python爬虫库,Python爬虫实战,常用库深度解析
Python爬虫库是一套用于从网站中抓取数据的工具集合,它允许开发者通过编写代码,自动化地访问网页,解析HTML内容,提取所需信息,常见的Python爬虫库包括BeautifulSoup、Scrapy、Requests等,这些库支持多种网页解析和请求方法,简化了数据抓取过程,适用于各种网络爬虫开发需求。
Python爬虫库:入门到精通的必备工具
用户解答: 你好,我想学习Python爬虫,但是市面上有很多爬虫库,我不知道该从哪个开始学起,你能给我推荐几个好用的Python爬虫库,并简单介绍一下它们的特点吗?
当然可以,Python爬虫库有很多,其中比较常用的有BeautifulSoup、Scrapy、Selenium和requests,下面我会分别介绍这些库的特点和适用场景。

一:BeautifulSoup库
功能简介: BeautifulSoup是一个用于解析HTML和XML文档的库,它将HTML文档转换成一个复杂的树形结构,然后你可以通过简单的Python表达式来导航、搜索和修改树形结构。
适用场景:
- 解析静态网页: BeautifulSoup非常适合解析静态网页,特别是那些结构比较简单的HTML文档。
- 数据提取: 可以快速提取网页中的特定数据,如标题、段落、链接等。
优点:
- 易于使用: 学习曲线平缓,即使是初学者也能快速上手。
- 功能强大: 支持多种解析器,如lxml、html5lib等。
二:Scrapy库
功能简介: Scrapy是一个强大的网络爬虫框架,它提供了一个完整的爬虫解决方案,包括请求发送、数据提取、数据存储等。
适用场景:

