爬虫程序流程图,网络爬虫程序流程解析图
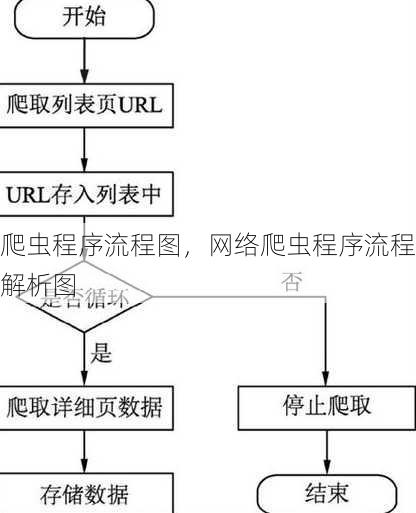
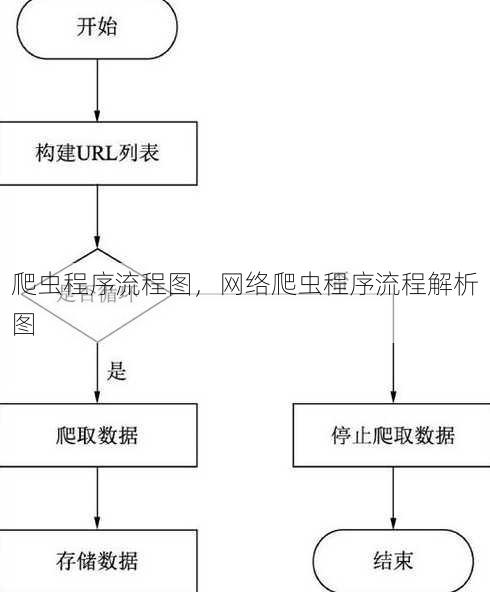
爬虫程序流程图通常包括以下步骤:1. 确定目标网站和爬取内容;2. 分析网站结构,获取URL和页面元素;3. 发送HTTP请求,获取网页内容;4. 解析网页内容,提取所需数据;5. 数据存储,如存入数据库或文件;6. 处理异常,如网络错误、页面结构变化等;7. 优化爬虫策略,如设置延迟、遵守robots.txt等,整个流程旨在高效、稳定地获取互联网上的信息。
我想了解爬虫程序的流程,能给我画个流程图吗?
解答:当然可以,爬虫程序的主要流程可以分为以下几个关键步骤:
-
目标网站分析:首先需要确定爬取的目标网站,并对其进行分析,了解网站的架构、数据存储方式以及访问限制等。
-
请求发送:根据分析结果,使用HTTP请求发送器向目标网站发送请求,获取网页内容。 解析**:使用解析库(如BeautifulSoup、lxml等)对获取到的网页内容进行解析,提取所需的数据。
-
数据存储:将提取的数据存储到数据库或其他存储介质中。
-
异常处理:在爬取过程中,可能会遇到各种异常情况,如网络错误、页面结构变化等,需要对这些异常进行妥善处理。
我将从以下几个详细解析爬虫程序的流程:
一:目标网站分析
- 确定目标页面:明确需要爬取的具体页面,如商品列表页、文章详情页等。
- 分析页面结构:查看页面源代码,了解页面元素的组织方式和数据存储位置。
- 识别数据特征:分析页面数据的特点,如是否为动态加载、数据格式等。
- 检查访问限制:了解网站的robots.txt文件,避免违反网站规则。
- 模拟浏览器行为:如果需要模拟登录或其他需要验证的操作,需了解并模拟浏览器的行为。
二:请求发送
- 选择请求方法:根据需求选择GET或POST请求方法。
- 设置请求头:模仿浏览器行为,设置合适的请求头,如User-Agent、Referer等。
- 处理Cookies:如果需要登录或其他验证,需要处理Cookies。
- 设置请求参数:对于GET请求,需要设置URL参数;对于POST请求,需要设置表单数据。
- 使用代理:如果需要绕过IP限制,可以使用代理服务器。
三:内容解析
- 选择解析库:根据实际情况选择合适的解析库,如BeautifulSoup、lxml等。
- 定位目标元素:使用选择器定位目标元素,如class、id、xpath等。
- 提取数据:从定位到的元素中提取所需数据,如文本、图片链接等。
- 处理数据格式:对提取的数据进行格式化处理,如去除空格、编码转换等。
- 递归解析:对于需要进一步解析的子页面,进行递归解析。
四:数据存储
- 选择存储方式:根据数据量和需求选择合适的存储方式,如数据库、文件等。
- 设计数据结构:根据数据特点设计合适的数据结构,如表格、JSON等。
- 批量插入数据:将提取的数据批量插入到存储介质中。
- 数据清洗:对存储的数据进行清洗,如去除重复、错误数据等。
- 数据备份:定期对数据进行备份,防止数据丢失。
五:异常处理
- 网络异常:处理网络请求失败、超时等情况。
- 解析异常:处理解析错误、元素定位失败等情况。
- 数据库异常:处理数据库连接失败、插入错误等情况。
- 重试机制:在遇到异常时,设置重试机制,提高爬取成功率。
- 日志记录:记录爬取过程中的关键信息,便于问题排查。
通过以上解析,相信您对爬虫程序的流程有了更深入的了解,在实际操作中,根据具体需求调整流程,才能更好地完成爬取任务。
其他相关扩展阅读资料参考文献:
-
需求分析与目标设定
- 明确目标:在设计爬虫流程图前,必须清晰界定采集目的,例如获取特定网站的新闻数据、商品价格或用户评论,避免盲目抓取导致资源浪费。
- 选择数据源:根据目标筛选目标网站,需分析网站结构、数据更新频率及合法性,确保爬虫范围符合实际需求且不违反服务条款。
- 制定采集规则:定义爬虫的采集频率、页面范围及数据字段,例如通过XPath或CSS选择器提取关键信息,为后续流程提供明确指引。
-
技术选型与架构设计
- 选择编程语言:Python因丰富的库(如Requests、BeautifulSoup、Scrapy)成为主流,其简洁语法和高效性能适合构建复杂爬虫流程图。
