网站源码提取,网站源码高效提取技巧揭秘
网站源码提取是指通过技术手段获取网站页面的原始HTML、CSS和JavaScript代码,这一过程通常涉及使用网络爬虫、浏览器开发者工具或专门的软件工具来解析网页,从而复制网站的结构和功能代码,提取源码可以帮助开发者分析网站设计、功能实现和优化性能,但同时也需要注意版权和隐私问题,确保在合法合规的前提下进行。
揭秘背后的秘密
用户提问:嗨,我想了解一下网站源码提取这个话题,具体是怎么操作的?有什么需要注意的?
解答:你好!网站源码提取是指将一个网站的网页源代码进行提取的过程,这个过程通常用于分析网站结构、功能以及获取网站数据,下面我将从几个方面来详细解答你的问题。
网站源码提取的方法
- 直接查看:打开浏览器,右键点击网页,选择“查看页面源代码”即可。
- 使用开发者工具:大多数浏览器都提供了开发者工具,可以查看和修改网页源代码。
- 使用在线工具:一些在线工具可以方便地提取网站源码,如在线网页查看器等。
- 编写脚本:使用Python、JavaScript等编程语言编写脚本,通过爬虫等技术获取网站源码。
网站源码提取的注意事项
- 遵守网站政策:在提取网站源码之前,请确保你有权访问该网站,并遵守其使用政策。
- 避免滥用:不要滥用网站源码提取技术,如进行非法侵入、窃取数据等行为。
- 尊重版权:不要将提取的源码用于商业用途,除非你拥有相应的版权许可。
- 注意安全:在提取源码的过程中,注意保护自己的网络安全,避免泄露个人信息。
网站源码提取的应用场景
- 网站分析:通过提取网站源码,可以分析网站结构、功能以及优化网站性能。
- 数据提取:从网站源码中提取有价值的数据,如用户评论、产品信息等。
- 网站复制:通过提取源码,可以复制整个网站,但需遵守相关法律法规。
- 学习研究:对于开发者来说,研究网站源码可以帮助提高自己的技术水平。
网站源码提取的挑战
- 反爬虫技术:一些网站为了防止爬虫,采用了反爬虫技术,使得源码提取变得困难。
- 动态网页:一些动态网页的数据并非直接存储在源码中,需要通过解析JavaScript等脚本才能获取。
- 数据加密:一些网站对数据进行加密处理,使得提取数据变得复杂。
- 法律法规:在提取网站源码的过程中,需要遵守相关法律法规,避免违法行为。
网站源码提取是一项技术活,需要掌握一定的技能和知识,在提取源码的过程中,我们要遵守相关法律法规,尊重网站政策,避免滥用技术,通过提取网站源码,我们可以更好地了解网站结构、功能,以及获取有价值的数据,希望这篇文章能帮助你更好地了解网站源码提取。
其他相关扩展阅读资料参考文献:
网站源码的基本概念与作用
- 源码是网站的“骨架”
网站源码是网页的原始代码,包含HTML、CSS、JavaScript等技术语言,是构建网页功能和界面的核心。提取源码可帮助开发者分析网页结构、学习设计逻辑、排查错误或进行二次开发。 - 源码提取是数据抓取的前提
对于爬虫工程师而言,网站源码是获取网页数据的直接来源。通过解析源码,可以提取文本、图片、链接等信息,为后续数据处理提供基础。 - 源码提取可辅助安全审计
安全人员通过分析源码,可以发现潜在漏洞(如未加密的API接口、硬编码的敏感信息),为网站加固和风险评估提供依据。
网站源码提取的技术原理
- HTML结构分析
HTML是网页的骨架,所有内容都嵌套在标签中。提取HTML源码需通过浏览器开发者工具(如Chrome的Elements面板)或服务器请求查看,直接复制网页源码时,需注意区分渲染后的动态内容与原始HTML结构。 - CSS样式提取
