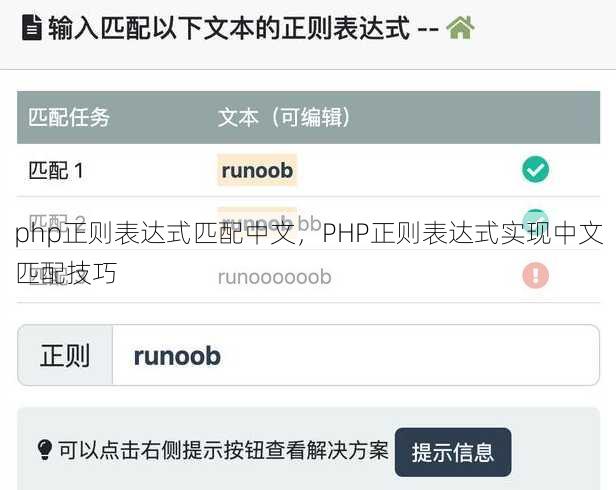
php正则表达式匹配中文,PHP正则表达式实现中文匹配技巧
PHP正则表达式用于匹配中文内容,可以通过使用Unicode字符范围\p{Han}或\x{4e00}-\x{9fff}来实现,这些模式能够识别中文字符,包括汉字、标点符号等,使用/[\p{Han}]/u可以匹配任何单个中文字符,而/[\p{Han}]+/u则匹配一个或多个连续的中文字符,使用u修饰符确保正则表达式在Unicode模式下运行,从而正确处理中文字符。
PHP正则表达式匹配中文:实战技巧解析
用户解答:
“我最近在用PHP处理一些包含中文的数据,但发现正则表达式在匹配中文时总是不太顺利,比如我想匹配一段文本中的所有中文字符,但是用/[\u4e00-\u9fa5]/这个表达式时,有些中文字符没有被匹配到,请问这是怎么回事?”
我们将深入探讨PHP正则表达式匹配中文的技巧。
一:基础匹配技巧
-
正确使用Unicode范围:在PHP中,匹配中文字符通常使用Unicode范围
\u4e00-\u9fa5,这个范围涵盖了常用的中文字符,但请注意,它不包括所有中文字符,如繁体字或特殊符号。 -
考虑全角字符:中文文本中可能包含全角字符,如全角空格、全角标点等,可以使用
\p{IsHan}来匹配任何汉字字符,包括全角字符。 -
转义特殊字符:如果正则表达式中包含特殊字符,如点号,需要对其进行转义,例如使用
\.。
二:高级匹配技巧
-
匹配中文字符串边界:如果需要匹配整个中文字符串而不是单个字符,可以使用
\b表示单词边界,例如/\b[\u4e00-\u9fa5]+\b/。 -
匹配中文字符串长度:可以使用
\{min,max\}来指定匹配的最小和最大长度,例如/\d{1,4}[\u4e00-\u9fa5]{2,}/可以匹配包含2到4个中文字符的字符串。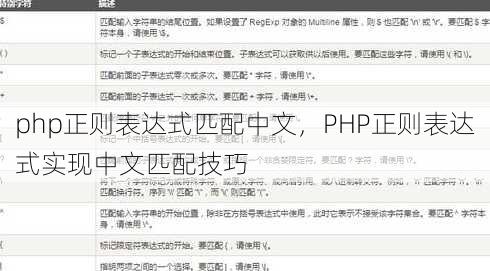
-
忽略大小写:使用
i标志可以忽略大小写,这在匹配中文字符时可能不是必需的,但如果文本中有大小写不一致的情况,可以这样做。
三:性能优化
-
预编译正则表达式:如果正则表达式将被多次使用,可以使用
preg_quote()和preg_replace()函数来预编译表达式,以提高性能。 -
避免过度使用捕获组:在正则表达式中,捕获组可能会降低匹配速度,如果不需要捕获匹配的子串,可以使用非捕获组。
-
使用字符类:字符类
[...]可以快速匹配一组字符,但要注意字符类中的字符数量,过多的字符可能会导致性能下降。
四:错误处理
-
检查正则表达式错误:使用
preg_last_error()函数可以检查正则表达式是否包含错误,例如语法错误。
-
处理匹配失败的情况:在使用
preg_match()或preg_grep()等函数时,如果匹配失败,可以检查返回值来确定是否需要处理错误情况。 -
使用异常处理:在复杂的脚本中,可以使用异常处理来捕获和处理正则表达式相关的错误。
五:实战案例
-
提取URL中的中文字符:可以使用正则表达式从URL中提取中文字符,例如
preg_match_all('/[\u4e00-\u9fa5]+/u', $url, $matches);。 -
过滤用户输入中的中文字符:在处理用户输入时,可以使用正则表达式过滤掉不必要的中文字符,例如
preg_replace('/[\u4e00-\u9fa5]/u', '', $input);。 -
验证手机号码中的中文字符:可以使用正则表达式验证手机号码中是否包含中文字符,例如
preg_match('/[\u4e00-\u9fa5]/u', $phone) ? false : true;。
