python爬虫项目,Python爬虫实战项目教程
Python爬虫项目通常涉及使用Python编程语言和其丰富的库(如requests、BeautifulSoup、Scrapy等)来从互联网上抓取数据,该项目旨在自动化地从目标网站获取信息,如网页内容、图片、视频等,开发者需要分析目标网站的HTML结构,编写爬虫逻辑来解析数据,并可能处理反爬虫机制,项目过程中还需注意遵守网站的使用条款和法律法规,确保爬取的数据合法、合规。
用户提问:我最近想学习做爬虫,但是对Python爬虫项目不太了解,能给我介绍一下吗?
解答:当然可以,Python爬虫项目是利用Python语言编写程序,从互联网上抓取数据的过程,它可以帮助我们获取各种网站的信息,如新闻、图片、商品信息等,下面我将从几个来详细介绍Python爬虫项目。
一:Python爬虫的基本原理
- 网络请求:使用Python内置的
urllib或第三方库如requests来发送HTTP请求,获取网页内容。 - HTML解析:使用
BeautifulSoup或lxml等库解析HTML内容,提取所需数据。 - 数据存储:将提取的数据存储到文件或数据库中,以便后续分析和使用。
二:常见的Python爬虫框架
- Scrapy:一个强大的爬虫框架,提供了丰富的API和中间件,可以高效地处理大量数据。
- Selenium:主要用于模拟浏览器行为,适合爬取动态加载的网页。
- Scrapy-Redis:结合了Scrapy和Redis,可以实现分布式爬虫,提高爬取效率。
三:Python爬虫实战案例
- 爬取新闻网站:通过分析新闻网站的结构,使用Scrapy框架抓取新闻标题、内容、发布时间等数据。
- 爬取电商网站商品信息:分析电商网站的商品列表页面,提取商品名称、价格、评价等信息。
- 爬取图片网站图片:分析图片网站的结构,使用requests库下载图片。
四:Python爬虫注意事项
- 遵守网站:在爬取数据时,要遵守目标网站的robots.txt文件,尊重网站规定。
- 防止反爬:针对目标网站的防爬策略,如IP封禁、验证码等,需要采取相应的措施,如更换IP、使用代理等。
- 数据清洗:获取到的数据可能存在缺失、重复等问题,需要进行清洗和整理。
五:Python爬虫进阶技巧
- 异步爬取:使用
asyncio库实现异步请求,提高爬取效率。 - 分布式爬取:使用Scrapy-Redis等工具实现分布式爬取,提高爬取速度。
- 日志记录:使用
logging库记录爬取过程中的关键信息,方便调试和问题追踪。
通过以上几个的介绍,相信你已经对Python爬虫项目有了初步的了解,Python爬虫项目不仅可以帮助我们获取互联网上的数据,还可以作为数据分析、机器学习等领域的预处理工具,希望这篇文章能对你有所帮助。

其他相关扩展阅读资料参考文献:
Python爬虫项目:入门与实践
爬虫技术的介绍
Python爬虫技术是一种基于Python语言的数据采集技术,通过模拟浏览器行为,实现对网页数据的自动抓取和分析,爬虫技术广泛应用于数据采集、数据挖掘、信息分析等领域,本文将介绍Python爬虫项目的基础知识,包括爬虫的基本原理、常用工具和技术要点等。
爬虫项目的及要点分析

