python爬虫案例,实战解析,Python爬虫案例教程
Python爬虫案例涉及使用Python编写脚本,从互联网上抓取数据的过程,以下是一个简单的案例摘要:,在Python爬虫案例中,我们通常使用库如requests和BeautifulSoup来发送网络请求并解析HTML内容,一个常见的任务是从某个新闻网站抓取最新文章标题和链接,使用requests库获取网页内容,然后利用BeautifulSoup解析HTML,提取所需信息,可以将提取的数据存储到数据库或文件中,以便进一步分析和使用,这个过程需要处理诸如网页结构变化、反爬虫机制等问题,并遵循网站的使用条款和法律法规。
Python爬虫案例:从入门到实战
我在学习Python爬虫的过程中遇到了不少问题,于是想在这里和大家分享一下我的学习心得,作为一名初学者,我深知入门爬虫的困难,但只要掌握了正确的方法,就能轻松应对各种爬虫任务,下面,我将结合实际案例,为大家地讲解Python爬虫。
一:Python爬虫基础知识
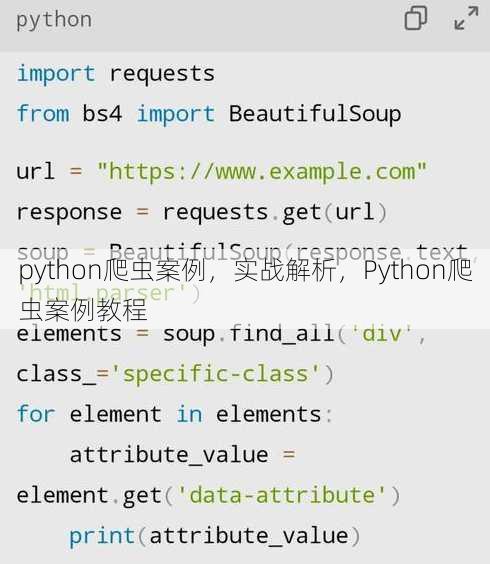
- 什么是爬虫?
爬虫(Web Crawler)是一种自动化程序,用于从互联网上获取信息,它通过模拟浏览器行为,自动获取网页内容,并从中提取所需数据。
- Python爬虫常用库:
- requests:用于发送HTTP请求,获取网页内容。
- BeautifulSoup:用于解析HTML和XML文档,提取数据。
- Scrapy:一个强大的爬虫框架,用于构建高性能爬虫。
- 爬虫流程:
(1)发送请求,获取网页内容; (2)解析网页内容,提取所需数据; (3)存储数据。
二:Python爬虫实战案例——爬取网页图片
-
目标网站:http://www.example.com
-
爬取目标:爬取网站中所有图片。

-
实现步骤:
(1)使用requests库发送请求,获取网页内容; (2)使用BeautifulSoup解析网页内容,提取图片链接; (3)使用requests库下载图片。
- 代码示例:
import requests
from bs4 import BeautifulSoup
def crawl_images(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
images = soup.find_all('img')
for img in images:
img_url = img.get('src')
if not img_url.startswith('http'):
img_url = 'http://www.example.com' + img_url
print(img_url)
response = requests.get(img_url)
with open('image' + img_url[-4:], 'wb') as f:
f.write(response.content)
if __name__ == '__main__':
crawl_images('http://www.example.com')
三:Python爬虫实战案例——爬取网页文章
-
目标网站:http://www.example.com
-
爬取目标:爬取网站中所有文章。

