python网页爬虫(Python网页爬虫期末大作业)
本文目录一览:
python为什么叫爬虫?
1、Python被称为“爬虫”并不是因为编程语言本身的名字,而是由于使用Python语言编写的网络爬虫程序非常普遍。具体原因如下:编程语言名称由来:Python这个名字来源于大蟒蛇,是Guido van Rossum在1989年为了打发无聊的圣诞节而命名的一种编程语言,与爬虫无关。
2、Python被称为“爬虫”的原因主要是因为它非常适合开发网络爬虫。具体原因如下:脚本特性与灵活性:Python具有脚本特性,易于配置,对字符的处理也非常灵活,这使得它在处理网络数据时非常高效。
3、Python被称为“爬虫”的主要原因在于其简洁的网页爬取接口和高效的第三方包支持。具体来说:简洁的网页爬取接口:Python语言相比于其他编程语言,在爬取网页文档方面具有更简洁的接口。Python的urllib2包提供了完整的访问网页文档的API,使得开发者能够更轻松地实现网页的抓取。
4、Python被称为“爬虫”的原因: 脚本特性与灵活性:Python具有强大的脚本特性,能够灵活处理字符,且拥有丰富的网络抓取模块。 网络信息收集:Python常被用于构建自动抓取万维网信息的程序,即网络爬虫。这些爬虫程序能够高效地收集网络资源,如网页内容、图片、视频等。
python为什么叫爬虫
综上所述,Python被称为“爬虫”主要是因为使用Python编写的网络爬虫程序非常普遍,而不是因为Python编程语言本身与爬虫有直接关联。
Python被称为“爬虫”的原因: 脚本特性与灵活性:Python具有强大的脚本特性,能够灵活处理字符,且拥有丰富的网络抓取模块。 网络信息收集:Python常被用于构建自动抓取万维网信息的程序,即网络爬虫。这些爬虫程序能够高效地收集网络资源,如网页内容、图片、视频等。
Python被称为“爬虫”的主要原因在于其简洁的网页爬取接口和高效的第三方包支持。具体来说:简洁的网页爬取接口:Python语言相比于其他编程语言,在爬取网页文档方面具有更简洁的接口。Python的urllib2包提供了完整的访问网页文档的API,使得开发者能够更轻松地实现网页的抓取。
Python被形象地称为”爬虫”语言,主要是因为它非常适合编写网络爬虫程序,能够方便地抓取和分析网页数据。Python的语法简洁明了,易于上手,同时它拥有丰富的第三方库,这些库为网络爬虫的开发提供了极大的便利。
Python被称为“爬虫”的原因主要是因为它非常适合开发网络爬虫。具体原因如下:脚本特性与灵活性:Python具有脚本特性,易于配置,对字符的处理也非常灵活,这使得它在处理网络数据时非常高效。
Python爬虫是干什么的
1、Python爬虫是一种利用Python编程语言编写的网络爬虫程序。它能够模拟人类的行为,在网页上自动执行点击、浏览、抓取等操作,从而收集所需的信息。Python爬虫的功能 数据收集:Python爬虫能够高效地收集互联网上的各种数据,如网页内容、图片、视频等。这些数据可以用于数据分析、数据挖掘、机器学习等领域。
2、Python爬虫除了数据抓取外,还可以用于以下方面:自动化购买:商品抢购:利用Selenium等工具,Python爬虫可以模拟用户操作,实现自动化购买,如抢购限量版商品。自动下单:在电商平台,爬虫可以自动填写订单信息并提交,简化购物流程。
3、Python爬虫是一种使用Python程序开发的网络爬虫,主要用于自动地抓取万维网信息的程序或者脚本。以下是关于Python爬虫的详细解Python爬虫的定义 Python爬虫,又称网页蜘蛛、网络机器人,是一种按照一定的规则,自动地在互联网上抓取信息的程序或脚本。
4、Python:Python可用于Web开发、数据分析、人工智能、自动化运维等多个领域,具有广泛的应用前景。爬虫:爬虫主要用于搜索引擎、数据采集、内容监测等场景,通过自动化地抓取网页信息,实现数据的快速获取和处理。实现方式:Python:Python可以通过编写代码来实现各种功能,包括爬虫功能,但Python本身并不等同于爬虫。
5、Python爬虫能做的事情主要包括数据获取、数据处理、数据存储等。数据获取: Python爬虫能够模拟浏览器行为,访问各种网站并提取所需信息。 它能够高效地获取动态数据、静态网页内容,以及隐藏在网页中的结构化数据。 这对于数据分析和数据挖掘工作极为重要,为这些工作提供了丰富的数据源。
Python爬虫——爬虫中常见的反爬手段和解决思路分享
1、Headers字段:网站可能检查请求的User-Agent,限制非正常行为的爬虫访问。解决方法是设置正确的User-Agent或使用代理池。 Referer字段:服务器依据请求来源判断请求合法性。添加正确的Referer字段以通过验证。 Cookie:网站利用cookie检查访问权限,避免未授权的抓取。
2、robots.txt文件用于指示爬虫哪些页面不应抓取。尽管它只是一个约定俗成的协议,但仍然是有效的隐私保护手段。解决方法**:在Scrapy框架中禁用robots.txt检查。 **数据动态加载 使用JavaScript加载数据增加了爬取难度。可利用抓包工具获取请求URL,结合自动化工具解析动态内容。
3、**基于User-Agent反爬 简介:服务器会统计访问的User-Agent,若单位时间内同一User-Agent访问次数超过阈值,则封禁IP。解决方法:- 将常用User-Agent放入列表中,随机使用。
4、通过UA判断:UA是UserAgent,是要求浏览器的身份标志。UA是UserAgent,是要求浏览器的身份标志。反爬虫机制通过判断访问要求的头部没有UA来识别爬虫,这种判断方法水平很低,通常不作为唯一的判断标准。反爬虫非常简单,可以随机数UA。
5、在探索Python反爬虫的四种常见方法时,我们主要关注JavaScript(JS)的逆向方法论。这包括JS生成cookie、JS加密Ajax请求参数、JS反调试以及JS发送鼠标点击事件。首先,当我们尝试使用Python的requests库抓取某个网页时,可能会发现返回的是一段JS代码,而非HTML内容。
“python网页爬虫(Python网页爬虫期末大作业)” 的相关文章
有js为什么还要php,JavaScript与PHP,互补而非替代
JavaScript(JS)和PHP都是常用的编程语言,但它们各自服务于不同的场景,JS主要用于前端开发,负责网页的交互性和动态效果,而PHP则常用于后端开发,处理服务器端的逻辑和数据存储,尽管JS在网页交互方面非常强大,但PHP在服务器端数据处理、数据库交互和网站架构方面有着深厚的积累和广泛的适用...