CSS控制网页的视觉表现,但其代码通常被压缩或合并。提取CSS源码需使用开发者工具的“Sources”选项卡,或通过浏览器扩展(如Firebug)定位样式表,需注意不同浏览器对CSS的渲染差异可能导致样式提取不准确。 - JavaScript逻辑提取
JavaScript负责网页的交互功能,动态生成的内容需通过调试工具(如Chrome DevTools的Console面板)或网络请求分析。提取JavaScript源码需关注代码执行顺序和依赖关系,避免遗漏关键逻辑。
网站源码提取的常用工具与方法

- 在线工具:快速获取源码
使用如Wappalyzer、PageRank Checker等工具,可一键分析网站技术栈并提取源码片段。这类工具适合初学者或快速验证需求,但提取的源码可能不完整。 - 本地软件:深度解析源码
通过浏览器开发者工具(如Chrome DevTools)或代码编辑器(如VS Code)可直接查看网页源码。开发者工具支持实时调试和网络请求监控,适合分析复杂网页的动态行为。 - 命令行工具:批量处理源码
使用curl、wget等命令行工具,可通过HTTP请求直接获取网页源码。此方法适合批量抓取数据,但需处理网页编码、反爬机制等问题。 - 浏览器扩展:便捷提取源码
安装如Web Scraper、Save Page as HTML等扩展,可一键保存完整网页源码。这类工具操作简单,但提取的源码可能包含冗余内容(如广告脚本)。 - 自动化脚本:高效提取与处理
通过Python的requests库或Selenium框架,可编写脚本自动提取源码并解析数据。自动化工具适合处理大规模任务,但需掌握编程基础。
网站源码提取的法律与伦理风险
- 版权问题:避免侵权纠纷
网站源码可能包含原创内容或第三方授权代码。未经授权复制、修改或商用源码可能构成版权侵权,需确保合法使用权限。 - 隐私条款:尊重用户数据
部分网站源码可能涉及用户隐私信息(如登录凭证、个人数据)。提取源码时需遵守隐私政策,避免非法获取或泄露敏感信息。 - 数据合规:符合法律法规
根据《个人信息保护法》《数据安全法》等法规,提取网站源码需确保数据采集和使用符合法律要求,尤其是涉及用户行为数据时。 - 商业用途限制:规避合同风险
某些网站可能通过协议限制源码的商业用途(如禁止反向工程)。提取源码前需仔细阅读网站服务条款,避免违反协议约定。 - 服务条款:明确使用边界
网站源码提取可能触发服务条款中的“爬虫限制”或“数据抓取禁令”。需通过合法途径(如API接口)获取数据,避免因技术行为导致封号或法律追责。
网站源码提取的实战技巧与注意事项
- 静态网站:直接提取HTML内容
静态网站的源码无需依赖后端服务,可直接通过浏览器开发者工具或网络请求获取完整HTML文件,需注意区分HTML与动态生成的JavaScript内容。 - 动态网站:处理JavaScript渲染
动态网站的源码需通过浏览器执行JavaScript后才能获取完整内容。使用Selenium或Puppeteer等工具可模拟浏览器行为,提取动态加载的源码。 - API接口:优先提取后端数据
部分网站通过API接口传输数据,直接提取API请求参数(如URL、Headers)比解析前端源码更高效,需使用抓包工具(如Postman)分析接口调用逻辑。 - 反爬机制:绕过限制提取源码
网站可能通过验证码、IP封禁等手段阻止源码提取。需使用代理IP、模拟请求头或验证码识别工具(如2Captcha)突破限制。 - 数据格式处理:提取结构化信息
