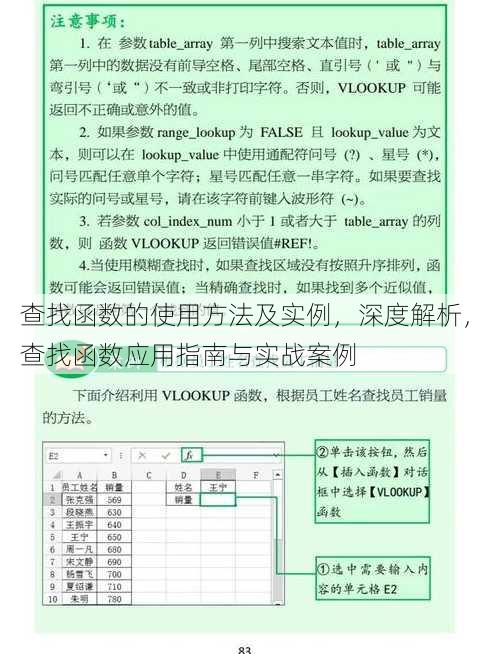
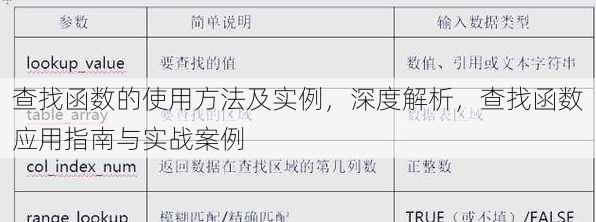
查找函数的使用方法及实例,深度解析,查找函数应用指南与实战案例
查找函数是一种在数据集合中定位特定元素的方法,其基本使用方法包括:首先定义一个数据集合,然后调用查找函数,传入数据集合和要查找的元素,函数会返回元素的位置或提示未找到,以下是一个简单的实例:,``python,def find_element(data, target):, for index, element in enumerate(data):, if element == target:, return index, return -1,# 示例数据,data_list = [10, 20, 30, 40, 50],# 查找元素,result = find_element(data_list, 30),# 输出结果,if result != -1:, print(f"元素 {30} 在列表中的位置是:{result}"),else:, print("元素未找到"),`,此实例中,查找函数find_element在列表data_list中查找元素30,返回其在列表中的位置,如果未找到,则返回-1`。
嗨,大家好!我最近在使用Python编程时遇到了一个问题,就是如何在大量的数据中快速找到某个特定的值,我的同事推荐我使用查找函数,但我对它的使用方法还不太熟悉,谁能帮我介绍一下查找函数的使用方法及一些实例呢?谢谢!
一:查找函数的基本概念
-
什么是查找函数? 查找函数是一种用于在数据集合中搜索特定值的函数,在编程中,查找函数可以帮助我们快速定位到所需的数据。