- 框架与工具匹配:根据项目规模选择框架,Scrapy适合大规模分布式爬虫,而Requests+BeautifulSoup适合小型单机任务,需在流程图中体现技术栈的合理性。
- 架构分层设计:将爬虫流程分为请求模块、解析模块、存储模块,通过模块化设计提升代码可维护性,例如使用异步请求优化效率。
-
数据采集与解析
- 发送HTTP请求:爬虫流程图需包含请求生成、参数设置、请求发送三个步骤,通过GET/POST方法获取网页原始数据,需注意请求头的伪装以规避反爬。
- 解析响应内容:利用正则表达式或解析库(如lxml)提取HTML中的有效数据,流程图中需标注标签定位、数据提取、异常处理等关键节点。
- 处理反爬机制:针对目标网站的验证码、IP封锁等防御措施,流程图需设计动态代理切换、请求频率控制、用户行为模拟等应对策略。
-
数据存储与处理
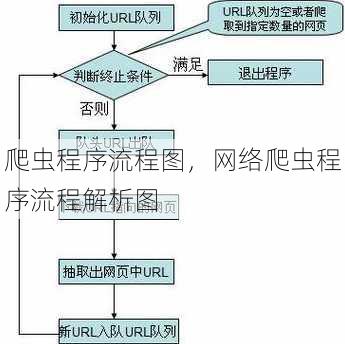
- 存储方式选择:根据数据类型选择存储方案,结构化数据(如数据库)适合MySQL或MongoDB,非结构化数据(如文本)可存储于本地文件或云存储服务。
- 数据清洗与转换:流程图需包含去重逻辑、格式标准化、数据校验等步骤,例如去除HTML标签、统一时间格式、验证数据完整性。
- 增量更新策略:通过时间戳或数据库主键实现数据更新,流程图需设计版本控制、差异对比、数据合并等环节,避免重复存储和资源浪费。
-
部署与维护
- 自动化部署流程:使用Docker容器化部署爬虫程序,流程图需标注环境配置、服务启动、日志记录等步骤,确保部署过程可追溯且高效。
- 监控与报警机制:在流程图中集成运行状态监控、异常日志分析、任务失败重试功能,例如通过Prometheus监控请求成功率,及时发现并修复问题。
- 持续更新与优化:定期更新流程图中的反爬策略、解析规则、存储结构,例如根据网站结构变化调整XPath路径,或优化数据库索引提升查询效率。
流程图的核心价值
爬虫程序流程图不仅是技术实现的蓝图,更是项目管理的工具,通过可视化流程,团队可快速理解任务分工,例如开发人员负责请求与解析模块,运维人员管理部署与监控环节,流程图能帮助识别潜在风险,如IP被封禁或数据源变更,提前制定应对方案,流程图还能作为文档模板,为后续维护提供清晰的参考依据,例如标注数据清洗规则或反爬策略的更新周期。
实际应用中的关键细节
- 动态调整采集频率:在流程图中设置定时任务和限速机制,例如使用APScheduler定时执行,或通过Sleep函数控制请求间隔,避免触发网站的流量限制。
- 处理多线程与分布式:对于大规模数据采集,流程图需设计任务分发、线程池管理、结果汇总等模块,例如使用Scrapy的分布式框架或Celery任务队列提升效率。
- 日志与调试支持:在流程图中嵌入日志记录节点,标注关键操作(如请求成功/失败、数据提取数量),便于问题排查和性能分析。
- 数据安全与合规性:确保流程图包含数据脱敏、权限控制、法律审查等环节,例如对敏感信息进行加密存储,或通过代理IP池避免泄露用户身份。
- 资源管理与成本控制:在流程图中体现内存优化、CPU利用率监控、云服务成本核算,例如使用缓存技术减少重复请求,或选择按需付费的云服务方案。
流程图的优化方向
- 模块化设计:将爬虫流程拆分为独立模块(如请求、解析、存储),便于功能扩展和团队协作,例如新增数据源时仅需调整解析模块。
- 可视化工具选择:使用Mermaid、Draw.io或Visio等工具绘制流程图,确保图表清晰易懂,例如通过颜色区分不同模块(如红色标注高风险节点)。
- 版本迭代管理:为流程图设置版本号,记录每次修改的技术选型变更、规则调整、性能优化,便于回溯和对比。
- 异常处理流程:在流程图中设计错误重试、失败告警、数据回滚等分支,例如当请求失败时自动切换代理IP或发送告警邮件。
- 性能瓶颈分析:通过流程图标注耗时最长的步骤(如解析或存储),针对性优化,例如使用异步IO提升请求效率,或优化数据库索引减少查询时间。
爬虫程序流程图是确保项目高效执行的关键工具,其设计需兼顾技术实现与业务需求,通过明确目标、合理选型、模块化分层、动态调整策略及持续优化,团队能够构建稳定、可扩展的爬虫系统。流程图的可视化不仅提升了开发效率,还为后续维护和团队协作提供了清晰的框架,是爬虫项目成功的基础保障。
“爬虫程序流程图,网络爬虫程序流程解析图” 的相关文章

