frequency函数分组,频率函数在分组数据中的应用解析
频率函数分组通常指的是在数据分析中,根据某个变量的值将数据集划分为不同的组别,并计算每个组别中该变量的出现频率,这种方法可以帮助理解数据分布、识别模式或异常值,具体操作中,首先确定分组依据,然后使用频率函数(如Python中的pandas库中的value_counts()方法)对每个组别中的数据点计数,从而得到每个组别的频率分布,这种方法在市场分析、用户行为研究等领域应用广泛。
用户提问:我最近在使用Python的pandas库时,遇到了一个关于frequency函数分组的问题,我想知道如何使用frequency函数对数据进行分组,并且如何获取每个组的频率,请问有人能帮我解答一下吗?
解答:当然可以,在pandas中,我们可以使用groupby函数配合size方法来实现数据的分组和频率统计,下面我将从以下几个方面来详细解释:
一:分组依据
-
使用列名进行分组:你可以通过指定列名来对数据进行分组,假设你有一个包含“姓名”和“年龄”两列的DataFrame,你可以按照“姓名”列进行分组。
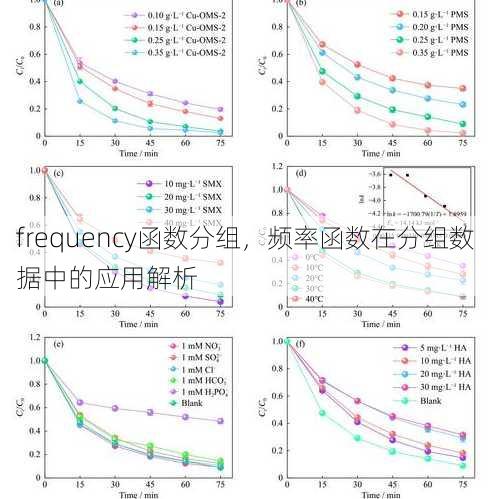
import pandas as pd data = {'姓名': ['张三', '李四', '张三', '李四', '王五'], '年龄': [25, 30, 25, 30, 35]} df = pd.DataFrame(data) grouped = df.groupby('姓名') print(grouped.size()) -
使用自定义函数进行分组:除了列名,你还可以使用自定义函数进行分组,你可以根据年龄的范围进行分组。
def age_group(age): if age < 30: return '青年' elif age < 40: return '中年' else: return '老年' grouped = df.groupby(age_group(df['年龄'])) print(grouped.size())
二:分组后的操作
-
计算分组后的统计量:在分组后,你可以使用
sum、mean、median等方法来计算分组后的统计量。print(grouped['年龄'].sum()) print(grouped['年龄'].mean()) print(grouped['年龄'].median())
-
分组后的数据透视表:你可以使用
pivot_table方法将分组后的数据转换为数据透视表。pivot_table = df.pivot_table(values='年龄', index='姓名', aggfunc='mean') print(pivot_table)
三:处理缺失值
-
分组前处理缺失值:在进行分组之前,你可以先处理缺失值,例如使用
dropna方法删除含有缺失值的行。df.dropna(inplace=True) grouped = df.groupby('姓名') print(grouped.size()) -
分组后处理缺失值:在分组后,你可以使用
fillna方法对缺失值进行填充。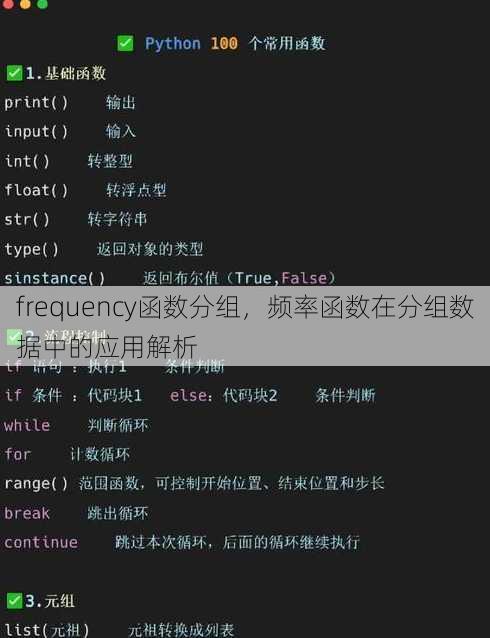
df['年龄'].fillna(df['年龄'].mean(), inplace=True) grouped = df.groupby('姓名') print(grouped.size())
四:分组后的可视化
-
柱状图:你可以使用matplotlib库来绘制分组后的柱状图。
import matplotlib.pyplot as plt grouped = df.groupby('姓名') for name, group in grouped: plt.bar(name, group['年龄'].mean()) plt.xlabel('姓名') plt.ylabel('年龄') plt.title('分组后的年龄分布') plt.show() -
饼图:你可以使用matplotlib库来绘制分组后的饼图。
import matplotlib.pyplot as plt grouped = df.groupby('姓名') for name, group in grouped: plt.pie(group['年龄'].value_counts(), labels=group['年龄'].value_counts().index, autopct='%1.1f%%') plt.xlabel('姓名') plt.ylabel('年龄') plt.title('分组后的年龄分布') plt.show()
五:注意事项
-
避免重复分组:在分组时,确保你的分组依据是唯一的,避免重复分组。
-
选择合适的分组依据:选择合适的分组依据可以帮助你更好地分析数据。
-
处理异常值:在进行分组之前,可以先对数据进行清洗,处理异常值。
通过以上几个方面的介绍,相信你已经对pandas中的frequency函数分组有了更深入的了解,希望这些内容能帮助你解决实际问题。
其他相关扩展阅读资料参考文献:
Frequency函数分组详解
Frequency函数的介绍
Frequency函数是数据分析中常用的函数之一,主要用于统计特定数据在指定区间内的出现次数,通过分组的方式,Frequency函数可以帮助我们更好地理解数据的分布情况,本文将围绕这一主题,从的角度深入探讨Frequency函数分组的应用和原理。
一:数据分组的重要性
- 数据分组的意义
- 提高数据可读性:通过将大量连续数据分组,可以更加清晰地展示数据的分布情况。
- 辅助决策分析:分组后的数据能够揭示数据的内在规律,为决策提供科学依据。
- 发现数据异常:通过对比不同组的数据,可以更容易地发现异常值。
Frequency函数在数据分组中的应用
- 自动分组功能:Frequency函数能够根据数据的分布情况自动进行分组,简化分组操作。
- 快速统计功能:能够快速计算每个分组内数据的出现次数,提高数据分析效率。
二:Frequency函数的使用方法
-
基本语法介绍
- Frequency函数的基本语法包括数据源、分组区间和输出范围等参数的设置。
- 设置时需注意数据源的有效性以及分组区间的合理性。
-
实际操作步骤
- 选定数据源并输入到Frequency函数的相应位置。
- 设置分组区间,确定数据的分组方式。
- 选择输出范围,查看分组统计结果。
-
常见使用技巧
- 利用辅助列进行预处理,使数据更适合Frequency函数的分组方式。
- 结合其他函数(如IF、COUNTIFS等)进行复杂分组统计。
三:Frequency函数的优化与拓展
-
优化数据处理效率
- 通过宏或VBA编程,实现自动化处理大量数据的Frequency函数分组。
- 利用数组公式,减少函数运算时的单元格引用次数,提高计算速度。
-
拓展应用场景
- 结合其他分析工具(如直方图、箱线图等),更直观地展示Frequency函数分组结果。
- 在金融、科学计算等领域应用Frequency函数进行数据分析与预测。
四:Frequency函数在实际案例中的应用
-
销售数据分析
- 利用Frequency函数分析各价格区间产品的销售数量分布,为定价策略提供依据。
- 分析不同时间段内的销售频率,预测销售趋势。
-
学生成绩分析
- 通过Frequency函数分析学生成绩的分布情况,评估教学质量。
- 分析不同教学方法对学生成绩的影响,优化教学策略。
通过本文的阐述,我们对Frequency函数分组的原理、重要性、使用方法、优化与拓展以及实际应用有了深入的了解,在实际工作和学习中,掌握Frequency函数的分组技巧将大大提高数据处理和分析的效率,为决策提供更科学的依据。
“frequency函数分组,频率函数在分组数据中的应用解析” 的相关文章
bootstrap已经过时了,Bootstrap框架,曾经的王者,如今的挑战者
Bootstrap作为一款曾经引领前端开发的框架,如今已逐渐显得过时,随着Web技术的快速发展,新的框架和库层出不穷,如React、Vue等,它们提供了更灵活、更高效的开发方式,虽然Bootstrap仍有一定市场,但其局限性逐渐凸显,开发者更倾向于选择更现代、更适应未来需求的解决方案。Bootstr...
sqrt函数用法python中,Python中sqrt函数的使用方法
Python中的sqrt函数用于计算一个数的平方根,通常使用math模块中的sqrt()函数,首先需要导入math模块,然后通过调用sqrt()函数并传入一个正数作为参数,即可得到该数的平方根,计算9的平方根,可以写作import math; result = math.sqrt(9),其中resu...