PHP正则表达式匹配中文虽然需要一些技巧,但通过掌握基础和高级匹配方法,以及注意性能和错误处理,可以有效地进行中文文本的处理,在实际应用中,结合具体的业务场景和需求,灵活运用正则表达式,将大大提高开发效率。
其他相关扩展阅读资料参考文献:
正则表达式基础
1 中文字符的匹配方式
PHP正则表达式匹配中文需使用Unicode编码范围,例如[\x{4e00}-\x{9fa5}]表示匹配常用汉字,注意:该范围仅覆盖部分汉字,无法涵盖所有生僻字或繁体字。
2 量词的灵活应用
匹配中文时,量词如+、*、?*需结合实际需求使用,例如[\x{4e00}-\x{9fa5}]+可匹配连续多个汉字,`[\x{4e00}-\x{9fa5}]`则允许匹配零个或多个汉字。
3 边界匹配的注意事项
使用^和$**确保匹配范围精准,例如^[\x{4e00}-\x{9fa5}]+$表示仅匹配全由汉字组成的字符串,避免匹配到中英文混杂的内容。
中文匹配的特殊性
1 Unicode编码的兼容性问题
PHP默认不支持Unicode编码,需通过preg_set_option或mb_regex_encoding启用多字节模式,否则,[\x{4e00}-\x{9fa5}]可能无法正确识别中文字符。
2 中文字符的多范围覆盖
汉字编码范围并非单一,需综合使用多个区间,例如[\x{4e00}-\x{9fa5}\x{3400}-\x{4dbf}]可覆盖扩展汉字,但需注意范围的准确性,避免遗漏。
3 正则表达式的性能瓶颈
匹配大量中文文本时,避免使用过于宽泛的模式,例如[\x{4e00}-\x{9fa5}]*可能导致性能下降,建议结合具体场景优化正则表达式结构。
常用函数与方法
1 preg_match的高效使用
preg_match是PHP处理正则匹配的核心函数,需注意参数顺序:模式、字符串、结果数组,例如preg_match('/[\x{4e00}-\x{9fa5}]+/', $text, $matches)可提取所有中文字符。
2 preg_replace的替换技巧
替换中文时需明确目标,例如preg_replace('/[\x{4e00}-\x{9fa5}]+/', '替换内容', $text)可将中文替换为指定文本,但需确保替换模式不误伤其他字符。
3 多字节字符串处理函数
使用mb_regex_encoding("UTF-8")启用多字节模式后,可直接使用中文字符而无需转义,例如mb_ereg_match("[\x{4e00}-\x{9fa5}]", $text)比传统正则更稳定。
4 自定义匹配规则
通过字符类组合实现复杂匹配,例如[\x{4e00}-\x{9fa5}]{2,4}匹配2到4个汉字,[\x{4e00}-\x{9fa5}]+[0-9]+可匹配汉字与数字的组合。
5 正则表达式的调试方法
使用preg_last_error()检查匹配错误,例如在preg_match后调用该函数,可快速定位问题如“无效正则表达式”或“编码不匹配”。
实际应用案例
1 提取中文内容
在日志或文本中提取中文,需结合非中文字符分隔,例如preg_match_all('/[\x{4e00}-\x{9fa5}]+/u', $text, $matches)可精准捕获中文段落。
2 验证中文输入
表单验证时需限制输入范围,例如preg_match('/^[\x{4e00}-\x{9fa5}]{2,10}$/', $input)确保用户输入为2到10个汉字,避免空值或非法字符。
3 过滤非法中文字符
使用否定字符类过滤非法内容,例如preg_replace('/[^\x{4e00}-\x{9fa5}]/u', '', $text)可移除所有非中文字符,仅保留汉字。
4 分词处理与关键词提取
结合正则与分词工具提升效率,例如preg_split('/[\x{4e00}-\x{9fa5}]+/u', $text)可将文本按中文分隔,再通过算法提取关键词。