cssci论文是什么级别,CSSCI论文,学术界的黄金标准
CSSCI(中国社会科学引文索引)论文是中国学术界公认的权威学术期刊论文,代表着国内社会科学领域的研究水平,CSSCI论文通常具有较高的学术质量和影响力,被广泛应用于学术研究和学术评价中,在学术界,CSSCI论文被视为高级别、高质量的学术成果,其发表意味着论文具有较高的学术价值和认可度。 嗨,我最...

str,探索神秘代码背后的秘密,揭秘STR的奥秘
探索神秘代码背后的秘密,本文深入揭秘STR的奥秘,通过解析STR代码的构成、功能及应用,揭示其在科技领域的广泛应用,为读者带来一场揭秘之旅,跟随文章,一起揭开STR的神秘面纱,感受科技的魅力。理解字符串(str)** 用户解答: 嗨,我是小王,最近在学习编程,遇到了一些关于字符串的问题,我想了解...
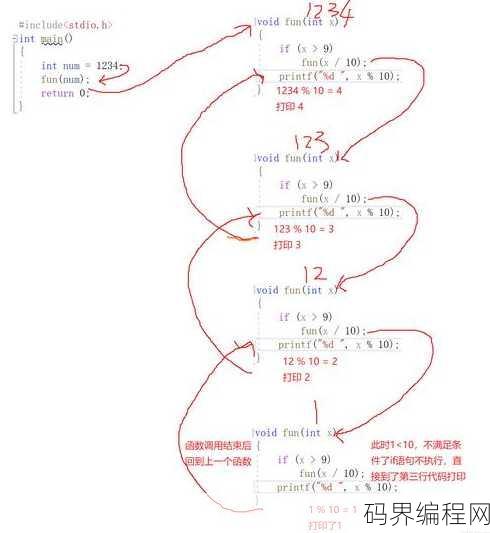
函数递归调用例子,,函数递归调用实例解析
函数递归调用是一种编程技巧,其中函数在执行过程中调用自身,这种调用可以解决许多问题,如阶乘计算、斐波那契数列生成等,递归函数包含一个或多个递归调用,直到满足终止条件,递归可以简化代码,但需要注意避免栈溢出和确保正确的终止条件,以下是一个简单的递归函数示例,用于计算阶乘:``python,def fa...
html5官网电脑版下载,HTML5官方电脑版下载指南
HTML5官网电脑版下载摘要:,欢迎访问HTML5官网,这里提供HTML5电脑版下载服务,下载后,您将获得最新版本的HTML5标准文档和资源,便于学习和开发,请访问官网,按照指示下载适合您操作系统的HTML5电脑版软件,开始您的HTML5之旅。HTML5官网电脑版下载全攻略 作为一名热衷于学习新技...