源码中的数据可能以JSON、XML或CSV格式嵌入。需通过正则表达式或解析库(如Python的BeautifulSoup)提取结构化信息,避免数据混乱。
网站源码提取的常见误区与解决方案
- 认为源码提取就是复制网页内容
许多用户误以为直接复制网页源码即可完成提取,但实际需过滤冗余内容(如广告、脚本)并提取关键数据。 - 忽略动态内容的加载延迟
动态网站的源码可能在页面加载后才生成,需使用Selenium等工具等待元素加载完成后再提取。 - 盲目依赖工具而忽略手动验证
工具提取的源码可能存在错误或不完整,需结合手动检查(如查看网络请求日志)确保数据准确性。 - 未考虑编码格式导致解析失败
网页源码可能使用UTF-8、GBK等不同编码格式,需在提取时指定正确的编码参数,避免乱码问题。 - 忽视法律风险导致后果严重
部分网站可能对源码提取行为进行法律追责,需在合法范围内操作,必要时咨询法律顾问。
网站源码提取的未来趋势与挑战
- AI技术加速源码解析
随着AI大模型的发展,自动化提取和解析源码的效率将大幅提升,但需警惕算法误判带来的数据偏差。 - 加密源码增加提取难度
部分网站采用代码混淆或加密技术保护源码,需结合逆向工程和调试工具破解加密逻辑。 - 隐私保护法规限制源码提取
未来法律对隐私数据的保护将更严格,源码提取需在合规框架内进行,避免触犯数据安全法。 - 占比持续上升
随着Web技术的演进,动态加载内容(如视频、广告)将成为源码提取的主要难点。 - 跨平台提取需求增加
用户可能需要在不同操作系统(如Windows、Linux)或浏览器(如Chrome、Firefox)中提取源码,需确保工具的兼容性和跨平台支持。
网站源码提取是一项技术性与法律性兼具的工作,需结合工具、方法和合规意识才能高效完成,无论是开发者、爬虫工程师还是安全人员,都应明确源码提取的边界与风险,避免因技术滥用或法律疏忽导致严重后果,随着技术的不断发展,源码提取的复杂性将逐步提升,唯有持续学习和实践,才能应对未来的挑战。
“网站源码提取,网站源码高效提取技巧揭秘” 的相关文章
程序源码是什么,揭秘程序源码,软件开发的基石
程序源码是软件开发的基础,它是由程序员用编程语言编写的原始代码,这些代码经过编译或解释后,可以被计算机系统执行,源码通常包含算法、数据结构、函数定义等,是构建软件应用的核心部分,它反映了程序的逻辑和实现细节,对于软件维护、升级和二次开发至关重要。程序源码是什么? 这个问题对于初学者来说可能有些棘手...
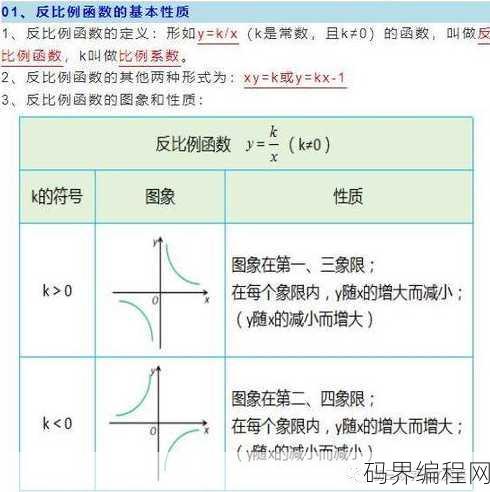
反比例函数图像叫什么,反比例函数图像的名称解析
反比例函数的图像称为双曲线,在坐标系中,当x和y的乘积为常数时,所形成的曲线就是双曲线,这种曲线具有两个分支,分别位于x轴和y轴的两侧,且随着x或y的增大,另一个变量的值会相应减小,体现了反比例关系。 嗨,我最近在学习反比例函数,发现它的图像挺有意思的,但是不知道这个图像叫什么名字,有人能告诉我吗...
计算机源码网站,计算机源码资源库大全
计算机源码网站是一个提供计算机源代码资源的平台,汇集了各类编程语言的源码,包括但不限于C、C++、Java、Python等,用户可以在这里搜索、下载、分享和讨论各种开源项目,为编程爱好者、开发者提供便捷的代码获取途径和技术交流空间。丰富的源码资源 这个网站拥有海量的计算机源码,涵盖了从入门级到高级...