ssci,SSCI期刊研究进展与趋势分析
SSCI期刊研究进展与趋势分析主要聚焦于对社会科学领域内国际期刊的研究动态进行深入探讨,摘要指出,该分析回顾了近年来SSCI期刊在学术质量、研究主题、方法论等方面的变化,并预测了未来发展趋势,研究发现,跨学科研究日益增多,定量研究方法的应用逐渐普及,新兴领域如环境科学、数字人文等成为研究热点,国际化...

计算机c语言二级证书含金量,C语言二级证书的职场价值解析
计算机C语言二级证书含金量较高,它证明了持证人具备扎实的C语言编程基础和较强的编程能力,该证书在IT行业和软件开发领域广受认可,有助于求职者在众多竞争者中脱颖而出,提升就业竞争力,随着技术发展,证书的实际应用价值也在不断变化,持证人还需不断学习新知识,以适应行业需求。计算机C语言二级证书含金量:揭秘...

程序员招聘求职的网站,程序员专属招聘求职平台
这是一个专门针对程序员招聘和求职的网站,该平台汇集了丰富的职位信息,包括软件开发、系统架构、前端开发等多个领域,用户可以在这里发布简历、搜索职位、参与在线面试,同时也有企业招聘团队发布招聘需求,提供便捷的线上交流与匹配服务,助力程序员找到理想的工作机会。你的职业加速器 真实用户解答: 大家好,我...

幂函数底数能为0吗,幂函数底数为何不能为0?
幂函数的底数不能为0,在数学中,任何非零数的零次幂都等于1,但0的零次幂未定义,0作为底数会导致数学上的不稳定性,因为任何数的0次幂都应该是1,但如果底数是0,那么无论指数是多少,结果都是未定义的,为了保持数学的连贯性和一致性,幂函数的底数不能为0。作为一名数学爱好者,我经常在网络上看到关于幂函数底...
- 最新发布
-
3分钟前
10分钟前

13分钟前

21分钟前

28分钟前
- 热门阅读
-

912 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言