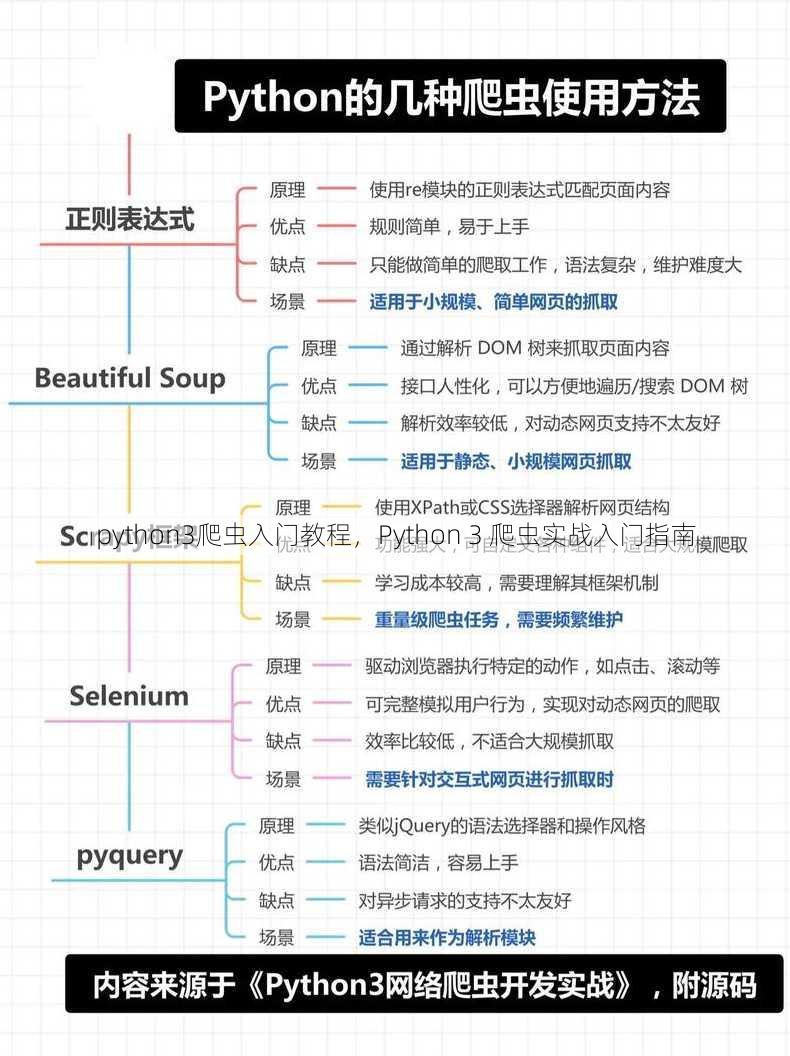
爬虫是一种自动化的程序,用于从互联网上抓取信息。
-
为什么需要爬虫?
爬虫可以帮助我们快速获取大量数据,进行数据分析或信息提取。
-
Python爬虫的优势?
Python拥有丰富的库支持,如requests、BeautifulSoup等,使得爬虫开发变得简单高效。

-
学习Python爬虫需要哪些基础?
基本的Python编程知识,了解数据结构和算法。
-
推荐的学习资源?
在线教程、书籍、视频课程等,如《Python网络爬虫从入门到实践》。
二:安装与配置Python环境
-
如何安装Python?