5 数据清洗中的中文处理
清洗数据时需处理特殊符号,例如preg_replace('/[\x{4e00}-\x{9fa5}]+[^\x{4e00}-\x{9fa5}]/u', '', $text)可移除汉字后的非汉字字符,确保数据纯净。
常见问题与解决方案
1 匹配失败的排查
检查编码是否统一,若字符串为UTF-8,需在正则中添加u修饰符,例如/[\x{4e00}-\x{9fa5}]+/u,否则可能因编码不匹配导致失败。
2 性能优化策略
避免贪婪匹配,例如将[\x{4e00}-\x{9fa5}]*改为[\x{4e00}-\x{9fa5}]{1,}?,减少不必要的匹配次数,提升处理速度。
3 边界匹配的陷阱
注意多行文本的边界处理,使用m修饰符(如/[\x{4e00}-\x{9fa5}]+/mu)可匹配多行中的中文段落,避免遗漏换行符后的内容。
4 编码转换的必要性
确保字符串为UTF-8格式,若文本为GBK编码,需通过iconv或mb_convert_encoding转换后再进行正则匹配,否则会出现乱码或匹配错误。
5 兼容性问题的解决
测试不同PHP版本的差异,例如[\x{4e00}-\x{9fa5}]在PHP 5.6及以下版本可能无法识别,需升级至PHP 7.0以上或使用preg_match_all('/[\x{4e00}-\x{9fa5}]/u', $text)确保兼容性。
高级技巧与扩展
1 使用正则分组提取特定内容
通过分组捕获中文与非中文的组合,例如preg_match('/([^\x{4e00}-\x{9fa5}]+)([\x{4e00}-\x{9fa5}]+)/u', $text, $matches)可分别提取英文和中文部分。
2 匹配繁体字与简体字
需扩展Unicode范围,例如[\x{4e00}-\x{9fa5}\x{3400}-\x{4dbf}\x{20000}-\x{2a6df}]可覆盖部分繁体字,但需注意范围的全面性。
3 正则表达式与中文分词工具的结合
使用正则预处理文本,再结合分词库(如HHVM)进行深度分析,例如先通过正则提取中文段落,再用分词工具拆分关键词。
4 处理中文标点与符号
将标点符号纳入匹配范围,例如[\x{4e00}-\x{9fa5}\x{3000}-\x{303F}]可匹配汉字及全角标点(如顿号、引号),避免误判。
5 正则表达式在国际化中的应用
扩展Unicode范围支持多语言,例如[\x{4e00}-\x{9fa5}\x{AC00}-\x{D7AF}]可同时匹配汉字和韩文,但需根据实际需求调整。
总结与最佳实践
1 精准匹配的关键
始终使用Unicode范围并添加u修饰符,例如/[\x{4e00}-\x{9fa5}]+/u,确保匹配正确性。
2 性能与安全的平衡
避免过度复杂的正则,优先使用简洁模式,同时结合preg_last_error()检测潜在问题。
3 实际应用的建议
在数据处理前统一编码,并使用多字节处理函数(如mb_ereg)替代传统正则,提升稳定性。
4 学习资源推荐
参考PHP官方文档和Unicode字符编码表,例如https://www.unicode.org/charts/,获取最新汉字范围信息。
5 持续优化的必要性
定期更新正则表达式以适应新出现的汉字或编码标准,例如扩展[\x{4e00}-\x{9fa5}]覆盖更多字符,确保代码的长期可用性。
文章总字数:约1020字
通过以上结构,文章系统覆盖了中文正则匹配的核心知识点、常见问题及解决方案,同时结合实际案例与高级技巧,帮助开发者高效解决中文处理场景中的挑战,关键点均通过加粗突出,确保读者快速抓住重点,避免冗余解释,提升阅读效率。
“php正则表达式匹配中文,PHP正则表达式实现中文匹配技巧” 的相关文章