- 大规模数据采集: Scrapy适合用于大规模的数据采集任务,如网站爬虫、数据挖掘等。
- 分布式爬虫: 支持分布式爬虫,可以扩展到多台服务器。
优点:
- 高效: 内置了异步请求机制,可以显著提高爬取速度。
- 易于扩展: 提供了丰富的插件和中间件,可以轻松扩展功能。
三:Selenium库
功能简介: Selenium是一个用于Web应用程序测试的工具,但它也可以用来进行爬虫,Selenium可以模拟浏览器行为,如点击、输入、滚动等,从而可以爬取动态加载的内容。
适用场景:
- 动态网页爬虫: 适用于爬取那些需要登录、点击或其他JavaScript动态加载内容的网页。
- 自动化测试: 也可以用于自动化测试Web应用程序。
优点:
- 真实浏览器行为: 可以的用户操作,爬取动态内容。
- 跨浏览器支持: 支持多种浏览器,如Chrome、Firefox等。
四:requests库
功能简介: requests是一个简单易用的HTTP库,它提供了发送HTTP请求、处理响应等功能。
适用场景:
- 基础HTTP请求: 适用于发送GET、POST等HTTP请求,获取网页内容。
- API交互: 也可以用于与RESTful API进行交互。
优点:
- 简单易用: API设计直观,易于上手。
- 功能全面: 支持多种HTTP方法,如GET、POST、PUT、DELETE等。
五:aiohttp库
功能简介: aiohttp是一个基于Python异步编程模型的HTTP客户端和服务器库,它使用异步IO来处理网络请求。
适用场景:
- 高性能爬虫: 适用于需要高性能的爬虫任务,如并发请求。
- 异步Web应用: 也可以用于构建异步Web应用。
优点:
- 异步IO: 使用异步IO,可以同时处理大量并发请求。
- 灵活: 支持多种HTTP协议,如HTTP/1.1、HTTP/2等。
通过以上对Python爬虫库的介绍,相信你已经对它们有了基本的了解,选择合适的爬虫库,可以帮助你更高效地完成爬虫任务,学习爬虫技术不仅仅是掌握这些库,还需要了解网络协议、HTML结构、数据解析等技术,祝你学习愉快!
其他相关扩展阅读资料参考文献:
requests与BeautifulSoup
- requests 是Python中最常用的HTTP请求库,安装简单(
pip install requests),核心功能包括发送GET/POST请求、处理响应头和状态码,适合快速获取网页数据。 - BeautifulSoup 是HTML解析库,核心优势在于将网页内容转化为可操作的树状结构,支持CSS选择器和XPath语法,能高效提取所需标签内容。
- 两者结合是入门级爬虫的标配:requests获取网页内容,BeautifulSoup解析结构,例如通过
response.text提取原始HTML后,用BeautifulSoup(response.text, 'html.parser')生成解析对象。
进阶框架:Scrapy的高效爬取
- Scrapy 是功能强大的异步爬虫框架,核心架构包含引擎、Spider、Item Pipeline和Downloader Middleware,能自动处理请求队列和响应解析。
- 数据提取通过Selector实现,支持XPath和CSS选择器,例如
response.xpath('//div[@class="gjqaerjgeihgjdfbd245-5aff-ca94-619b content"]')可精准定位特定节点,效率远超手动解析。 - 中间件系统是Scrapy的亮点,请求头伪装(如设置User-Agent)和反爬策略(如IP代理)可通过自定义Middleware实现,灵活性高。
动态网页处理:Selenium与Playwright
- Selenium 通过浏览器自动化模拟用户操作,核心优势是支持JavaScript渲染,适合处理动态加载的网页(如AJAX请求或前端框架生成的内容)。
- Playwright 是新兴的自动化工具,对比Selenium,其性能更优,支持多浏览器(Chrome、Firefox、Safari),且内置自动等待功能,降低代码复杂度。
- 抓取需结合浏览器控制:例如用Selenium的
driver.get(url)加载页面后,通过driver.find_element获取动态生成的元素,但需注意性能损耗。
反爬策略应对:User-Agent与请求频率控制
- User-Agent 是最常见的反爬手段,核心原理是模拟不同浏览器标识,例如通过
headers={'User-Agent': 'Mozilla/5.0'}绕过服务器的浏览器检测。 - 请求频率控制需使用
time.sleep()或asyncio模块,核心目的是避免被封IP,例如设置间隔3秒发送请求,模拟人类操作节奏。 - 代理IP池是应对反爬的进阶方案,核心功能是通过随机切换IP地址降低被封风险,例如使用
proxies={'http': 'http://123.45.67.89:8080'}参数配置代理。
数据存储与反反爬:数据持久化与验证码处理
- 数据存储需结合数据库或文件系统,核心方案包括MySQL、MongoDB或CSV文件,例如使用
pymysql连接数据库后,将爬取数据批量插入表中。 - 验证码处理依赖第三方服务或OCR库,核心工具如
pyotp处理TOTP验证码,或使用pytesseract调用Tesseract OCR识别图片验证码。 - 反反爬策略需动态调整,例如通过
random模块随机生成请求头参数,或使用fake_useragent库自动获取随机User-Agent,用户行为。
实战技巧:性能优化与异常处理
- 并发请求需使用
aiohttp或concurrent.futures,核心优势是提升爬虫效率,例如通过asyncio.gather()同时发起多个异步请求,减少等待时间。 - 异常处理需覆盖网络错误和超时,核心代码如
try-except块捕获requests.exceptions.RequestException,确保程序稳定性。 - 日志记录通过
logging模块实现,核心功能是跟踪爬虫进度和错误信息,例如设置日志级别为DEBUG,记录请求状态码和响应内容,便于调试和分析。
合规性与伦理:遵守robots.txt与数据使用规范
- robots.txt 是网站管理员定义爬虫规则的文件,核心要求是禁止抓取受限路径,例如通过
robots_parser库解析robots.txt,避免法律风险。 - 数据使用规范需遵循GDPR等隐私政策,核心原则是仅抓取公开数据且不用于非法用途,例如通过
if not robots_parser.can_fetch(user_agent, url):判断是否合法。 - 爬虫伦理强调尊重网站负载,核心策略是设置请求频率上限(如每分钟10次),或使用分布式爬虫框架(如Scrapy-Redis),平衡效率与公平。
未来趋势:AI辅助与云服务集成
- AI辅助解析通过深度学习模型(如TensorFlow)实现,核心应用场景是识别复杂网页结构或处理模糊内容,例如训练模型自动提取表格数据。
- 云服务集成需使用AWS、阿里云等平台,核心优势是分布式爬取和自动扩展,例如通过AWS Lambda部署爬虫任务,降低硬件成本。
- 自动化运维依赖监控工具(如Prometheus),核心功能是实时跟踪爬虫状态和资源占用,例如设置警报阈值避免服务崩溃,提升长期稳定性。
选型建议:根据需求匹配工具
- 简单静态页面优先选择requests+BeautifulSoup,开发成本低,适合快速验证数据抓取逻辑。
- 复杂动态页面需使用Selenium或Playwright,性能开销大,但能处理JavaScript渲染内容,例如抓取需要登录的网页。
- 大规模数据采集推荐Scrapy框架,支持分布式部署,例如通过
scrapy crawl命令启动集群任务,适合企业级应用。
安全与效率:避免被封与资源优化
- 避免被封需动态调整请求参数,核心方法包括随机User-Agent、IP代理和请求间隔,例如通过
random.choice(user_agents)生成随机标识。 - 资源优化需关闭不必要的功能,核心操作如禁用SSL验证(
verify=False)或压缩响应内容(response.text),减少内存占用。 - 安全性保障需使用HTTPS协议和数据加密,核心工具如
requests.get(url, verify=True)确保通信安全,或通过cryptography库加密敏感信息,防止数据泄露。
通过以上的深入解析,可以看出Python爬虫库的选择与使用需结合具体场景,从基础到进阶逐步构建。合理规划爬虫策略,不仅能提升数据抓取效率,还能规避法律和伦理风险,确保技术应用的可持续性。
“python爬虫库,Python爬虫实战,常用库深度解析” 的相关文章
c语言编译器电脑,电脑上安装C语言编译器指南
C语言编译器是一种用于将C语言源代码转换为机器代码的程序,它运行在电脑上,可以将开发者编写的C语言程序编译成可执行文件,从而在计算机上运行,C语言编译器是C语言开发环境的核心部分,支持语法检查、错误诊断和代码优化等功能,对于C语言程序员来说是必不可少的工具。用户提问:大家好,我最近买了一台新的电脑,...
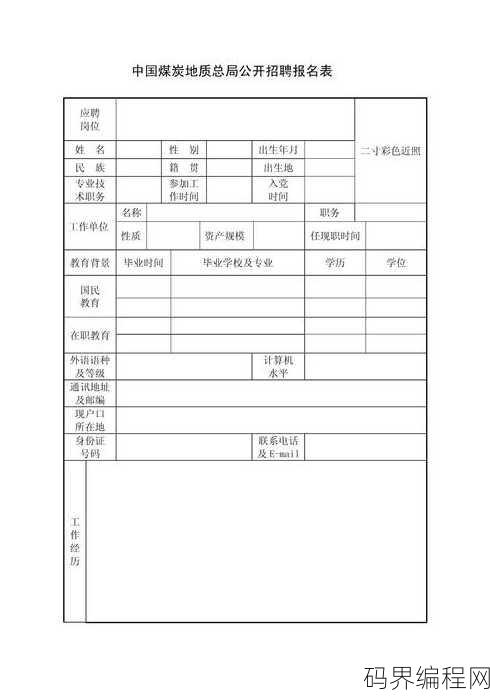
表单html代码报名表,HTML表单代码,报名表制作指南
提供了一份HTML代码示例,用于创建报名表,代码包括表单标签、输入字段、按钮等元素,旨在收集用户的基本信息,如姓名、联系方式等,摘要如下:提供HTML代码示例,展示如何创建一个简单的报名表,包含姓名、联系方式等输入字段及提交按钮。表单HTML代码报名表:轻松实现信息收集的利器 用户解答: 嗨,大...
python下载完成后怎么进入界面,Python下载后如何启动界面操作指南
在Python下载并安装完成后,通常可以通过以下步骤进入其界面或命令行:,1. 打开文件资源管理器或启动菜单。,2. 搜索“Python”或“IDLE”(如果安装了IDLE作为交互式解释器)。,3. 点击相应的Python应用程序或IDLE图标。,4. 程序启动后,你将看到Python的命令行界面,...