访问Python官网下载安装包,按照提示进行安装。
-
安装Python后如何配置环境变量?
在系统环境变量中添加Python的安装路径。
-
如何安装第三方库?
使用pip工具,通过命令行安装所需的库。
-
常见的第三方库有哪些?
requests、BeautifulSoup、Scrapy等。
-
如何查看已安装的库?
使用pip list命令查看已安装的库。
三:使用requests库进行网络请求
-
什么是requests库?
requests库是Python的一个HTTP库,用于发送HTTP请求。
-
如何使用requests库发送GET请求?
使用requests.get()方法,传入URL参数。
-
如何使用requests库发送POST请求?
使用requests.post()方法,传入URL和表单数据。
-
如何处理响应内容?
使用response对象的text或content属性获取内容。
-
如何处理异常?
使用try-except语句捕获异常,如连接错误、超时等。
四:解析网页内容
-
什么是BeautifulSoup库?
BeautifulSoup是一个Python库,用于解析HTML和XML文档。
-
如何安装BeautifulSoup库?
使用pip install beautifulsoup4命令安装。
-
如何使用BeautifulSoup解析HTML内容?
使用BeautifulSoup对象解析HTML字符串。
-
如何查找元素?
使用select、find、find_all等方法查找元素。
-
如何提取元素内容?
使用元素的text、string、get等方法提取内容。
五:数据存储与处理
-
如何存储爬取的数据?
可以将数据存储在CSV、JSON、数据库等格式中。
-
如何使用CSV格式存储数据?
使用Python的csv模块,将数据写入CSV文件。
-
如何使用JSON格式存储数据?
使用Python的json模块,将数据转换为JSON格式并写入文件。
-
如何处理大量数据?
使用pandas库进行数据处理和分析。
-
如何避免爬虫被封禁?
设置合理的请求间隔,使用代理IP等。
就是一篇关于Python3爬虫入门教程的文章,希望对大家有所帮助!
其他相关扩展阅读资料参考文献:
Python3爬虫入门教程
爬虫技术的介绍
爬虫技术是一种通过自动化程序抓取互联网上数据的技术,随着大数据时代的到来,爬虫技术越来越广泛应用于数据采集、数据挖掘等领域,Python作为一种流行的编程语言,在爬虫开发方面具有得天独厚的优势。
Python爬虫相关模块介绍
请求模块(如requests)
(1) 发送网络请求,获取网页数据。 (2) 处理HTTP响应,包括状态码和响应内容。
解析模块(如BeautifulSoup、lxml)
(1) 解析HTML或XML文档,提取所需数据。 (2) 支持多种解析方式,如CSS选择器、XPath等。
并发处理模块(如Scrapy)
(1) 实现多线程或异步IO,提高爬虫效率。 (2) 提供丰富的API,方便数据抓取和存储。
Python爬虫基本流程
发送网络请求
使用requests模块发送网络请求,获取网页HTML代码。
解析HTML
使用解析模块如BeautifulSoup解析HTML代码,提取所需数据。
数据存储
将抓取的数据存储到文件、数据库或Excel等媒介中。
Python爬虫实战案例
简单网页数据抓取
通过requests和BeautifulSoup实现简单网页数据抓取。
使用Scrapy框架爬取数据
介绍Scrapy框架的使用方法,实现高效的数据抓取和存储。
反爬虫策略与应对方法
应对User-Agent检测
通过修改User-Agent模拟浏览器访问,避免被识别为爬虫。
应对动态加载内容处理
利用Selenium等工具模拟浏览器行为,加载并执行JavaScript代码。
遵守爬虫道德和法律法规
在爬虫开发过程中,要遵守相关道德和法律法规,尊重网站版权和数据隐私,避免过度爬取和滥用数据,要合理使用爬虫技术,为互联网的发展做出贡献,Python爬虫入门并不难,只要掌握了基本知识和技巧,就能轻松实现数据抓取和分析,在实际应用中,还需要不断学习和探索更多高级技巧和工具,以应对日益复杂的网络环境和数据需求。
“python3爬虫入门教程,Python 3 爬虫实战入门指南” 的相关文章

c语言基础知识入门书籍推荐,C语言入门必读,经典书籍推荐指南
《C语言程序设计》是一本适合初学者的C语言入门书籍,由谭浩强编写,书中详细介绍了C语言的基础语法、数据类型、运算符、控制结构、函数等基本概念,并通过丰富的实例帮助读者理解和掌握C语言编程,该书语言通俗易懂,适合自学和作为大学计算机专业教材使用。C语言基础知识入门书籍推荐——开启编程之旅 作为一名编...

七牛云app,七牛云——云端存储与分享新体验
七牛云App是一款基于七牛云存储服务的移动应用,提供文件上传、下载、管理等功能,用户可通过App便捷地访问和操作云存储空间,支持图片、视频、文档等多种文件类型,App还具备实时同步、团队协作、数据备份等功能,旨在为用户提供安全、高效、便捷的云端存储体验。七牛云APP——我的云存储利器 作为一名普通...

checkbox怎么用,轻松掌握,checkbox的使用方法详解
checkbox,即复选框,是一种常见的网页和应用程序用户界面元素,用于选择一个或多个选项,使用方法如下:,1. **创建复选框**:在HTML中,使用`标签创建一个复选框。,2. **添加标签**:为每个复选框添加一个描述性的标签,以帮助用户理解其功能。,3. **绑定逻辑**:通过JavaScr...
用手机免费制作app软件,手机免费打造个性化App神器
介绍了一种利用手机免费制作APP软件的方法,通过这款应用,用户无需编程知识,只需简单操作即可创建个性化APP,软件提供丰富的模板和功能模块,支持图片、文字、视频等多种元素,用户可轻松定制界面和功能,制作完成后,APP可直接上传至各大应用市场,实现免费分发,此方法为有志于开发APP的个人和企业提供了便...

程序员前端和后端区别,前端与后端程序员,角色与技能差异解析
程序员前端和后端工作职责有显著差异,前端程序员主要负责网站或应用的界面设计、用户交互和网页开发,使用HTML、CSS、JavaScript等技术实现用户界面,后端程序员则专注于服务器、数据库和应用程序逻辑,使用如Python、Java、PHP等编程语言构建服务器端程序,处理数据存储、安全性和业务逻辑...

insert键在哪里笔记本,笔记本键盘上insert键的位置
在笔记本电脑上,通常的“Insert”键位于键盘的右上角,靠近数字键区,如果你找不到,可以尝试查看键盘布局图或者在网上搜索你笔记本型号的键盘布局图来确认位置,如果你的键盘布局是分区的,可能需要切换到数字锁定模式(Num Lock)来显示“Insert”键。“insert键在哪里笔记本?”——深度解析...
- 最新发布
-

5分钟前
12分钟前
15分钟前
23分钟前

30分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言