true height,揭秘真实高度,探索测量与呈现的真相
《True Height:揭秘真实高度》深入探讨测量与呈现的真相,本书通过详实的案例和科学分析,揭示测量误差的来源,以及如何更准确地呈现物体的高度,作者从历史到现代,从建筑到自然,全面解析真实高度在各个领域的应用与挑战,为读者带来一场关于测量的科学盛宴。True Height:揭秘身高的奥秘...
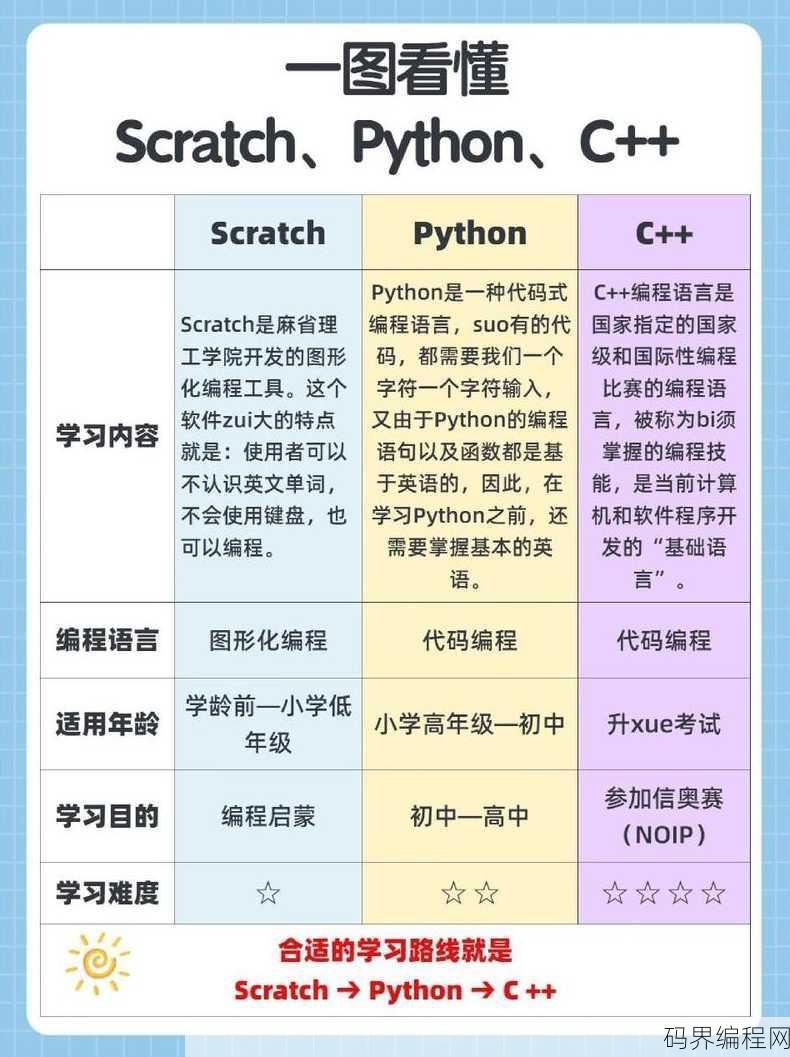
软件编程和硬件编程的区别,软件编程与硬件编程的差异化解析
软件编程主要涉及编写指令,控制计算机软件运行,解决逻辑问题和数据处理,强调的是算法和程序设计,而硬件编程则侧重于编写控制硬件设备的代码,如嵌入式系统、集成电路等,它直接与硬件电路和物理组件打交道,两者的主要区别在于:软件编程侧重于逻辑和数据处理,硬件编程则侧重于硬件控制和电路设计,软件编程通常使用高...
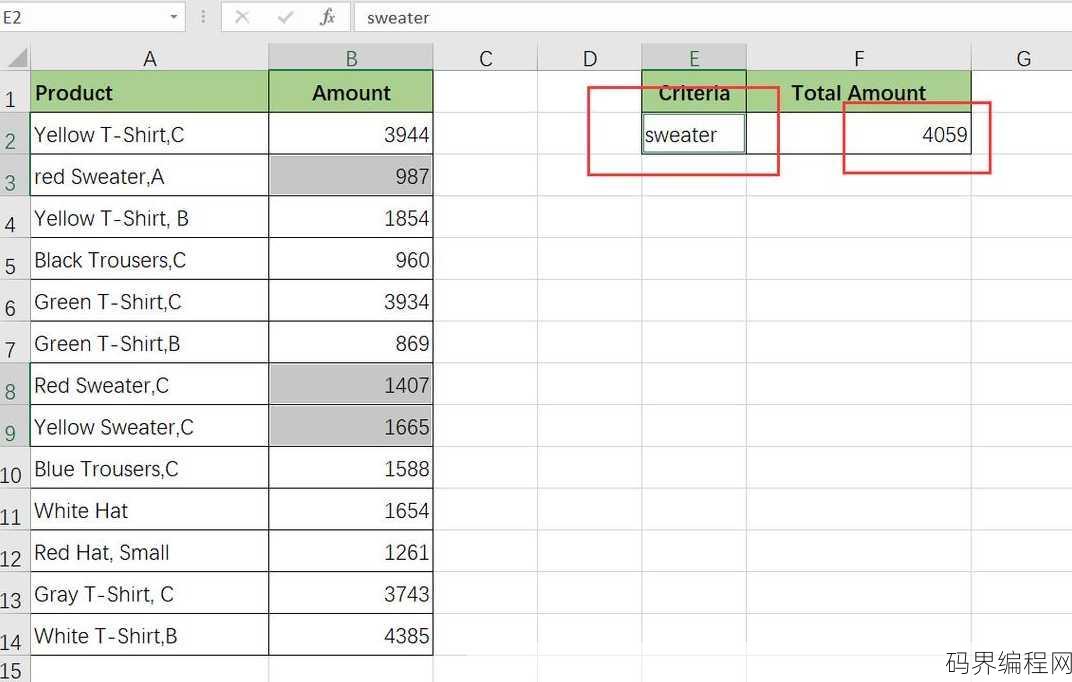
sumproduct单条件求和,Sumproduct函数实现单条件求和技巧解析
Sumproduct函数在Excel中用于计算数组与数组之间对应元素的乘积之和,特别适用于单条件求和,它可以将两个或多个数组作为输入,其中至少一个数组为条件数组,其余为数值数组,当条件数组中的元素满足特定条件时,与之对应的数值数组中的元素将被相乘并求和,此函数对于处理多条件组合求和尤其有用,能够有效...