java核心技术目录,Java核心技术目录解析
《Java核心技术》目录摘要:,本书分为两卷,共二十六章,涵盖了Java编程语言的核心知识,第一卷主要介绍了Java语言基础,包括语法、数据类型、控制结构、数组、字符串处理等;第二卷深入探讨了面向对象编程、异常处理、泛型编程、集合框架、输入输出流、网络编程、多线程编程等高级主题,还介绍了Java新特...
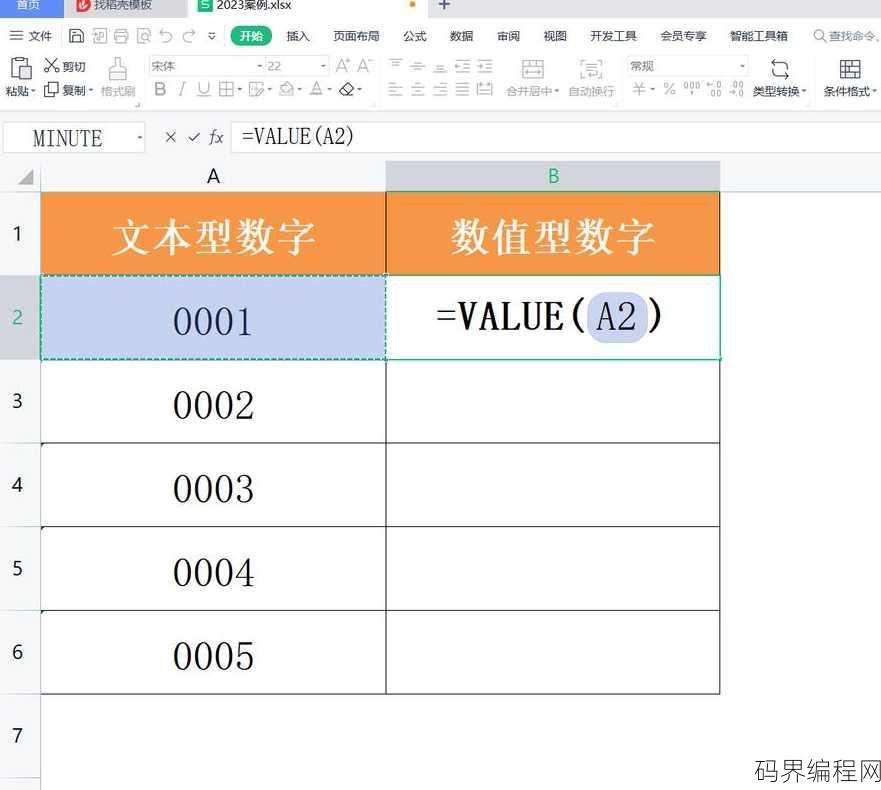
value函数是文本函数吗,Value函数在Excel中是文本处理函数吗?
Value函数不是文本函数,它是一种用于获取单元格中值的函数,在Excel等电子表格软件中,Value函数可以将文本转换为数值,或者从公式中提取数值结果,与文本函数如Concat、Left、Right等不同,Value函数主要用于数值计算和数据提取。Value函数是文本函数吗? 用户解答: 嗨,...
- 最新发布
-

5分钟前

19分钟前
23分钟前

30分钟前

37分钟前
- 热门阅读
-

934 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言