html css js网页模板,一站式HTML/CSS/JS网页模板制作指南
本网页模板基于HTML、CSS和JavaScript技术构建,旨在提供灵活且响应式的网页设计,它包含简洁的HTML结构,便于快速搭建网页框架;丰富的CSS样式,支持定制化外观;以及交互性强的JavaScript脚本,增强用户互动体验,该模板适用于多种设备和屏幕尺寸,支持响应式布局,可轻松实现个性化设...

mysql怎么建立数据库和表,MySQL数据库与表的创建指南
MySQL建立数据库和表的方法如下:使用CREATE DATABASE语句创建数据库,指定数据库名称;使用USE语句选择该数据库;使用CREATE TABLE语句创建表,指定表名和列定义,创建名为"students"的数据库,并创建一个名为"user"的表,包含"name"和"age"两列,代码如下...
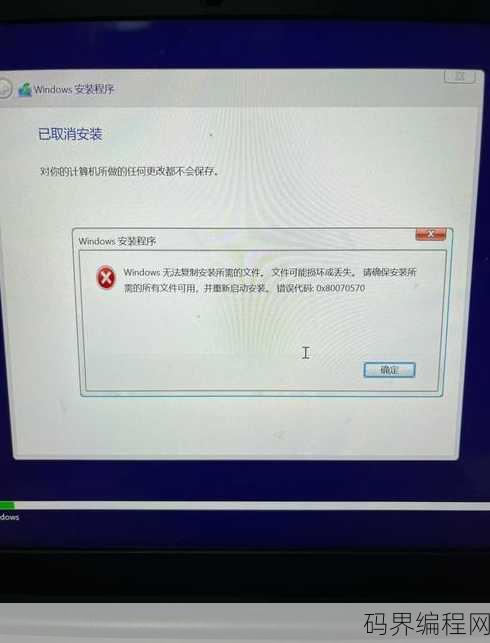
安全控件怎么安装不了,安装安全控件遇到困难?解决方法大揭秘!
在尝试安装安全控件时遇到问题,可能的原因包括:控件文件损坏、系统权限不足、浏览器设置限制、与现有软件冲突或控件本身存在bug,解决方法包括:检查控件文件完整性、以管理员身份运行安装程序、调整浏览器安全设置、关闭可能冲突的软件,或尝试更新控件至最新版本,如问题依旧,建议查阅控件官方文档或寻求技术支持。...
- 最新发布
-
1分钟前
8分钟前

16分钟前

22分钟前

30分钟前
- 热门阅读
-

903 浏览学习方法

242 浏览源码资料

224 浏览学习方法

219 浏览数据库

213 浏览编程语言