-
实现步骤:
(1)使用requests库发送请求,获取网页内容; (2)使用BeautifulSoup解析网页内容,提取文章标题和链接; (3)使用requests库获取文章内容; (4)存储文章标题、链接和内容。
- 代码示例:
import requests
from bs4 import BeautifulSoup
def crawl_articles(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.find_all('div', class_='article')
for article in articles:
title = article.find('h2').text
link = article.find('a')['href']
response = requests.get(link, headers=headers)
content = response.text
print(title, link)
with open(title + '.txt', 'w', encoding='utf-8') as f:
f.write(content)
if __name__ == '__main__':
crawl_articles('http://www.example.com')
四:Python爬虫实战案例——爬取网页商品信息
-
目标网站:http://www.example.com
-
爬取目标:爬取网站中所有商品信息,包括商品名称、价格、库存等。
-
实现步骤:
(1)使用requests库发送请求,获取网页内容; (2)使用BeautifulSoup解析网页内容,提取商品信息; (3)存储商品信息。
- 代码示例:
import requests
from bs4 import BeautifulSoup
def crawl_products(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
products = soup.find_all('div', class_='product')
for product in products:
name = product.find('h3').text
price = product.find('span', class_='price').text
stock = product.find('span', class_='stock').text
print(name, price, stock)
if __name__ == '__main__':
crawl_products('http://www.example.com')
通过以上案例,我们可以看到Python爬虫的强大功能,只要掌握了基础知识,并灵活运用各种库,就能轻松实现各种爬虫任务,在爬取数据时,我们也要遵守相关法律法规,尊重网站版权,不要对网站造成过大压力,希望这篇文章能对大家有所帮助,祝大家学习愉快!
其他相关扩展阅读资料参考文献:
电商价格监控案例
- 使用requests和BeautifulSoup抓取商品信息:直接访问电商平台网页,解析HTML结构,提取商品名称、价格等关键数据,通过发送HTTP请求获取页面内容,利用BeautifulSoup的
find_all方法定位商品列表,再逐个提取所需字段。 - 处理动态加载内容(Selenium):部分电商网站采用JavaScript动态渲染页面,需用Selenium模拟浏览器操作,启动浏览器实例,执行点击或滚动动作以加载更多商品信息,再通过WebDriver获取完整页面源码。
- 设置定时任务监控价格变化:利用
schedule库或系统定时工具(如Linux的cron)定期执行爬虫脚本,每小时抓取一次商品价格,对比历史数据生成价格波动报告,或触发自动通知功能。
社交媒体数据抓取案例
- 爬取微博热搜:通过分析微博网页结构,定位热搜榜单区域,使用正则表达式提取热搜关键词及话题链接,注意避开反爬虫机制(如频繁请求会被限制)。
- 分析Instagram图片标签:抓取图片URL后,利用第三方API(如Instagram Graph API)或网页解析获取标签数据,提取热门标签的出现频率,结合情感分析工具(如TextBlob)判断用户情绪倾向。
- 抓取Twitter热门话题:通过API接口(如Twitter API v2)直接获取实时话题数据,调用
GET trends/place接口,参数设置为地理位置ID,返回的话题列表可直接用于舆情监控或数据分析。
新闻资讯采集案例
- 爬取新闻标题和摘要:定位新闻网站的标题和摘要区域,使用XPath或CSS选择器提取内容,针对
<div class="gjqaerjgeihgjdfb0dda-b27e-48a3-bb49 news-content">标签,提取<h2>和<p>元素中的文本信息。 - 抓取多来源新闻整合:设计爬虫框架支持多网站数据抓取,通过配置不同的URL列表和解析规则,将新闻内容统一存储到数据库或CSV文件,便于后续分析。
- 处理新闻发布时间:提取时间戳并转换为标准格式(如ISO 8601),使用正则表达式匹配
<time datetime="...">中的时间信息,或解析<span class="gjqaerjgeihgjdfbb27e-48a3-bb49-d871 timestamp">中的文本内容,再用datetime模块处理时区问题。
股票数据获取案例
- 获取实时股价:通过金融数据API(如Alpha Vantage)或网页解析抓取股票信息,调用
GET https://www.alphavantage.co/query接口,参数function=TIME_SERIES_INTRADAY获取实时行情数据。 - 分析K线图数据:解析历史股价数据,生成趋势图表,使用
pandas处理时间序列数据,调用matplotlib绘制收盘价曲线,识别支撑位和阻力位。 - 抓取财务报表:定位财经网站的财报页面,提取关键指标(如营收、净利润),使用
requests获取财报HTML,利用BeautifulSoup提取<table>中的数据行,再用pandas转换为结构化数据。
天气预报抓取案例
- 爬取天气预报数据:通过解析天气网站的页面结构获取实时数据,定位
<div class="gjqaerjgeihgjdfb48a3-bb49-d871-8a8d weather-info">,提取温度、湿度、风速等字段,注意处理天气图标与文字的对应关系。 - 分析天气趋势:抓取多日天气数据后,使用时间序列分析工具(如
statsmodels)预测未来天气变化,基于历史温度数据构建ARIMA模 型,输出未来3天的温度趋势预测值。 - 抓取空气质量信息:定位环保部门网站的空气质量数据,提取PM2.5、AQI等指标,使用
requests获取API接口数据(如中国环境监测总站的公开数据),通过JSON解析提取关键参数。
关键注意事项:
- 反爬虫策略应对:通过设置请求头(如
User-Agent)、增加随机延迟、使用代理IP等方式规避网站限制,在requests中添加headers={'User-Agent': 'Mozilla/5.0'}模拟浏览器访问。 - 数据存储优化:选择适合的存储方式(如MySQL、MongoDB或Excel),确保数据可扩展性,使用
pandas.to_sql将爬虫结果直接写入数据库,或用csv模块导出结构化数据。 - 法律与伦理合规:遵守《计算机信息网络国际联网安全保护管理办法》等法规,避免抓取敏感信息或侵犯版权,仅抓取公开数据,并在脚本中添加版权声明。
技术工具推荐:
- Requests与BeautifulSoup:适合静态网页抓取,代码简洁但需处理反爬虫问题。
- Selenium与Playwright:适用于动态网页,能用户操作但资源消耗较大。
- Scrapy框架:适合大规模数据采集,提供分布式爬虫和数据处理管道功能。
实战建议:
- 模块化代码结构:将爬虫逻辑拆分为请求、解析、存储等独立函数,提高可维护性。
- 异常处理机制:添加
try-except块捕获网络错误或解析异常,确保脚本稳定性。 - 性能优化技巧:使用并发工具(如
asyncio)提升抓取效率,或采用缓存机制减少重复请求。
通过以上案例,可以看出Python爬虫在实际场景中的广泛应用。无论是监控商品价格、分析社交媒体数据,还是采集新闻或天气信息,核心在于精准定位数据源、高效处理反爬虫策略,并合理设计数据存储方案,对于初学者,建议从静态网页抓取开始,逐步掌握动态内容处理和分布式爬虫技术,始终关注法律法规,确保爬虫行为合法合规。
“python爬虫案例,实战解析,Python爬虫案例教程” 的相关文章
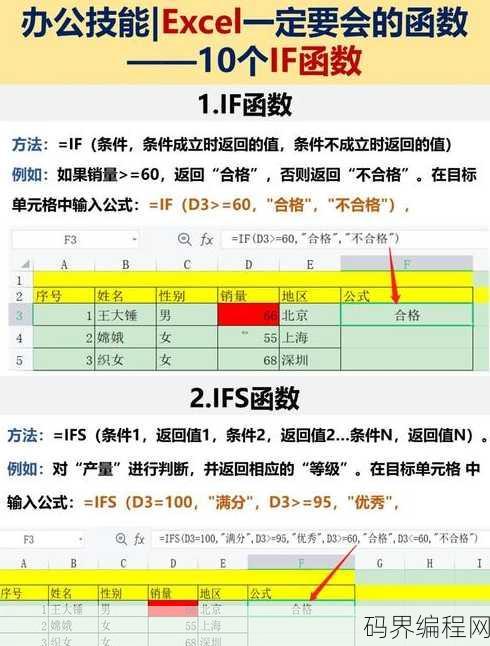
excelif函数的用法,Excel IF函数应用指南
Excel IF函数用于根据特定条件判断结果,返回两个值中的一个,其基本语法为:IF(条件,真值,假值),当条件为真时,返回真值;否则返回假值,该函数可以嵌套使用,实现复杂逻辑判断,在数据分析、数据验证等方面有广泛应用。解读Excel IF函数的用法 用户提问:Excel中IF函数到底怎么用呢?我...
数据库设计软件有哪些,数据库设计软件盘点,实用工具一览
数据库设计软件包括多种工具,如Microsoft SQL Server Management Studio、MySQL Workbench、Oracle SQL Developer、DbVisualizer、Navicat、Toad Data Modeler、ER/Studio Data Model...