-
查找函数的类型 常见的查找函数包括线性查找、二分查找和哈希查找等,每种查找函数都有其适用的场景和特点。
-
查找函数的性能 查找函数的性能取决于数据集合的大小和查找算法的效率,哈希查找和二分查找比线性查找更高效。
二:线性查找的使用方法
-
线性查找的定义 线性查找是最简单的查找方法,它按照数据集合的顺序依次查找,直到找到目标值或遍历完整个集合。
-
线性查找的步骤
- 定义一个数据集合。
- 遍历数据集合中的每个元素。
- 比较当前元素与目标值。
- 如果找到目标值,返回其索引;否则,返回-1。
-
线性查找的实例
def linear_search(arr, target): for i in range(len(arr)): if arr[i] == target: return i return -1 data = [3, 5, 7, 9, 11] target = 7 result = linear_search(data, target) print("Index of target:", result) # 输出:Index of target: 2
三:二分查找的使用方法
-
二分查找的定义 二分查找是一种高效的查找算法,适用于有序数据集合,它通过不断缩小查找范围来快速定位目标值。
-
二分查找的步骤
- 确定数据集合的起始和结束索引。
- 计算中间索引。
- 比较中间值与目标值。
- 如果中间值等于目标值,返回中间索引。
- 如果中间值小于目标值,调整起始索引。
- 如果中间值大于目标值,调整结束索引。
- 重复步骤2-6,直到找到目标值或起始索引大于结束索引。
-
二分查找的实例
def binary_search(arr, target): left, right = 0, len(arr) - 1 while left <= right: mid = (left + right) // 2 if arr[mid] == target: return mid elif arr[mid] < target: left = mid + 1 else: right = mid - 1 return -1 data = [1, 3, 5, 7, 9, 11] target = 7 result = binary_search(data, target) print("Index of target:", result) # 输出:Index of target: 3
四:哈希查找的使用方法
-
哈希查找的定义 哈希查找是一种基于哈希表的查找方法,它通过计算目标值的哈希码来快速定位数据。
-
哈希查找的步骤
- 定义一个哈希函数,用于计算数据的哈希码。
- 使用哈希函数计算目标值的哈希码。
- 根据哈希码直接访问数据。
-
哈希查找的实例
def hash_search(hash_table, target): index = hash(target) % len(hash_table) return hash_table[index] hash_table = [None] * 10 hash_table[0] = 3 hash_table[1] = 5 hash_table[2] = 7 hash_table[3] = 9 hash_table[4] = 11 target = 7 result = hash_search(hash_table, target) print("Value at index:", result) # 输出:Value at index: 7
五:查找函数的选择与应用
-
选择合适的查找函数
- 对于小规模数据集合,线性查找和二分查找都适用。
- 对于大规模数据集合,哈希查找通常更高效。
- 对于有序数据集合,二分查找和哈希查找都适用;对于无序数据集合,线性查找更适用。
-
查找函数的应用场景
- 数据库查询:使用索引进行快速查找。
- 字典查找:使用哈希表实现快速查找。
- 排序算法:在排序过程中使用查找函数。
-
查找函数的优化
- 选择合适的查找算法和数据结构。
- 预处理数据,提高查找效率。
- 使用缓存技术,减少重复查找。
通过以上对查找函数的使用方法及实例的介绍,相信大家对查找函数有了更深入的了解,在实际编程中,选择合适的查找函数可以提高程序的效率和性能。
其他相关扩展阅读资料参考文献:
Python查找函数
-
内置函数find()
Python字符串的find()函数用于查找子字符串首次出现的索引位置,若未找到返回-1。s = "hello",s.find("e")返回1,s.find("z")返回-1,此函数对大小写敏感,适合快速定位字符位置。 -
内置函数index()
index()函数功能与find()类似,但若未找到会抛出ValueError异常。s = "hello",s.index("e")返回1,若输入"z"则程序报错,此特性适合需要强制验证存在性的场景。 -
in关键字
in是Python的关键词,用于判断子字符串是否存在于目标字符串中,返回布尔值。"e" in "hello"为True,"z" in "hello"为False,相比函数,in语法更简洁,适合条件判断。 -
pandas库的read_csv()
在数据分析中,pandas.read_csv()用于读取CSV文件,支持通过参数header指定列名,index_col设置索引列。df = pd.read_csv("data.csv", header=0)可正确读取表头,避免数据错位。 -
pandas库的search()
pandas.DataFrame.search()用于在数据框中匹配正则表达式,返回符合条件的行索引。df.search("^[A-Z]")可筛选以大写字母开头的行,适合复杂数据过滤。
Excel查找函数
-
VLOOKUP函数
VLOOKUP(查找值, 表格区域, 列号, [是否近似匹配])用于垂直查找,需确保查找值在表格区域的第一列。=VLOOKUP("苹果", A2:D10, 3, FALSE)可从第3列返回苹果的价格。 -
HLOOKUP函数
HLOOKUP与VLOOKUP类似,但查找方向为水平。=HLOOKUP("销量", A1:D10, 2, FALSE)可从第2行返回“销量”对应的数据,适合行数据查找场景。 -
INDEX+MATCH组合
INDEX+MATCH替代传统VLOOKUP,实现更灵活的查找。=INDEX(B2:B10, MATCH("苹果", A2:A10, 0))可动态匹配列,避免因列序变动导致的错误。 -
FILTER函数
FILTER(数组, 条件, [如果无结果])用于筛选符合条件的数据,返回数组。=FILTER(A2:C10, B2:B10>100, "无数据")可筛选销售额超过100的记录,支持多条件组合。 -
TEXTJOIN函数
TEXTJOIN(分隔符, 是否忽略空值, 文本区域)用于合并多个单元格内容,避免空值干扰。=TEXTJOIN(", ", TRUE, A2:A10)可将A2到A10的文本用逗号分隔并合并,适合生成汇总字符串。
数据库查询函数
-
SELECT语句
SQL中SELECT用于查询数据,结合WHERE筛选条件。SELECT * FROM users WHERE age > 30可获取年龄大于30的用户记录,是基础且核心的查找方式。 -
JOIN操作
JOIN用于连接多个表,通过公共字段匹配数据。SELECT orders.order_id, customers.name FROM orders JOIN customers ON orders.customer_id = customers.id可合并订单与客户信息,实现跨表查找。 -
子查询
子查询嵌套在主查询中,用于动态生成查找条件。SELECT * FROM products WHERE category IN (SELECT category FROM categories WHERE type = "食品")可筛选特定分类的商品,提升查询灵活性。 -
GROUP BY与HAVING
GROUP BY对数据分组,HAVING筛选分组后的结果。SELECT category, COUNT(*) FROM products GROUP BY category HAVING COUNT(*) > 10可统计商品数量超过10的分类,适合聚合分析。 -
LIKE与通配符
LIKE配合或_通配符实现模糊查找。SELECT * FROM users WHERE name LIKE "张%"可获取所有姓张的用户,支持部分匹配和模式识别。
正则表达式查找函数
-
re.search()
Python的re.search()用于在字符串中查找匹配项,返回第一个匹配对象。re.search(r"\d+", "价格:100元")可提取数字“100”,适合文本解析场景。 -
re.findall()
re.findall()返回所有匹配项组成的列表。re.findall(r"\d+", "123abc456")返回["123", "456"],适合批量提取数据。 -
re.finditer()
re.finditer()迭代匹配结果,适用于处理大量数据时的逐项操作。for match in re.finditer(r"\w+", "hello world")可分别获取“hello”和“world”两个单词。 -
re.split()
re.split()根据正则表达式分割字符串。re.split(r"[,. ]+", "a,b c.d")返回["a", "b", "c", "d"],适合拆分复杂格式的文本。 -
re.sub()
re.sub()用于替换匹配项。re.sub(r"(\d+)", r"数字:\1", "123abc")可将数字替换为“数字:123”,适合数据清洗任务。
Web开发中的查找方法
-
DOM的querySelector()
JavaScript中querySelector()通过CSS选择器查找元素。document.querySelector("#id")可直接获取ID为“id”的元素,效率高于遍历。 -
filter()方法
filter()对数组或列表进行条件过滤。[1,2,3].filter(x => x > 1)返回[2,3],适合处理前端数据集。 -
getElementById()
getElementById()直接通过元素ID获取对象。document.getElementById("name")可快速操作特定元素,是基础但高效的查找方式。 -
事件监听中的find()
在事件处理中,find()用于定位目标元素。event.target.find(".class")可获取事件触发元素下的子元素,适合动态交互场景。 -
JSON数据查找
在JavaScript中,可通过JSON.parse()解析数据后使用find()方法。data.find(item => item.id === 100)可从对象数组中查找指定ID的条目,适合处理结构化数据。
查找函数是编程与数据处理的核心工具,其应用范围覆盖字符串、表格、数据库、正则表达式及Web开发等多个领域,掌握不同场景下的函数特性(如Python的find()与index()区别、Excel的VLOOKUP与FILTER组合),能显著提升工作效率。合理选择函数并理解其参数逻辑,是高效处理数据的关键。
“查找函数的使用方法及实例,深度解析,查找函数应用指南与实战案例” 的相关文章
修改横向滚动条样式,自定义与美化,横向滚动条样式修改指南
修改横向滚动条样式通常涉及调整其颜色、宽度、透明度等属性,需要确定滚动条所在的HTML元素和CSS选择器,通过CSS的:scrollbar伪元素或直接修改::-webkit-scrollbar等特定浏览器前缀的属性来定制样式,具体步骤包括:,1. 确定滚动条元素的选择器。,2. 使用CSS的:scr...