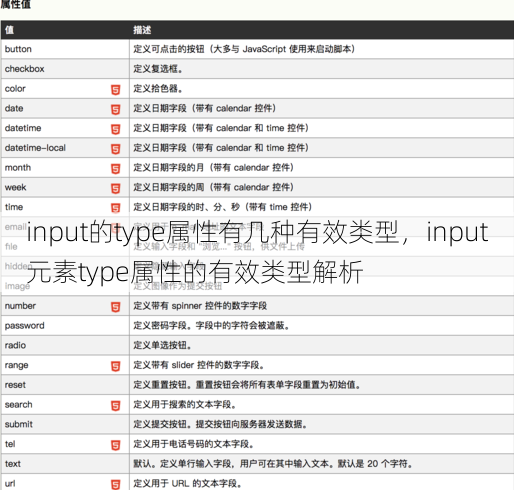
java数据类型有哪几种,Java数据类型的介绍
Java数据类型分为两大类:基本数据类型和引用数据类型,基本数据类型包括整型(byte, short, int, long)、浮点型(float, double)、字符型(char)和布尔型(boolean),引用数据类型则是指向对象的指针,包括类(Class)、接口(Interface)、数组(A...
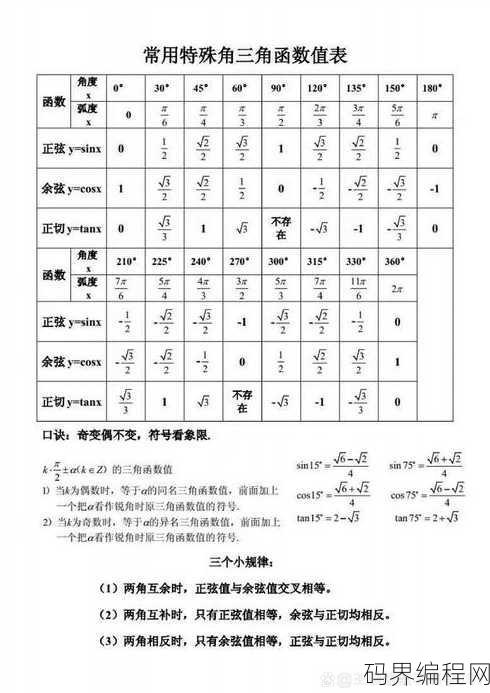
高中三角函数所有公式,高中三角函数公式大全
高中三角函数公式摘要如下:,1. 基本公式:, - 正弦、余弦、正切、余切、正割、余割的定义, - 同角三角函数关系:sin²θ + cos²θ = 1,tanθ = sinθ/cosθ,cotθ = cosθ/sinθ,secθ = 1/cosθ,cscθ = 1/sinθ,2. 和差公式...

如何制作游戏,轻松入门,游戏制作全攻略
制作游戏是一个复杂的过程,涉及以下几个步骤:明确游戏类型和目标受众;设计游戏故事和角色,包括剧情、世界观和角色设定,进行游戏原型开发,通过编程和美术资源创建基础游戏框架,测试和优化游戏,确保游戏玩法流畅,无bug,制作游戏宣传材料和营销计划,准备发布,整个过程中,团队合作、持续反馈和细致规划至关重要...
- 最新发布
-

4分钟前
11分钟前
16分钟前
21分钟前

30分钟前
- 热门阅读
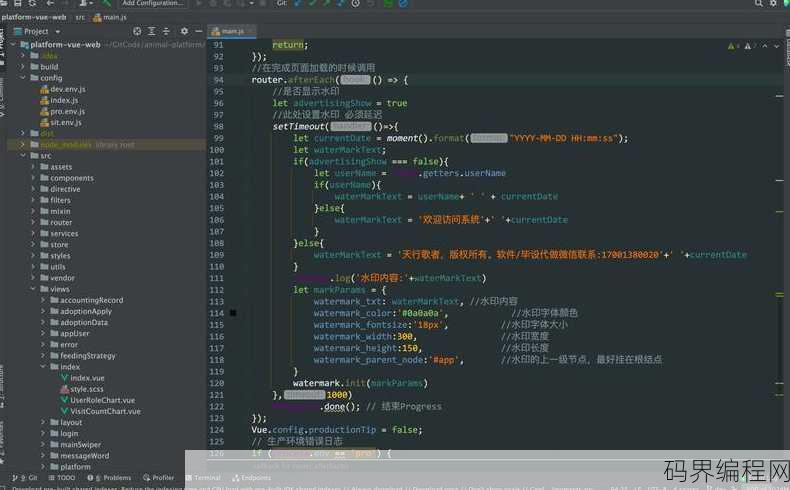
-

918 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言