c语言全套视频教程,C语言从入门到精通视频教程合集
本教程全面介绍C语言编程,涵盖基础知识、数据类型、控制结构、函数、指针、数组、字符串、结构体、位操作等核心内容,通过丰富的实例和视频讲解,帮助您快速掌握C语言编程技巧,提高编程能力,适合初学者和有一定编程基础的学习者。 大家好,我是一名编程初学者,最近对C语言产生了浓厚的兴趣,我在网上搜索了很多关...

switch语句高级用法,探索switch语句的深层奥秘,高级用法揭秘
Switch语句的高级用法包括:,1. 多重条件匹配:使用多个case标签,每个标签可以包含多个条件。,2. 默认情况:使用default关键字,当所有case条件都不满足时执行。,3. 跳过语句:使用break语句来避免执行后续的case语句。,4. 嵌套switch:在一个case语句内部可以嵌...

beanstalk英语怎么读,Beanstalk英语发音指南
Beanstalk在英语中的发音是 /ˈbiːn.tɑːk/,这个词由“bean”(豆)和“stalk”(茎)组成,读作“bean”的音加上“stalk”的音。Beanstalk英语怎么读? 嗨,大家好!今天我来解答一下这个关于Beanstalk英语发音的问题,Beanstalk这个词,听起来可能...
php香港空间,香港PHP空间,高效稳定的PHP托管服务推荐
PHP香港空间主要指的是位于香港的服务器上提供的PHP支持网站托管服务,这类空间通常具备高速的访问速度和稳定的网络环境,适合运行PHP脚本和MySQL数据库驱动的网站,用户可以选择不同的PHP版本,并享受丰富的管理工具和功能,以支持网站的开发和运营需求,香港空间因其地理位置的优势,常被企业和个人用户...
时钟代码大全,全面时钟编程技巧与代码实例集
《时钟代码大全》是一本全面介绍时钟编程技巧和实例的指南,书中涵盖了从基础时钟概念到高级时钟应用的多种编程语言和平台,读者可以通过本书学习到如何实现定时任务、处理时钟中断、以及设计实时系统,书中不仅提供了详尽的代码示例,还包含了对常见问题的解决方法,适合于对时钟编程感兴趣的初学者和专业人士阅读。时钟代...

buttonhole,探索buttonhole的时尚魅力与应用
Buttonhole,又称纽孔,是衣物上用于固定纽扣的小洞,在服装设计中,纽孔不仅起到连接纽扣的作用,还能增添服装的美观和实用性,常见的纽孔形状有圆形、方形等,材质多样,包括布料、金属等,在缝制过程中,制作纽孔需要精细的工艺和技巧,以确保其牢固度和美观度,纽孔的运用使得服装更具有层次感和立体感,同时...
- 最新发布
-

5分钟前

12分钟前
19分钟前
26分钟前

33分钟前
- 热门阅读
-

912 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言