一:爬虫的基本原理与工作流程
- 爬虫的基本原理:爬虫通过发送HTTP请求获取网页数据,然后解析网页结构提取所需信息,这个过程涉及到HTTP协议、网页结构解析等技术。
- 工作流程简述:爬虫的工作流程包括目标网站分析、URL管理、网页数据抓取、数据存储等环节,目标网站分析是爬虫开发的关键步骤,需要了解网站的页面结构、数据加载方式等。
二:Python爬虫常用工具库
- 请求库的选择:Python中常用的请求库有requests和selenium,requests适用于简单的HTTP请求,而selenium可以模拟浏览器行为,处理复杂的动态页面。
- 解析库的选择:常用的网页解析库有BeautifulSoup和lxml等,这些库可以方便地提取网页中的结构化数据。
- 数据存储方案:爬虫抓取的数据需要存储,常用的存储方式有保存到文件、数据库或数据仓库等。
三:反爬虫机制与应对策略
- 常见反爬虫机制:目标网站会采取各种措施来防止爬虫访问,如设置验证码、限制访问频率等。
- 应对策略:针对反爬虫机制,可以通过设置合理的访问间隔、使用代理IP、模拟浏览器行为等方式来应对。
四:爬虫项目的实际应用案例
- 天气数据爬取:通过爬虫技术爬取天气数据,实现天气预报功能。
- 股票数据分析:爬取股票数据,进行数据分析与挖掘,辅助投资决策。
- 新闻资讯采集:爬取新闻网站的数据,实现新闻资讯的自动更新与推送。
Python爬虫项目实践步骤

- 确定目标网站:明确爬虫项目的目标,选择目标网站进行分析。
- 分析网页结构:了解目标网站的页面结构、数据加载方式等,以便制定合适的爬虫策略。
- 编写爬虫代码:根据目标网站的分析结果,使用Python编写爬虫代码,包括请求、解析、数据存储等环节。
- 测试与优化:对编写的爬虫代码进行测试,根据测试结果进行优化,提高爬虫的效率和稳定性。
- 部署与运行:将优化后的爬虫代码部署到服务器上,实现自动化运行和数据分析。
总结与展望
本文介绍了Python爬虫项目的基础知识、常用工具库、反爬虫机制与应对策略以及实际应用案例,通过实践步骤的指导,读者可以初步掌握Python爬虫项目的开发过程,随着技术的不断发展,Python爬虫项目将在更多领域得到应用,如自然语言处理、数据挖掘等,Python爬虫技术将朝着更加智能化、高效化的方向发展。
“python爬虫项目,Python爬虫实战项目教程” 的相关文章
element ui组件库,Element UI,全面解析前端开发组件库
Element UI 是一个基于 Vue 2.0 的前端UI框架,提供了一套丰富的组件库,旨在帮助开发者快速构建美观、响应式和功能齐全的网页应用,它涵盖了按钮、表单、表格、对话框等多种常用组件,并支持自定义主题和样式,Element UI 以其简洁的API、优雅的设计和良好的文档而受到开发者的青睐。...
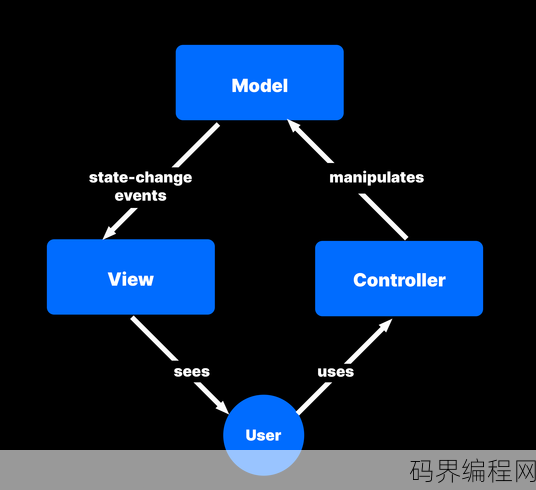
mvc,深入解析MVC架构模式
MVC(Model-View-Controller)是一种软件开发架构模式,旨在提高代码的可维护性和可扩展性,它将应用程序分为三个主要组件:模型(Model)负责数据管理和业务逻辑;视图(View)负责显示数据;控制器(Controller)负责处理用户输入和协调模型与视图之间的交互,通过这种分层结...
程序代码软件,程序代码软件创新与应用指南
程序代码软件是一种用于编写、调试和运行计算机程序的工具,它提供了丰富的编程语言和环境,帮助开发者高效地实现各种功能,通过该软件,用户可以编写代码,构建应用,进行代码优化,以及进行版本控制等操作,程序代码软件广泛应用于软件开发、科学研究、教育和工业制造等领域。揭开编程世界的神秘面纱 用户解答: 嗨...