模板王下载,一键获取模板王的超便捷下载方法
《模板王下载》是一款专门提供各类模板下载的软件,用户可以通过该平台轻松获取包括文档、设计、表格等多种类型的模板资源,软件界面简洁,操作便捷,支持多种格式转换,极大提高了工作效率,无论是办公、学习还是日常生活,模板王都能满足用户快速获取模板的需求。一站式解决方案,轻松解决设计难题 大家好,我是小王,...
htmltextarea提示文字,HTML 元素提示文字设置技巧
HTML中的`元素允许用户输入多行文本,为了提高用户体验,可以在标签内使用placeholder属性来设置提示文字,这些提示文字会在文本区域为空时显示,帮助用户了解输入区域的作用,`。HTML Textarea 提示文字:提升用户体验的细节之处 作为一名前端开发者,我常常在思考如何通过一些小小的细...
lightly在线编程免费版,轻松入门,lightly在线编程免费版体验指南
lightly在线编程免费版是一款提供便捷编程体验的平台,用户可以免费使用其提供的编程工具和功能,该平台支持多种编程语言,用户无需安装任何软件即可在线编写、运行和调试代码,它适合编程初学者和开发者进行学习和项目开发,提供实时编译和错误提示,助力用户提高编程效率。轻松入门,轻松编程——lightly在...

java人脸识别,Java实现人脸识别技术详解
Java人脸识别技术是一种利用Java编程语言实现的人脸检测、识别和追踪的技术,它通过图像处理和机器学习算法,能够从视频中提取人脸特征,识别出个体的身份,Java人脸识别技术在安全监控、身份验证、人脸美颜等领域有广泛应用,它具有跨平台、可扩展、易于集成的特点,为开发者提供了丰富的API和工具,助力实...
- 最新发布
-
4分钟前
10分钟前

17分钟前

24分钟前
32分钟前
- 热门阅读
-

911 浏览学习方法

243 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言