爬虫编程,高效爬虫编程技巧解析
爬虫编程是一种自动化获取互联网上信息的程序编写技术,它通过模拟浏览器行为,从网站抓取数据,然后提取有用信息,这一过程涉及网页解析、数据提取和存储等步骤,爬虫在数据分析和网络营销等领域发挥着重要作用,但需遵守相关法律法规,尊重网站版权和数据隐私。
爬虫编程**
用户解答
“你好,我想学习爬虫编程,但是对它一无所知,你能给我介绍一下吗?”

爬虫编程,就是利用程序从互联网上抓取数据的技巧,它广泛应用于搜索引擎、数据挖掘、舆情监测等领域,掌握了爬虫技术,你可以在海量信息中迅速找到所需数据,提高工作效率。
一:爬虫的基本原理
- 网络请求:爬虫通过发送HTTP请求,向目标网站获取页面内容。
- HTML解析:爬虫解析HTML代码,提取所需信息。
- 数据存储:将提取的数据存储到数据库或文件中。
二:常用的爬虫框架
- Scrapy:Python中一个强大的爬虫框架,支持分布式爬虫。
- Beautiful Soup:Python的一个库,用于解析HTML和XML文档。
- Requests:Python的一个库,用于发送HTTP请求。
三:爬虫的优缺点
- 优点:
- 高效:可以快速获取大量数据。
- 自动化:可以自动执行,节省人力。
- 灵活:可以根据需求定制爬虫。
- 缺点:
- 违法风险:爬取某些网站的数据可能侵犯版权。
- 性能消耗:爬虫程序会占用大量服务器资源。
- 反爬虫机制:一些网站设置了反爬虫机制,增加了爬取难度。
四:爬虫编程的注意事项
- 遵守法律法规:确保爬取的数据不侵犯版权,不违反相关法律法规。
- 尊重网站规则:不要过度爬取,避免给目标网站带来压力。
- 合理设置爬取速度:避免对目标网站造成过大压力。
- 备份数据:定期备份爬取的数据,以防数据丢失。
五:爬虫编程的应用场景
- 搜索引擎:通过爬虫技术,搜索引擎可以快速索引互联网上的信息。
- 数据挖掘:从海量数据中提取有价值的信息。
- 舆情监测:实时监测网络上的热点事件和用户评价。
- 价格比较:爬取各大电商网站的商品信息,进行比较。
- 信息采集:从各类网站采集信息,用于分析和研究。 相信你对爬虫编程有了初步的了解,爬虫编程是一项实用的技能,可以帮助你快速获取所需数据,提高工作效率,在学习和使用爬虫技术时,一定要遵守法律法规,尊重网站规则,合理使用资源。
其他相关扩展阅读资料参考文献:
入门与实践
爬虫编程的介绍
随着互联网的发展,数据获取变得越来越重要,爬虫编程作为一种自动化获取网络数据的方式,受到了广泛关注,通过爬虫编程,我们可以从互联网上抓取所需的数据,进而进行数据分析、数据挖掘等工作。

一:爬虫编程基础
爬虫编程的基本概念
爬虫,又称为网页蜘蛛,是一种按照一定的规则,自动抓取互联网信息的程序,爬虫编程就是编写这样的程序,以实现数据的自动化获取。
常用的爬虫编程工具
常见的爬虫编程工具有Python的requests库、BeautifulSoup库、Scrapy框架等,这些工具可以大大提高我们编写爬虫的效率。

爬虫编程的基本流程
爬虫编程的基本流程包括:发送请求、接收响应、解析页面、提取数据等步骤。
二:爬虫编程进阶
应对反爬虫策略
随着网站反爬虫机制的加强,我们需要掌握一些应对反爬虫的策略,如设置合理的请求头、处理Cookie、使用代理等。
爬取动态加载页面的数据
动态加载页面是爬虫编程中常见的挑战之一,我们需要通过模拟浏览器行为,如使用Selenium等工具,来获取动态加载页面的数据。
分布式爬虫的实现
分布式爬虫可以大大提高爬取效率,我们可以通过Scrapy框架的分布式扩展,实现分布式爬虫。
三:爬虫编程实践
爬取电商平台的商品信息
以电商平台为例,介绍如何爬取商品信息,包括商品名称、价格、销量等。
爬取新闻网站的数据
新闻网站的数据爬取是爬虫编程中的常见场景,通过实践,学习如何处理新闻页面的特殊性,提取所需数据。
爬取社交媒体的数据
社交媒体的数据爬取具有一定的挑战性,通过实践,学习如何处理社交媒体的反爬虫策略,获取用户信息、帖子内容等。
四:数据安全与合规
爬虫编程中的数据安全
在爬虫编程过程中,我们需要关注数据安全,避免泄露敏感信息,如用户隐私等。
遵守法律法规
在进行爬虫编程时,我们必须遵守相关法律法规,尊重网站的使用协议,避免侵犯他人权益。
通过本文对爬虫编程的入门与实践介绍,希望读者能对爬虫编程有更深入的了解,并能将所学知识应用于实际项目中。
“爬虫编程,高效爬虫编程技巧解析” 的相关文章
成品源码1688网站免费,免费获取1688网站成品源码,轻松开启电商之旅
提供免费1688网站源码,可直接用于搭建电商网站,源码包含完整功能,无需额外付费,适合个人或企业快速启动在线销售平台,获取源码后,用户可轻松部署并开始运营。成品源码1688网站免费:揭秘免费背后的真相与价值 作为一个长期在互联网上寻找资源的老手,我最近在逛1688网站时,意外发现了一个让人眼前一亮...