green beans是什么意思,Green Beans的含义揭秘
"Green beans"是指“青豆”,通常指的是新鲜的、绿色的豆角,未成熟的豆类,可以用来烹饪,在英语中,它也可以指“绿豆”,一种小型的豆类,常用于亚洲料理,在不同的语境中,green beans可以指代这两种不同的豆类。 大家好,最近我在看一些国外的菜谱,发现里面经常提到“green bean...

织梦模板系统使用教程,轻松上手,织梦模板系统操作指南
织梦模板系统使用教程摘要:,本教程旨在指导用户如何使用织梦模板系统,介绍系统安装与配置,包括环境准备和基本设置,详细讲解模板的下载、编辑与上传,以及如何应用模板美化网站界面,还将指导用户进行模块管理、内容发布和SEO优化,确保网站功能完善、搜索引擎友好,提供常见问题解答和进阶技巧,助力用户高效利用织...

c语言2级考试题库,C语言二级考试题库精选
为C语言二级考试题库相关资料,涵盖了C语言二级考试的各类题型和知识点,题库内容丰富,包括选择题、填空题、编程题等,旨在帮助考生全面复习和巩固C语言基础知识,提高解题能力,为顺利通过C语言二级考试做好准备。 我正在准备C语言二级考试的复习,感觉题目难度适中,但有些概念还是需要巩固,指针和数组的关系,...

如何制作游戏,轻松入门,游戏制作全攻略
制作游戏是一个复杂的过程,涉及以下几个步骤:明确游戏类型和目标受众;设计游戏故事和角色,包括剧情、世界观和角色设定,进行游戏原型开发,通过编程和美术资源创建基础游戏框架,测试和优化游戏,确保游戏玩法流畅,无bug,制作游戏宣传材料和营销计划,准备发布,整个过程中,团队合作、持续反馈和细致规划至关重要...
python颜色代码表,Python编程中的颜色代码一览表
Python颜色代码表通常用于在控制台输出时为文本添加颜色,以下是一些常用的颜色代码:,- 黑色:\033[0;30m,- 红色:\033[0;31m,- 绿色:\033[0;32m,- 黄色:\033[0;33m,- 蓝色:\033[0;34m,- 紫色:\033[0;35m,- 青色:\033[...
- 最新发布
-
4分钟前

11分钟前
17分钟前

25分钟前

32分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言