下载mysql教程,MySQL下载与入门教程
本教程将指导您如何下载并安装MySQL数据库,访问MySQL官方网站获取最新版本的安装包,根据您的操作系统选择合适的版本,然后下载,下载完成后,按照教程中的步骤进行安装,包括配置MySQL服务、设置用户权限等,教程还涵盖了MySQL的初始设置和常见问题解决,确保您能够顺利开始使用MySQL数据库。...
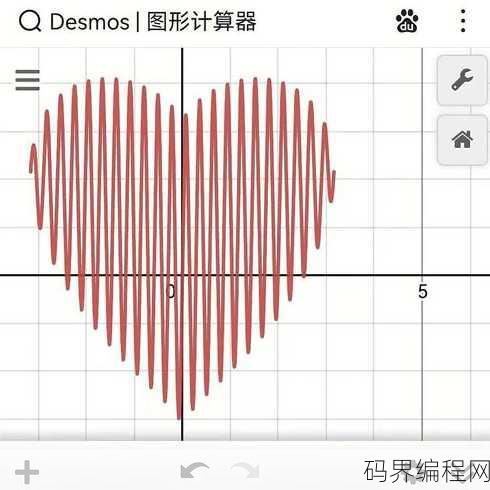
desmos图形计算器,探索数学之美,Desmos图形计算器应用指南
Desmos图形计算器是一款强大的在线数学工具,支持绘制函数图像、解析几何问题、以及进行代数运算,用户可通过直观的界面输入数学表达式,实时观察结果变化,适用于教学、学习以及研究,它支持多种图形功能,如参数方程、极坐标方程,并提供丰富的交互式操作,让数学学习变得更加生动有趣。Desmos图形计算器——...
- 最新发布
-
3分钟前
10分钟前
17分钟前

24分钟前

30分钟前
- 热门阅读
-

916 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言