java编程思想第六版pdf百度云,Java编程思想第六版官方PDF版下载
《Java编程思想》第六版,是一部全面介绍Java编程语言的经典之作,书中地讲解了Java编程的核心概念和最佳实践,涵盖面向对象编程、集合框架、泛型、异常处理、I/O操作等多个方面,通过大量实例和练习,帮助读者掌握Java编程技巧,提高编程能力,本书适合Java初学者和有一定基础的读者阅读,是学习J...
爬虫技术违法吗,网络爬虫法律风险解析
爬虫技术本身并不违法,它是一种通过网络爬取数据的技术,使用爬虫技术爬取数据是否违法,取决于所爬取数据的来源和目的,未经授权爬取他人网站数据,或者爬取数据用于非法用途,都可能构成违法,合理使用爬虫技术,遵守相关法律法规,是确保其合法性的关键。 你好,我最近在做一个关于电商价格比较的项目,打算使用爬虫...
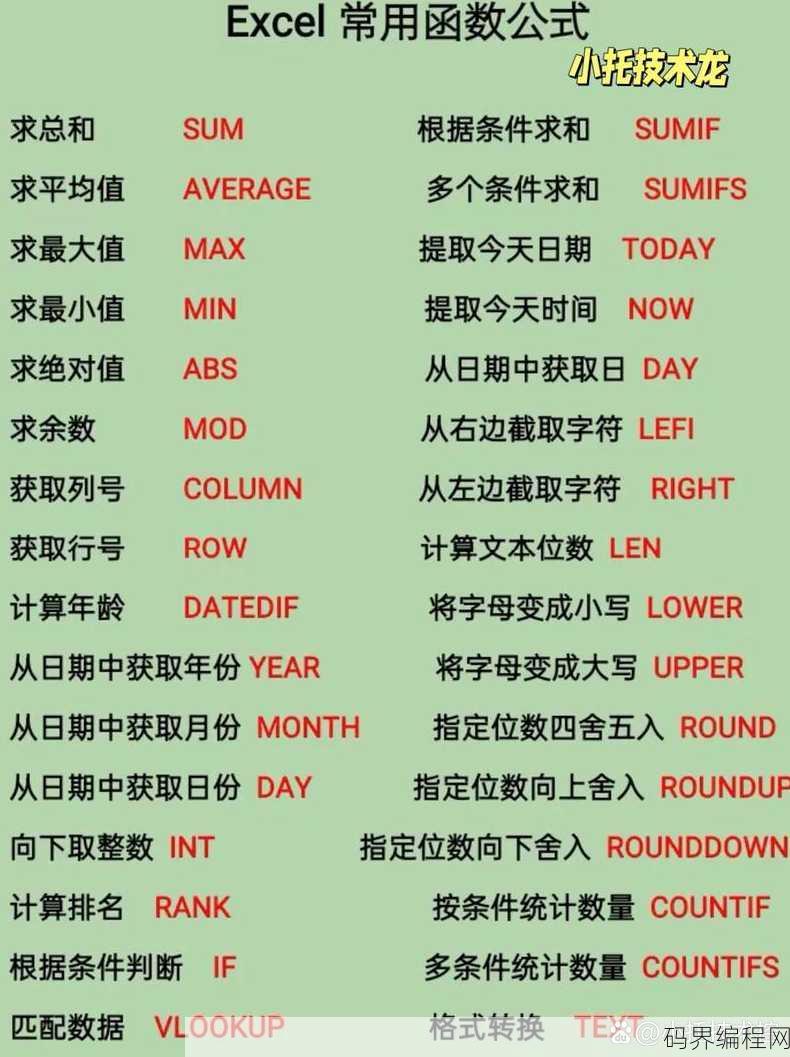
sumif函数公式,Sumif函数应用公式解析
SUMIF函数是Excel中用于根据指定条件对单元格区域内的数值求和的函数,其基本公式为:SUMIF(range, criteria, [sum_range])。“range”是需要进行条件判断的单元格区域,“criteria”是用于判断的条件表达式,而“[sum_range]”是可选的,表示需要求...
- 最新发布
-
4分钟前

12分钟前

18分钟前

26分钟前
33分钟前
- 热门阅读
-

903 浏览学习方法

242 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言