二级c语言考试时间,2023年二级C语言考试时间安排
2023年二级C语言考试时间已确定,具体安排如下:考试将于该年度的某个具体日期举行,具体日期以官方公告为准,考生需提前关注官方信息,确保按时参加考试。二级C语言考试时间:揭秘你的备考之路 很多朋友都在问我:“二级C语言考试时间是什么时候?”这个问题让我想起,当年我也是在这个时间节点上,为了考试而忙...
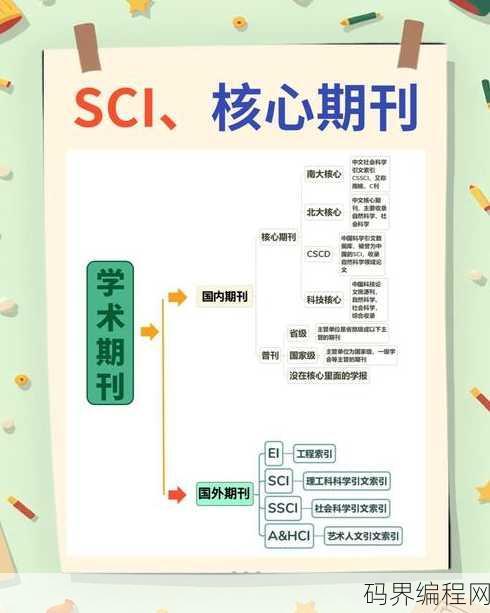
cssci和sci哪个级别高,CSSCI与SCI级别比较,究竟哪个更高?
CSSCI(中国社会科学引文索引)和SCI(科学引文索引)是两个不同领域的学术评价体系,CSSCI主要针对中国的人文社会科学领域,而SCI则涵盖自然科学领域,在学术评价上,SCI因其广泛的影响力和国际认可度,通常被认为在国际学术界的地位更高,CSSCI在中国社会科学领域同样具有重要影响力,从国际视野...
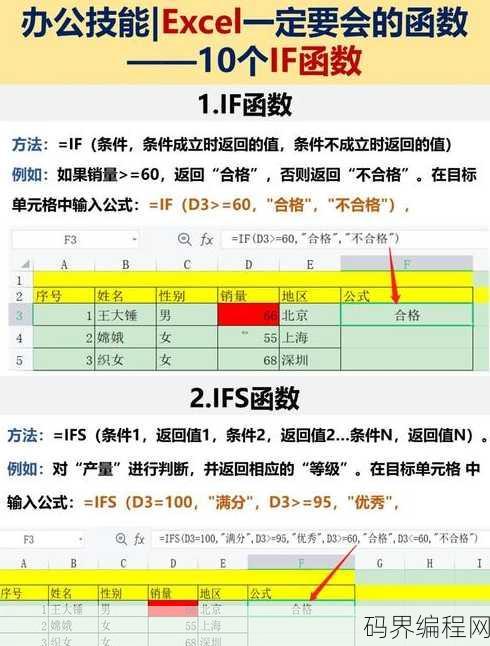
excelif函数的用法,Excel IF函数应用指南
Excel IF函数用于根据特定条件判断结果,返回两个值中的一个,其基本语法为:IF(条件,真值,假值),当条件为真时,返回真值;否则返回假值,该函数可以嵌套使用,实现复杂逻辑判断,在数据分析、数据验证等方面有广泛应用。解读Excel IF函数的用法 用户提问:Excel中IF函数到底怎么用呢?我...

网站源码去哪里下载,网站源码获取指南,下载资源汇总
网站源码的下载途径有多种:,1. **开源平台**:可以从GitHub、GitLab等开源代码托管平台下载,这些平台上有许多开源项目的源码。,2. **商业网站**:某些商业网站可能提供付费下载网站源码的服务。,3. **开发者社区**:在Stack Overflow、Reddit等开发者社区中,有...
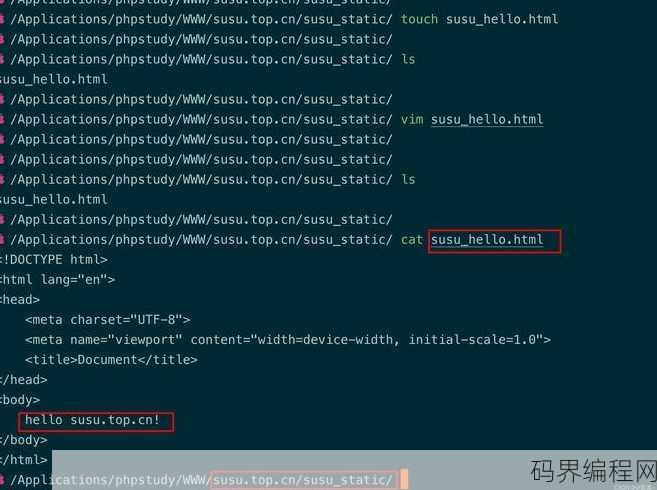
phpstudy运行php文件,PHPStudy环境下PHP文件运行指南
在PHPStudy环境中运行PHP文件,首先确保PHPStudy已正确安装并启动,打开浏览器,输入本地服务器的IP地址(通常是127.0.0.1),后跟端口(默认为8080)和文件路径(/index.php`),浏览器将显示PHP文件的内容,若文件包含HTML和PHP代码,PHP代码将首先被解析执行...
- 最新发布
-

4分钟前

10分钟前

18分钟前
24分钟前
31分钟前
- 热门阅读
-

908 浏览学习方法

242 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言